 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgev-SVR Polynomial Kernel for Predicting the Defect Density in New Software Projects
Dec 15, 2018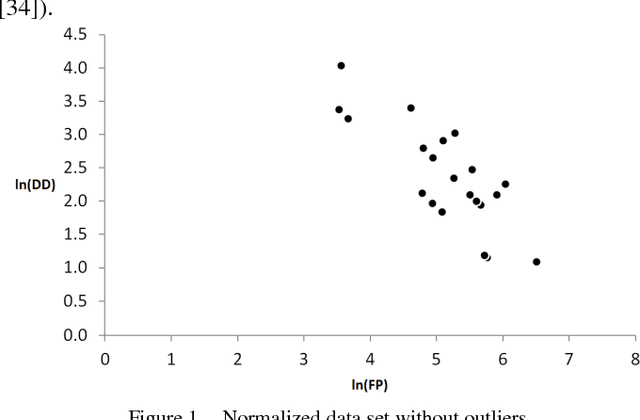
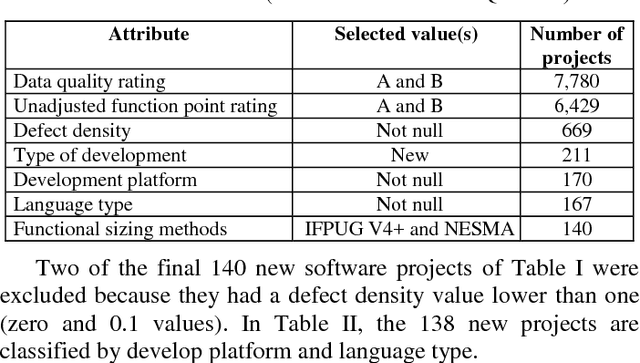
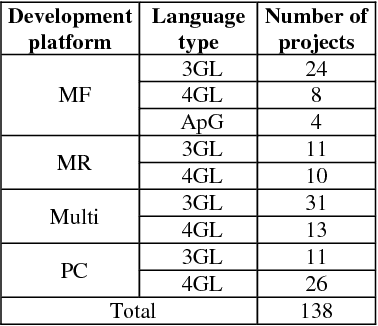
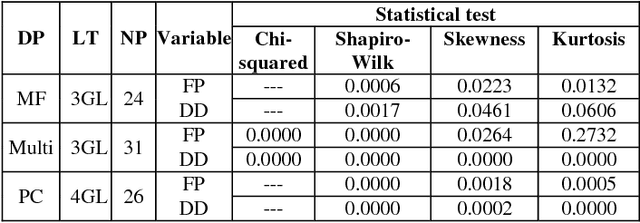
An important product measure to determine the effectiveness of software processes is the defect density (DD). In this study, we propose the application of support vector regression (SVR) to predict the DD of new software projects obtained from the International Software Benchmarking Standards Group (ISBSG) Release 2018 data set. Two types of SVR (e-SVR and v-SVR) were applied to train and test these projects. Each SVR used four types of kernels. The prediction accuracy of each SVR was compared to that of a statistical regression (i.e., a simple linear regression, SLR). Statistical significance test showed that v-SVR with polynomial kernel was better than that of SLR when new software projects were developed on mainframes and coded in programming languages of third generation
Machine Learning Classifications of Coronary Artery Disease
Nov 26, 2018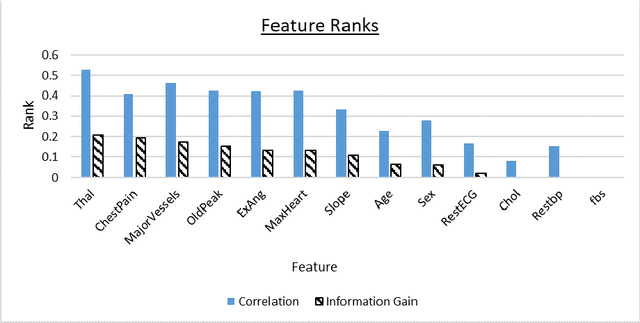

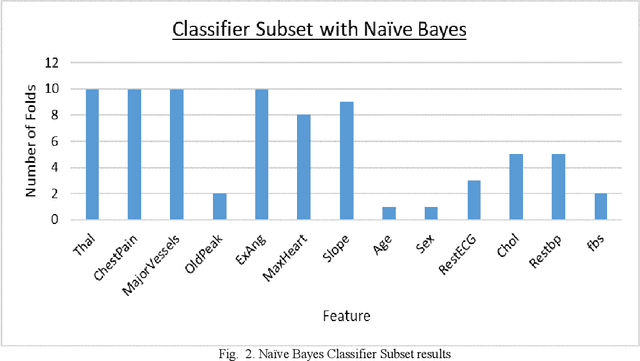
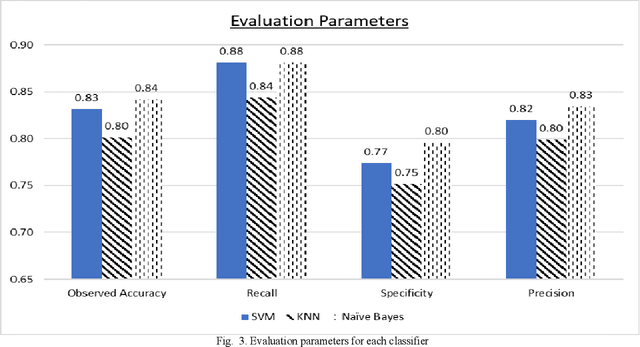
Coronary Artery Disease (CAD) is one of the leading causes of death worldwide, and so it is very important to correctly diagnose patients with the disease. For medical diagnosis, machine learning is a useful tool, however features and algorithms must be carefully selected to get accurate classification. To this effect, three feature selection methods have been used on 13 input features from the Cleveland dataset with 297 entries, and 7 were selected. The selected features were used to train three different classifiers, which are