 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical evaluation of shallow and deep learning classifiers for Arabic sentiment analysis
Dec 01, 2021
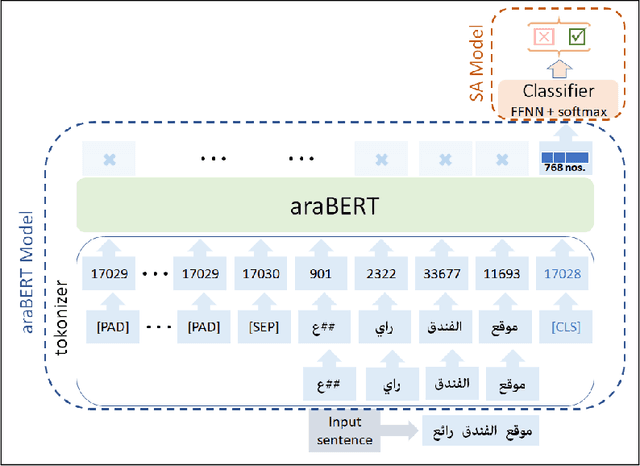
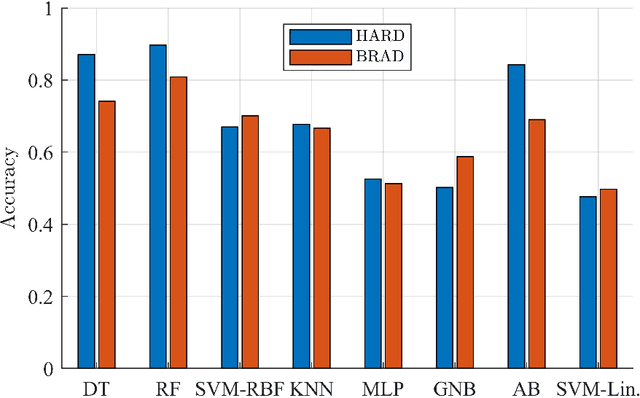
This work presents a detailed comparison of the performance of deep learning models such as convolutional neural networks (CNN), long short-term memory (LSTM), gated recurrent units (GRU), their hybrids, and a selection of shallow learning classifiers for sentiment analysis of Arabic reviews. Additionally, the comparison includes state-of-the-art models such as the transformer architecture and the araBERT pre-trained model. The datasets used in this study are multi-dialect Arabic hotel and book review datasets, which are some of the largest publicly available datasets for Arabic reviews. Results showed deep learning outperforming shallow learning for binary and multi-label classification, in contrast with the results of similar work reported in the literature. This discrepancy in outcome was caused by dataset size as we found it to be proportional to the performance of deep learning models. The performance of deep and shallow learning techniques was analyzed in terms of accuracy and F1 score. The best performing shallow learning technique was Random Forest followed by Decision Tree, and AdaBoost. The deep learning models performed similarly using a default embedding layer, while the transformer model performed best when augmented with araBERT.
