 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Adversarial Training Using Diffusion Learning
Mar 03, 2023



This work focuses on adversarial learning over graphs. We propose a general adversarial training framework for multi-agent systems using diffusion learning. We analyze the convergence properties of the proposed scheme for convex optimization problems, and illustrate its enhanced robustness to adversarial attacks.
Policy Evaluation in Decentralized POMDPs with Belief Sharing
Feb 08, 2023



Most works on multi-agent reinforcement learning focus on scenarios where the state of the environment is fully observable. In this work, we consider a cooperative policy evaluation task in which agents are not assumed to observe the environment state directly. Instead, agents can only have access to noisy observations and to belief vectors. It is well-known that finding global posterior distributions under multi-agent settings is generally NP-hard. As a remedy, we propose a fully decentralized belief forming strategy that relies on individual updates and on localized interactions over a communication network. In addition to the exchange of the beliefs, agents exploit the communication network by exchanging value function parameter estimates as well. We analytically show that the proposed strategy allows information to diffuse over the network, which in turn allows the agents' parameters to have a bounded difference with a centralized baseline. A multi-sensor target tracking application is considered in the simulations.
Memory-Aware Social Learning under Partial Information Sharing
Jan 25, 2023

This work examines a social learning problem, where dispersed agents connected through a network topology interact locally to form their opinions (beliefs) as regards certain hypotheses of interest. These opinions evolve over time, since the agents collect observations from the environment, and update their current beliefs by accounting for: their past beliefs, the innovation contained in the new data, and the beliefs received from the neighbors. The distinguishing feature of the present work is that agents are constrained to share opinions regarding only a single hypothesis. We devise a novel learning strategy where each agent forms a valid belief by completing the partial beliefs received from its neighbors. This completion is performed by exploiting the knowledge accumulated in the past beliefs, thanks to a principled memory-aware rule inspired by a Bayesian criterion. The analysis allows us to characterize the role of memory in social learning under partial information sharing, revealing novel and nontrivial learning dynamics. Surprisingly, we establish that the standard classification rule based on selecting the maximum belief is not optimal under partial information sharing, while there exists a consistent threshold-based decision rule that allows each agent to classify correctly the hypothesis of interest. We also show that the proposed strategy outperforms previously considered schemes, highlighting that the introduction of memory in the social learning algorithm is critical to overcome the limitations arising from sharing partial information.
Enforcing Privacy in Distributed Learning with Performance Guarantees
Jan 16, 2023



We study the privatization of distributed learning and optimization strategies. We focus on differential privacy schemes and study their effect on performance. We show that the popular additive random perturbation scheme degrades performance because it is not well-tuned to the graph structure. For this reason, we exploit two alternative graph-homomorphic constructions and show that they improve performance while guaranteeing privacy. Moreover, contrary to most earlier studies, the gradient of the risks is not assumed to be bounded (a condition that rarely holds in practice; e.g., quadratic risk). We avoid this condition and still devise a differentially private scheme with high probability. We examine optimization and learning scenarios and illustrate the theoretical findings through simulations.
Distributed Bayesian Learning of Dynamic States
Dec 05, 2022



This work studies networked agents cooperating to track a dynamical state of nature under partial information. The proposed algorithm is a distributed Bayesian filtering algorithm for finite-state hidden Markov models (HMMs). It can be used for sequential state estimation tasks, as well as for modeling opinion formation over social networks under dynamic environments. We show that the disagreement with the optimal centralized solution is asymptotically bounded for the class of geometrically ergodic state transition models, which includes rapidly changing models. We also derive recursions for calculating the probability of error and establish convergence under Gaussian observation models. Simulations are provided to illustrate the theory and to compare against alternative approaches.
Discovering Influencers in Opinion Formation over Social Graphs
Nov 23, 2022