SVM, Na\"ive Bayes and KNN using 10-fold cross-validation. The resulting models evaluated using Accuracy, Recall, Specificity and Precision. It is found that the Na\"ive Bayes classifier performs the best on this dataset and features, outperforming or matching SVM and KNN in all the four evaluation parameters used and achieving an accuracy of 84%.
Three-Stage Speaker Verification Architecture in Emotional Talking Environments
Sep 03, 2018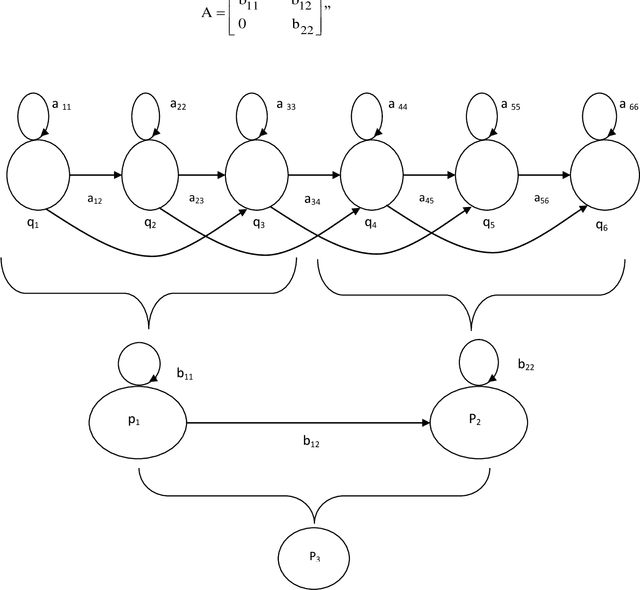
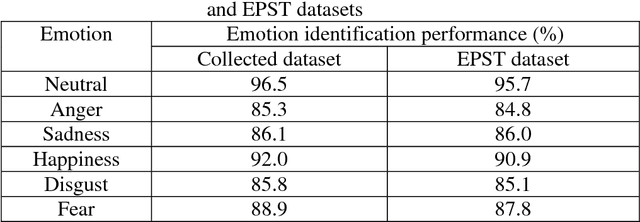
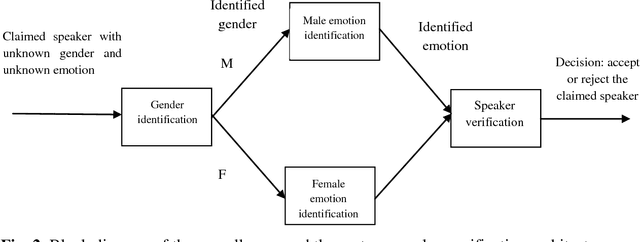
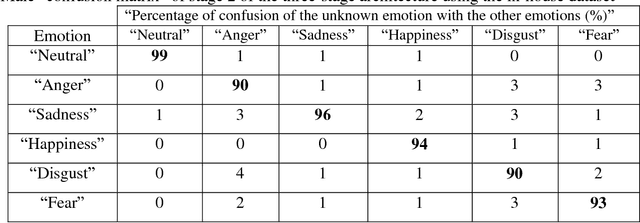
Speaker verification performance in neutral talking environment is usually high, while it is sharply decreased in emotional talking environments. This performance degradation in emotional environments is due to the problem of mismatch between training in neutral environment while testing in emotional environments. In this work, a three-stage speaker verification architecture has been proposed to enhance speaker verification performance in emotional environments. This architecture is comprised of three cascaded stages: gender identification stage followed by an emotion identification stage followed by a speaker verification stage. The proposed framework has been evaluated on two distinct and independent emotional speech datasets: in-house dataset and Emotional Prosody Speech and Transcripts dataset. Our results show that speaker verification based on both gender information and emotion information is superior to each of speaker verification based on gender information only, emotion information only, and neither gender information nor emotion information. The attained average speaker verification performance based on the proposed framework is very alike to that attained in subjective assessment by human listeners.