CASA-Based Speaker Identification Using Cascaded GMM-CNN Classifier in Noisy and Emotional Talking Conditions
Feb 11, 2021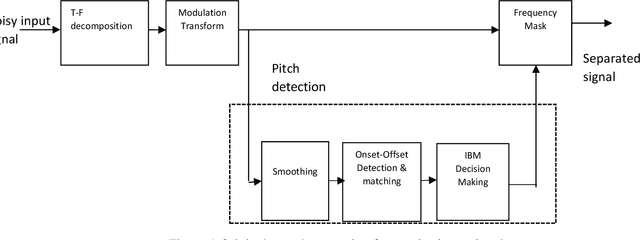
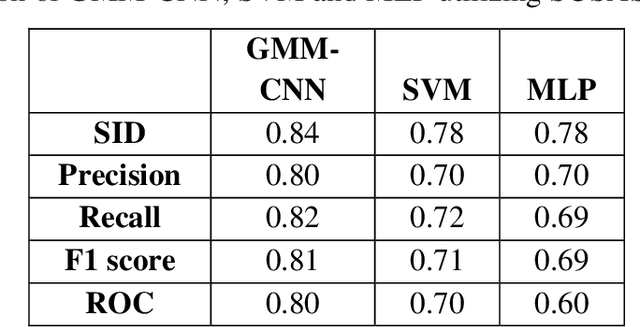
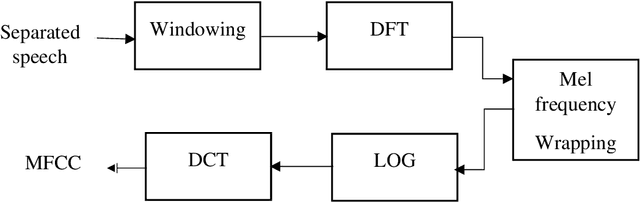
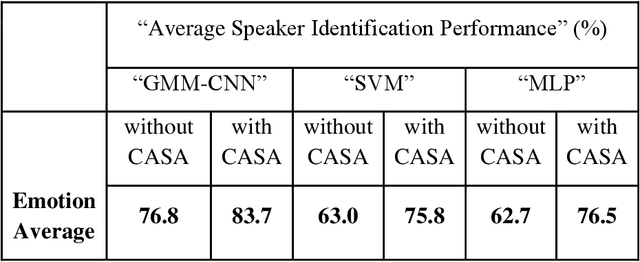
This work aims at intensifying text-independent speaker identification performance in real application situations such as noisy and emotional talking conditions. This is achieved by incorporating two different modules: a Computational Auditory Scene Analysis CASA based pre-processing module for noise reduction and cascaded Gaussian Mixture Model Convolutional Neural Network GMM-CNN classifier for speaker identification followed by emotion recognition. This research proposes and evaluates a novel algorithm to improve the accuracy of speaker identification in emotional and highly-noise susceptible conditions. Experiments demonstrate that the proposed model yields promising results in comparison with other classifiers when Speech Under Simulated and Actual Stress SUSAS database, Emirati Speech Database ESD, the Ryerson Audio-Visual Database of Emotional Speech and Song RAVDESS database and the Fluent Speech Commands database are used in a noisy environment.
* Published in Applied Soft Computing journal