The adaptive social learning paradigm helps model how networked agents are able to form opinions on a state of nature and track its drifts in a changing environment. In this framework, the agents repeatedly update their beliefs based on private observations and exchange the beliefs with their neighbors. In this work, it is shown how the sequence of publicly exchanged beliefs over time allows users to discover rich information about the underlying network topology and about the flow of information over graph. In particular, it is shown that it is possible (i) to identify the influence of each individual agent to the objective of truth learning, (ii) to discover how well informed each agent is, (iii) to quantify the pairwise influences between agents, and (iv) to learn the underlying network topology. The algorithm derived herein is also able to work under non-stationary environments where either the true state of nature or the network topology are allowed to drift over time. We apply the proposed algorithm to different subnetworks of Twitter users, and identify the most influential and central agents merely by using their public tweets (posts).
Local Graph-homomorphic Processing for Privatized Distributed Systems
Oct 26, 2022We study the generation of dependent random numbers in a distributed fashion in order to enable privatized distributed learning by networked agents. We propose a method that we refer to as local graph-homomorphic processing; it relies on the construction of particular noises over the edges to ensure a certain level of differential privacy. We show that the added noise does not affect the performance of the learned model. This is a significant improvement to previous works on differential privacy for distributed algorithms, where the noise was added in a less structured manner without respecting the graph topology and has often led to performance deterioration. We illustrate the theoretical results by considering a linear regression problem over a network of agents.
Networked Signal and Information Processing
Oct 25, 2022The article reviews significant advances in networked signal and information processing, which have enabled in the last 25 years extending decision making and inference, optimization, control, and learning to the increasingly ubiquitous environments of distributed agents. As these interacting agents cooperate, new collective behaviors emerge from local decisions and actions. Moreover, and significantly, theory and applications show that networked agents, through cooperation and sharing, are able to match the performance of cloud or federated solutions, while preserving privacy, increasing resilience, and saving resources.
Quantization for decentralized learning under subspace constraints
Sep 16, 2022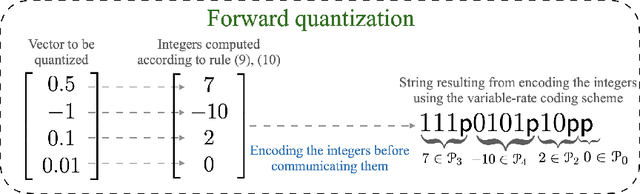
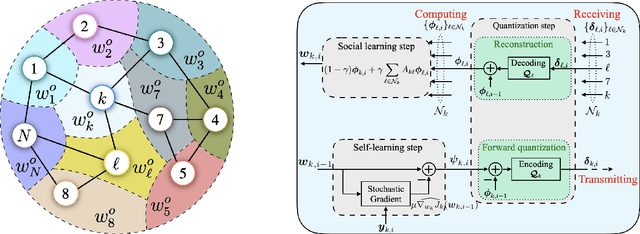
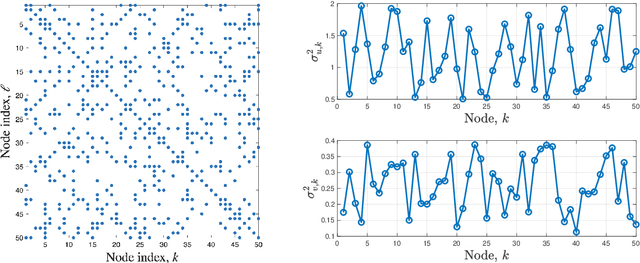
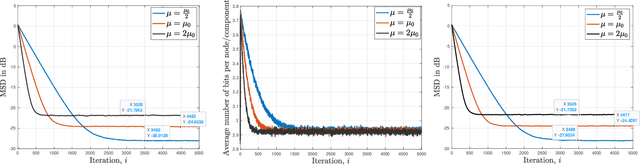
In this paper, we consider decentralized optimization problems where agents have individual cost functions to minimize subject to subspace constraints that require the minimizers across the network to lie in low-dimensional subspaces. This constrained formulation includes consensus or single-task optimization as special cases, and allows for more general task relatedness models such as multitask smoothness and coupled optimization. In order to cope with communication constraints, we propose and study an adaptive decentralized strategy where the agents employ differential randomized quantizers to compress their estimates before communicating with their neighbors. The analysis shows that, under some general conditions on the quantization noise, and for sufficiently small step-sizes $\mu$, the strategy is stable both in terms of mean-square error and average bit rate: by reducing $\mu$, it is possible to keep the estimation errors small (on the order of $\mu$) without increasing indefinitely the bit rate as $\mu\rightarrow 0$. Simulations illustrate the theoretical findings and the effectiveness of the proposed approach, revealing that decentralized learning is achievable at the expense of only a few bits.
A Fundamental Limit of Distributed Hypothesis Testing Under Memoryless Quantization
Jun 24, 2022
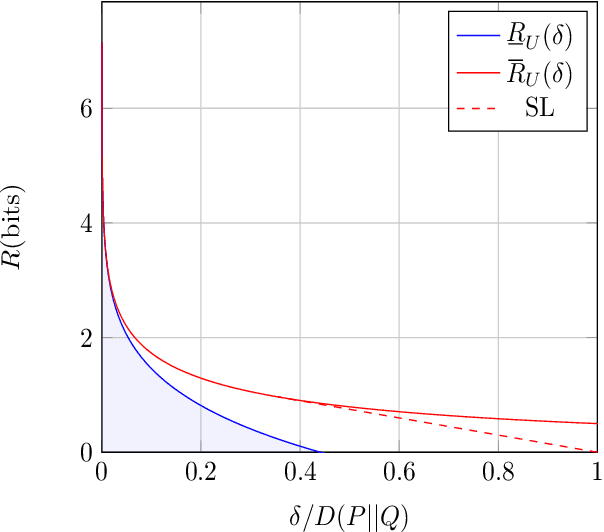

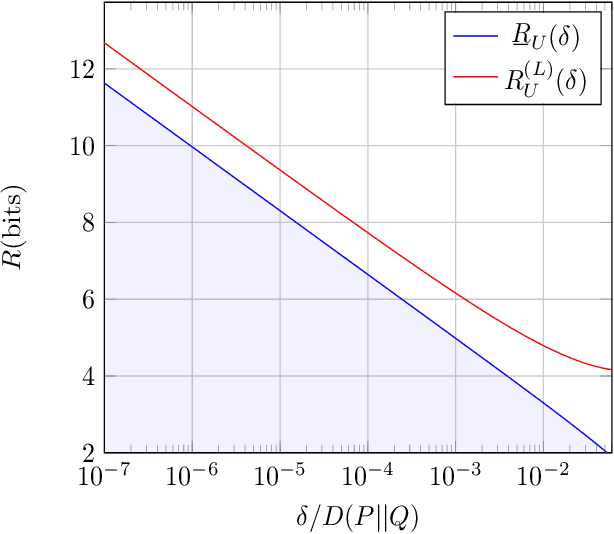
We study a distributed hypothesis testing setup where peripheral nodes send quantized data to the fusion center in a memoryless fashion. The \emph{expected} number of bits sent by each node under the null hypothesis is kept limited. We characterize the optimal decay rate of the mis-detection (type-II error) probability provided that false alarms (type-I error) are rare, and study the tradeoff between the communication rate and maximal type-II error decay rate. We resort to rate-distortion methods to provide upper bounds to the tradeoff curve and show that at high rates lattice quantization achieves near-optimal performance. We also characterize the tradeoff for the case where nodes are allowed to record and quantize a fixed number of samples. Moreover, under sum-rate constraints, we show that an upper bound to the tradeoff curve is obtained with a water-filling solution.