* 18 pages. arXiv admin note: substantial text overlap with arXiv:1804.00155, arXiv:1707.00137
Fuzzy Model Tree For Early Effort Estimation
Mar 11, 2017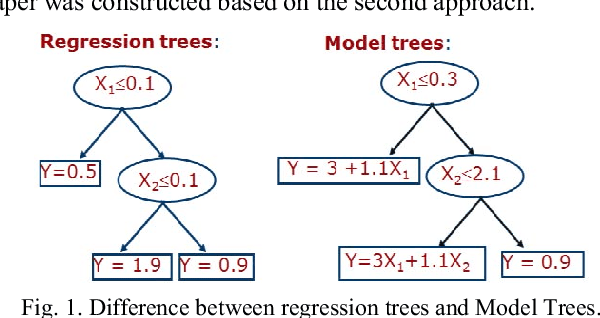
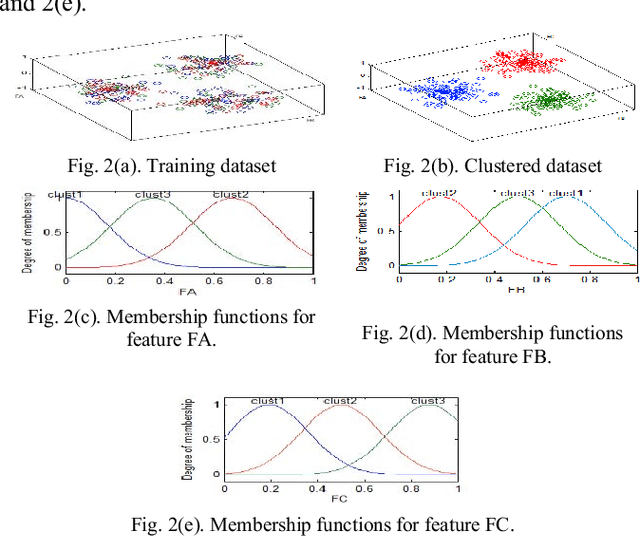
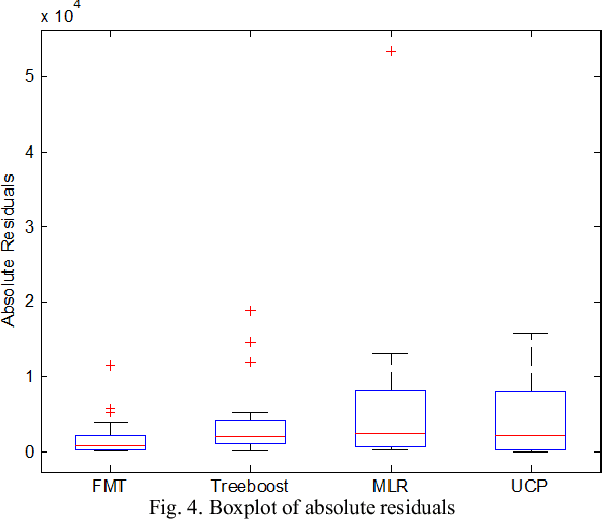
Use Case Points (UCP) is a well-known method to estimate the project size, based on Use Case diagram, at early phases of software development. Although the Use Case diagram is widely accepted as a de-facto model for analyzing object oriented software requirements over the world, UCP method did not take sufficient amount of attention because, as yet, there is no consensus on how to produce software effort from UCP. This paper aims to study the potential of using Fuzzy Model Tree to derive effort estimates based on UCP size measure using a dataset collected for that purpose. The proposed approach has been validated against Treeboost model, Multiple Linear Regression and classical effort estimation based on the UCP model. The obtained results are promising and show better performance than those obtained by classical UCP, Multiple Linear Regression and slightly better than those obtained by Tree boost model.