Machine Learning Towards Intelligent Systems: Applications, Challenges, and Opportunities
Jan 11, 2021
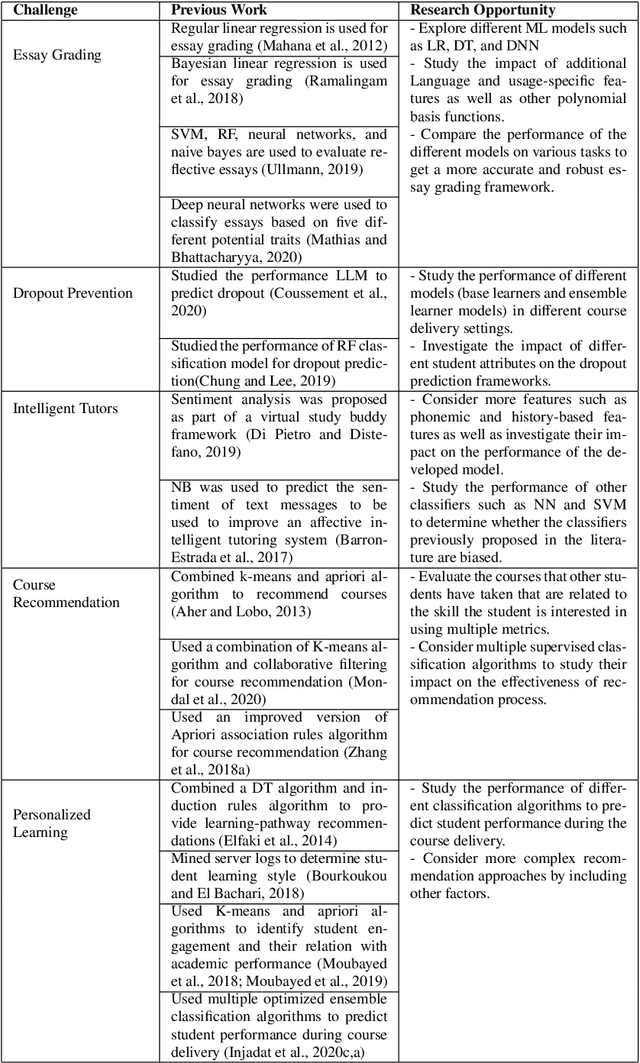
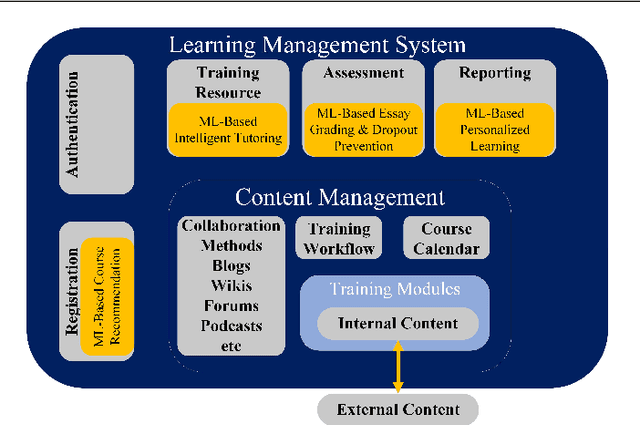
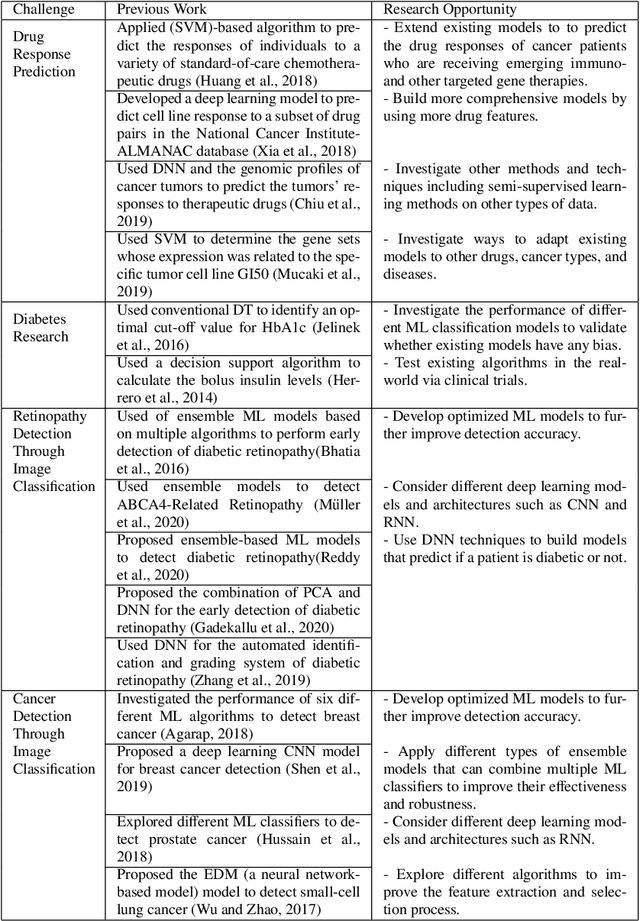
The emergence and continued reliance on the Internet and related technologies has resulted in the generation of large amounts of data that can be made available for analyses. However, humans do not possess the cognitive capabilities to understand such large amounts of data. Machine learning (ML) provides a mechanism for humans to process large amounts of data, gain insights about the behavior of the data, and make more informed decision based on the resulting analysis. ML has applications in various fields. This review focuses on some of the fields and applications such as education, healthcare, network security, banking and finance, and social media. Within these fields, there are multiple unique challenges that exist. However, ML can provide solutions to these challenges, as well as create further research opportunities. Accordingly, this work surveys some of the challenges facing the aforementioned fields and presents some of the previous literature works that tackled them. Moreover, it suggests several research opportunities that benefit from the use of ML to address these challenges.
Multi-Stage Optimized Machine Learning Framework for Network Intrusion Detection
Aug 09, 2020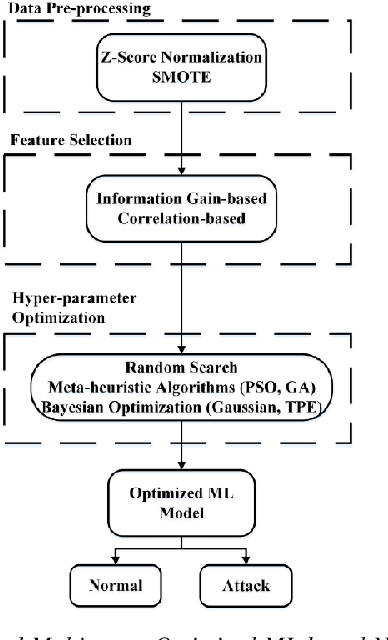
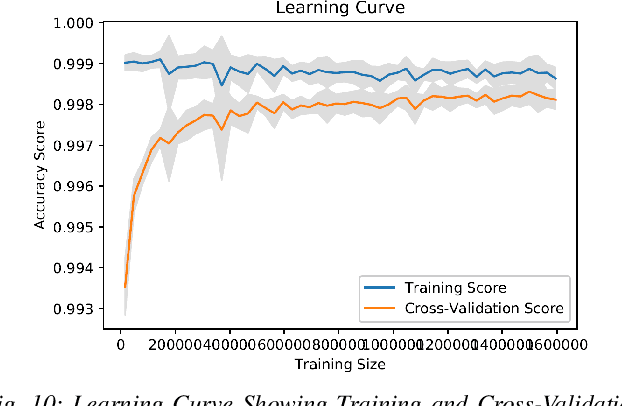
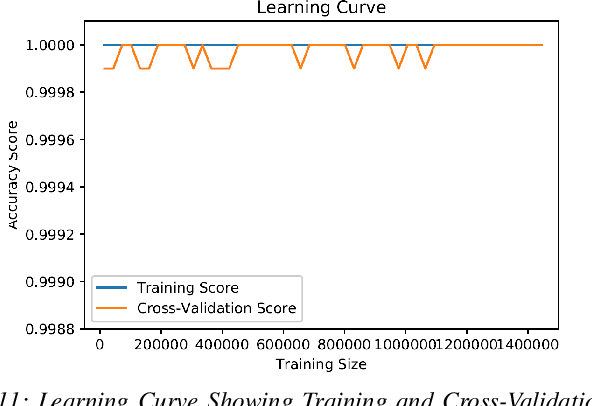
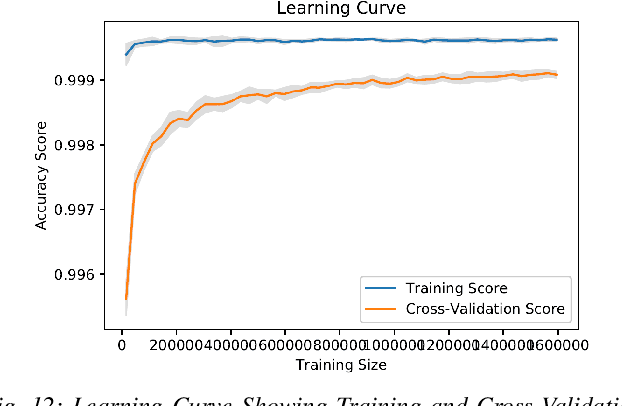
Cyber-security garnered significant attention due to the increased dependency of individuals and organizations on the Internet and their concern about the security and privacy of their online activities. Several previous machine learning (ML)-based network intrusion detection systems (NIDSs) have been developed to protect against malicious online behavior. This paper proposes a novel multi-stage optimized ML-based NIDS framework that reduces computational complexity while maintaining its detection performance. This work studies the impact of oversampling techniques on the models' training sample size and determines the minimal suitable training sample size. Furthermore, it compares between two feature selection techniques, information gain and correlation-based, and explores their effect on detection performance and time complexity. Moreover, different ML hyper-parameter optimization techniques are investigated to enhance the NIDS's performance. The performance of the proposed framework is evaluated using two recent intrusion detection datasets, the CICIDS 2017 and the UNSW-NB 2015 datasets. Experimental results show that the proposed model significantly reduces the required training sample size (up to 74%) and feature set size (up to 50%). Moreover, the model performance is enhanced with hyper-parameter optimization with detection accuracies over 99% for both datasets, outperforming recent literature works by 1-2% higher accuracy and 1-2% lower false alarm rate.