Enhancing Use Case Points Estimation Method Using Soft Computing Techniques
Dec 04, 2016


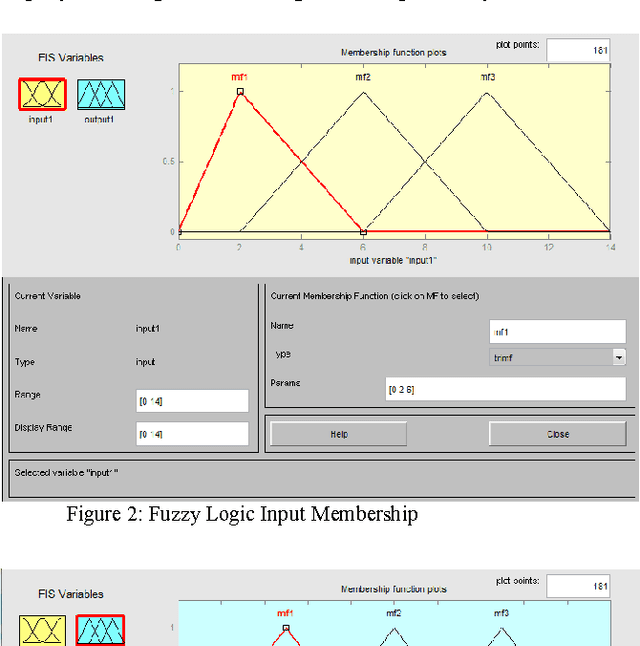
Software estimation is a crucial task in software engineering. Software estimation encompasses cost, effort, schedule, and size. The importance of software estimation becomes critical in the early stages of the software life cycle when the details of software have not been revealed yet. Several commercial and non-commercial tools exist to estimate software in the early stages. Most software effort estimation methods require software size as one of the important metric inputs and consequently, software size estimation in the early stages becomes essential. One of the approaches that has been used for about two decades in the early size and effort estimation is called use case points. Use case points method relies on the use case diagram to estimate the size and effort of software projects. Although the use case points method has been widely used, it has some limitations that might adversely affect the accuracy of estimation. This paper presents some techniques using fuzzy logic and neural networks to improve the accuracy of the use case points method. Results showed that an improvement up to 22% can be obtained using the proposed approach.
Pareto Efficient Multi Objective Optimization for Local Tuning of Analogy Based Estimation
Nov 29, 2016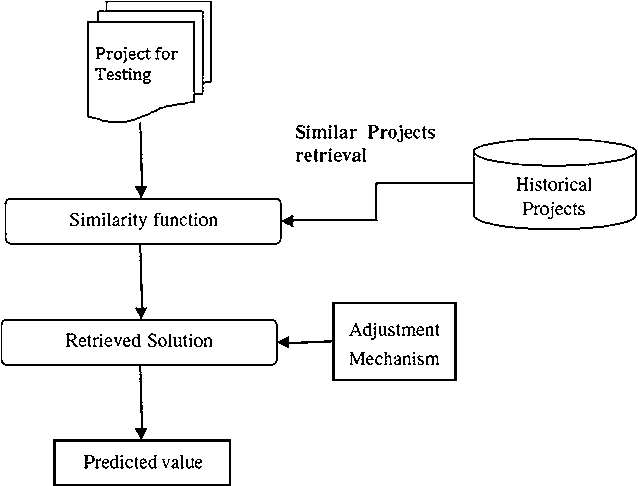

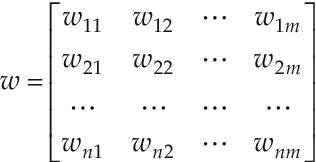
Analogy Based Effort Estimation (ABE) is one of the prominent methods for software effort estimation. The fundamental concept of ABE is closer to the mentality of expert estimation but with an automated procedure in which the final estimate is generated by reusing similar historical projects. The main key issue when using ABE is how to adapt the effort of the retrieved nearest neighbors. The adaptation process is an essential part of ABE to generate more successful accurate estimation based on tuning the selected raw solutions, using some adaptation strategy. In this study we show that there are three interrelated decision variables that have great impact on the success of adaptation method: (1) number of nearest analogies (k), (2) optimum feature set needed for adaptation, and (3) adaptation weights. To find the right decision regarding these variables, one need to study all possible combinations and evaluate them individually to select the one that can improve all prediction evaluation measures. The existing evaluation measures usually behave differently, presenting sometimes opposite trends in evaluating prediction methods. This means that changing one decision variable could improve one evaluation measure while it is decreasing the others. Therefore, the main theme of this research is how to come up with best decision variables that improve adaptation strategy and thus, the overall evaluation measures without degrading the others. The impact of these decisions together has not been investigated before, therefore we propose to view the building of adaptation procedure as a multi-objective optimization problem. The Particle Swarm Optimization Algorithm (PSO) is utilized to find the optimum solutions for such decision variables based on optimizing multiple evaluation measures
A Hybrid Intelligent Model for Software Cost Estimation
Dec 01, 2015
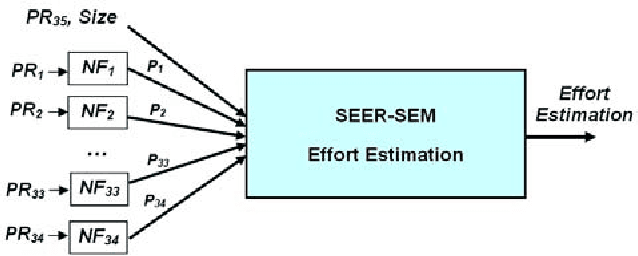
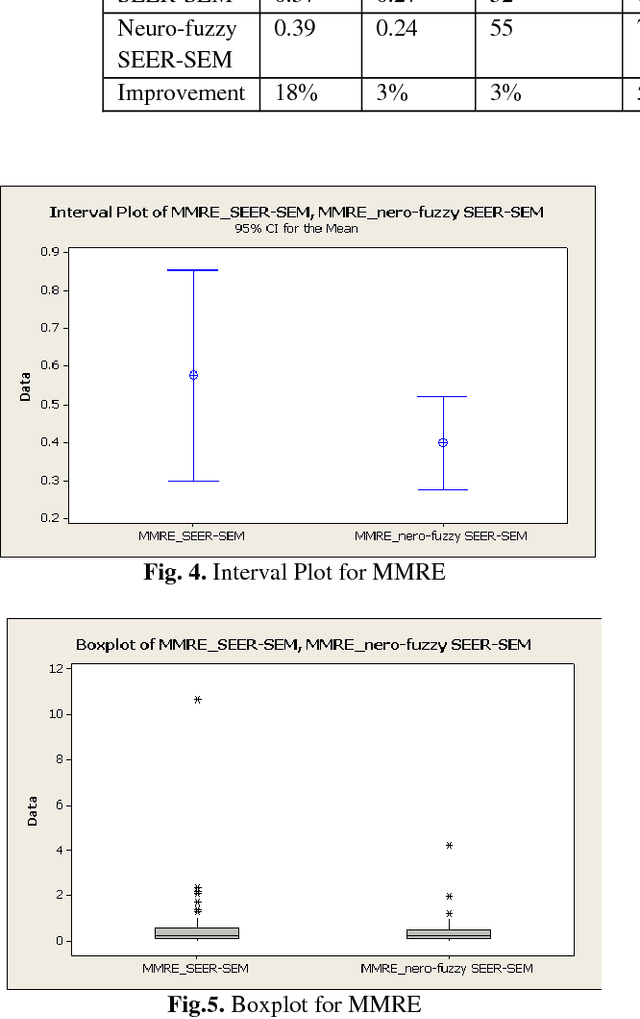
Accurate software development effort estimation is critical to the success of software projects. Although many techniques and algorithmic models have been developed and implemented by practitioners, accurate software development effort prediction is still a challenging endeavor in the field of software engineering, especially in handling uncertain and imprecise inputs and collinear characteristics. In this paper, a hybrid in-telligent model combining a neural network model integrated with fuzzy model (neuro-fuzzy model) has been used to improve the accuracy of estimating software cost. The performance of the proposed model is assessed by designing and conducting evaluation with published project and industrial data. Results have shown that the proposed model demonstrates the ability of improving the estimation accuracy by 18% based on the Mean Magnitude of Relative Error (MMRE) criterion.