* 14 Pages, 13 Figures, 4 tables, Published IEEE Transactions on Network and Service Management ( Early Access )
Bayesian Optimization with Machine Learning Algorithms Towards Anomaly Detection
Aug 05, 2020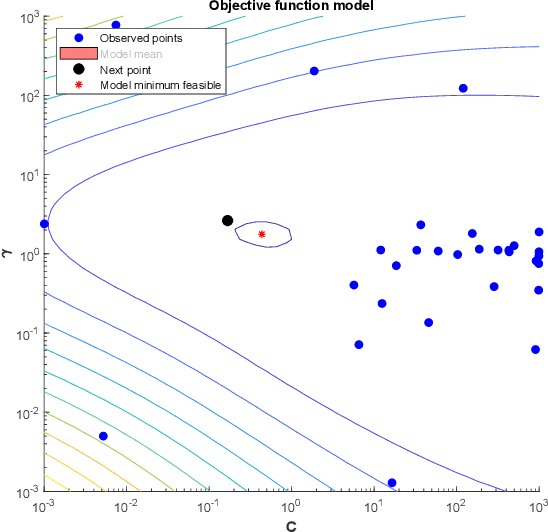
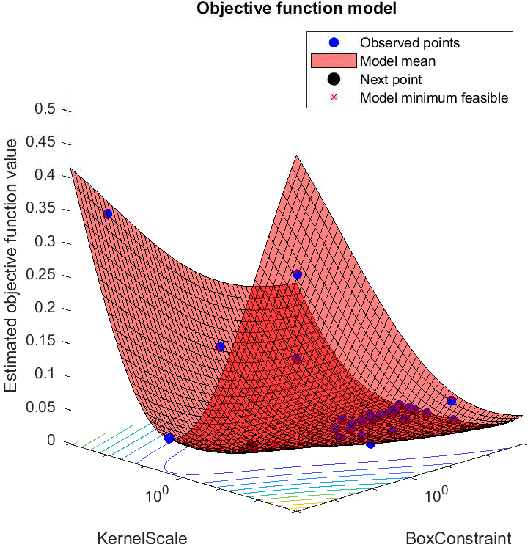
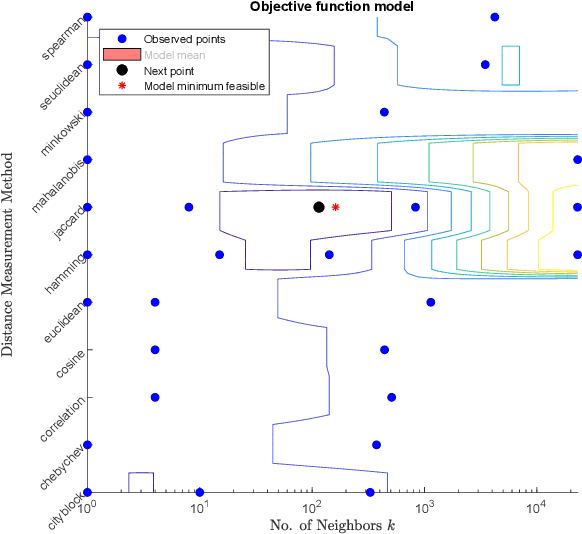
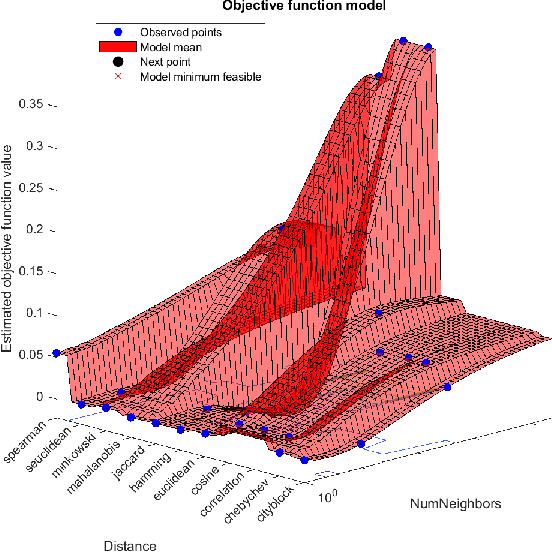
Network attacks have been very prevalent as their rate is growing tremendously. Both organization and individuals are now concerned about their confidentiality, integrity and availability of their critical information which are often impacted by network attacks. To that end, several previous machine learning-based intrusion detection methods have been developed to secure network infrastructure from such attacks. In this paper, an effective anomaly detection framework is proposed utilizing Bayesian Optimization technique to tune the parameters of Support Vector Machine with Gaussian Kernel (SVM-RBF), Random Forest (RF), and k-Nearest Neighbor (k-NN) algorithms. The performance of the considered algorithms is evaluated using the ISCX 2012 dataset. Experimental results show the effectiveness of the proposed framework in term of accuracy rate, precision, low-false alarm rate, and recall.
Multi-split Optimized Bagging Ensemble Model Selection for Multi-class Educational Data Mining
Jun 09, 2020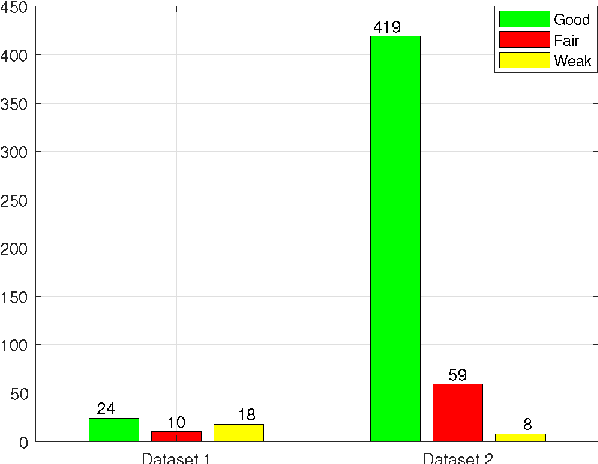
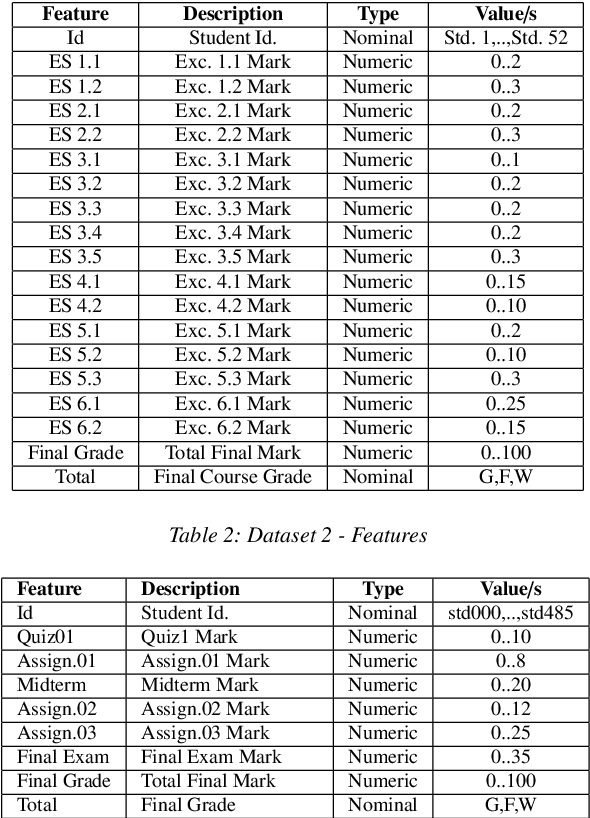
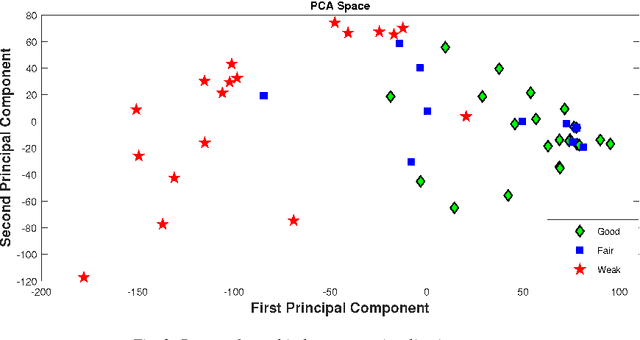
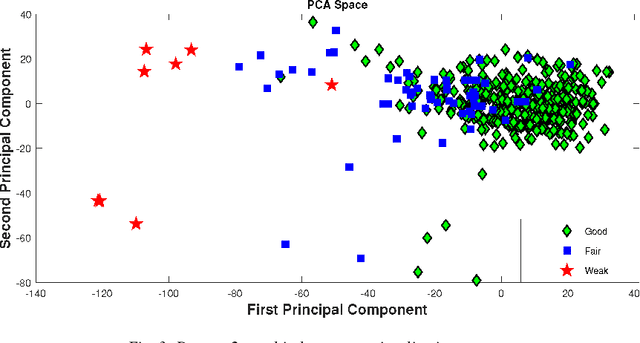
Predicting students' academic performance has been a research area of interest in recent years with many institutions focusing on improving the students' performance and the education quality. The analysis and prediction of students' performance can be achieved using various data mining techniques. Moreover, such techniques allow instructors to determine possible factors that may affect the students' final marks. To that end, this work analyzes two different undergraduate datasets at two different universities. Furthermore, this work aims to predict the students' performance