A Comparison Between Decision Trees and Decision Tree Forest Models for Software Development Effort Estimation
Aug 28, 2015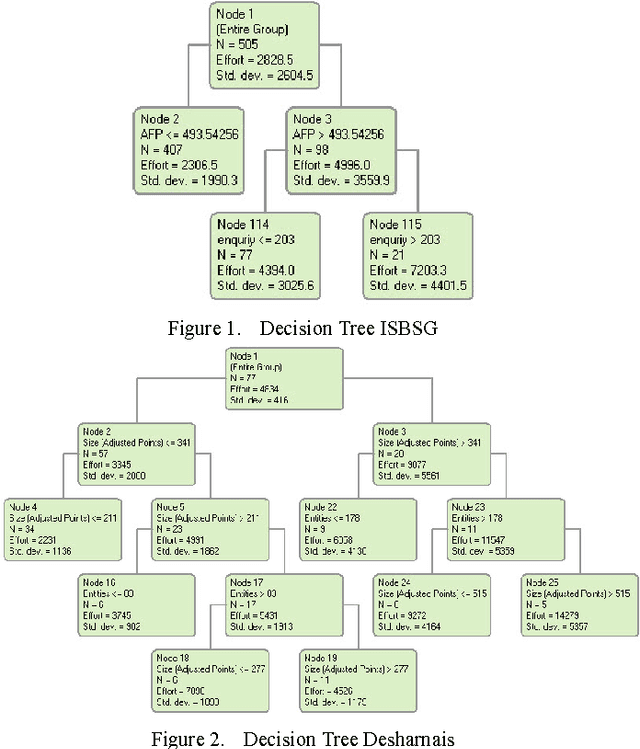
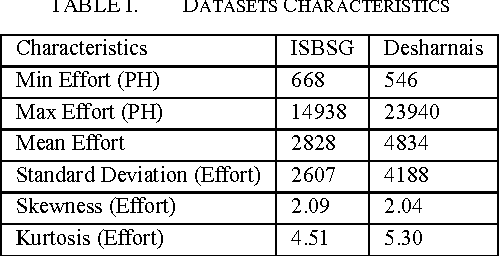
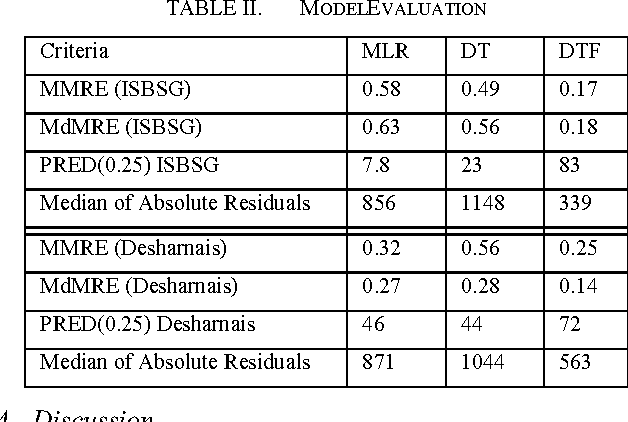
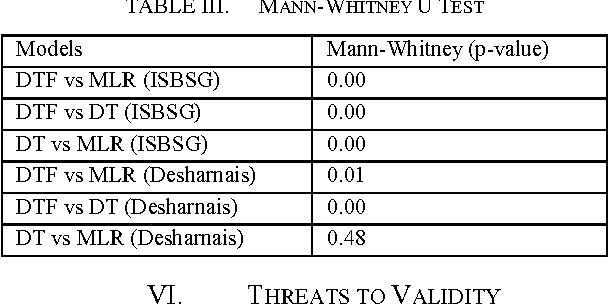
Accurate software effort estimation has been a challenge for many software practitioners and project managers. Underestimation leads to disruption in the projects estimated cost and delivery. On the other hand, overestimation causes outbidding and financial losses in business. Many software estimation models exist; however, none have been proven to be the best in all situations. In this paper, a decision tree forest (DTF) model is compared to a traditional decision tree (DT) model, as well as a multiple linear regression model (MLR). The evaluation was conducted using ISBSG and Desharnais industrial datasets. Results show that the DTF model is competitive and can be used as an alternative in software effort prediction.