at two stages of course delivery (20% and 50% respectively). This analysis allows for properly choosing the appropriate machine learning algorithms to use as well as optimize the algorithms' parameters. Furthermore, this work adopts a systematic multi-split approach based on Gini index and p-value. This is done by optimizing a suitable bagging ensemble learner that is built from any combination of six potential base machine learning algorithms. It is shown through experimental results that the posited bagging ensemble models achieve high accuracy for the target group for both datasets.
Data Mining with Big Data in Intrusion Detection Systems: A Systematic Literature Review
May 23, 2020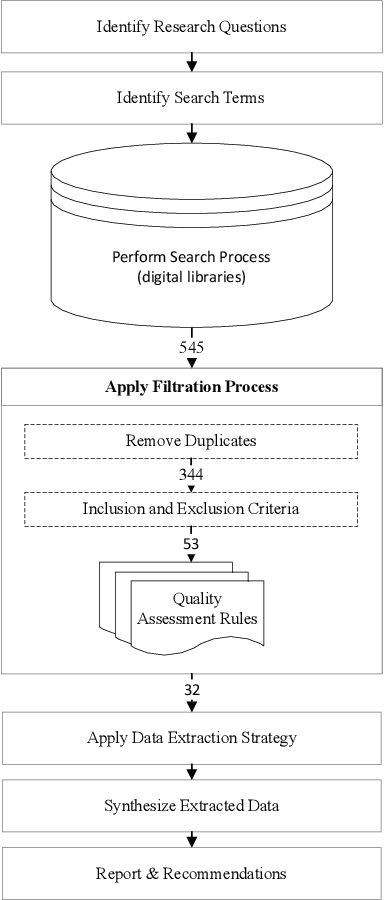
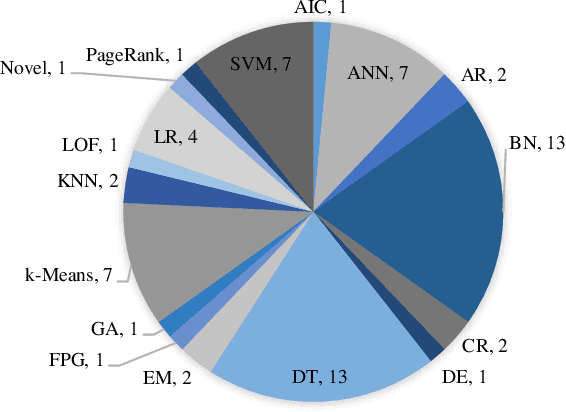
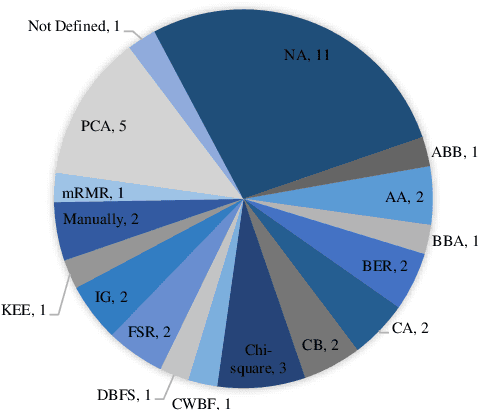
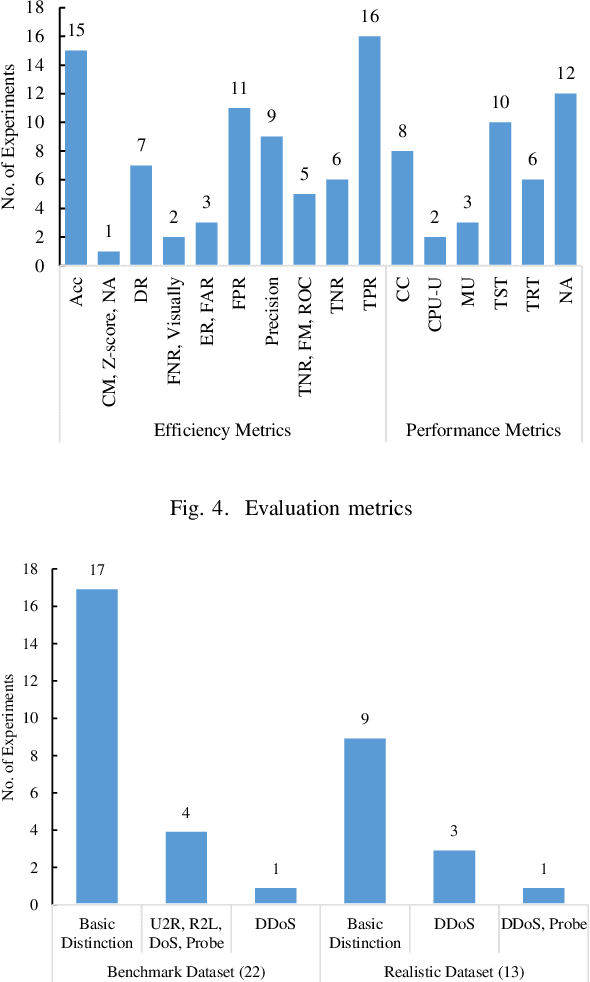
Cloud computing has become a powerful and indispensable technology for complex, high performance and scalable computation. The exponential expansion in the deployment of cloud technology has produced a massive amount of data from a variety of applications, resources and platforms. In turn, the rapid rate and volume of data creation has begun to pose significant challenges for data management and security. The design and deployment of intrusion detection systems (IDS) in the big data setting has, therefore, become a topic of importance. In this paper, we conduct a systematic literature review (SLR) of data mining techniques (DMT) used in IDS-based solutions through the period 2013-2018. We employed criterion-based, purposive sampling identifying 32 articles, which constitute the primary source of the present survey. After a careful investigation of these articles, we identified 17 separate DMTs deployed in an IDS context. This paper also presents the merits and disadvantages of the various works of current research that implemented DMTs and distributed streaming frameworks (DSF) to detect and/or prevent malicious attacks in a big data environment.
Systematic Ensemble Model Selection Approach for Educational Data Mining
May 13, 2020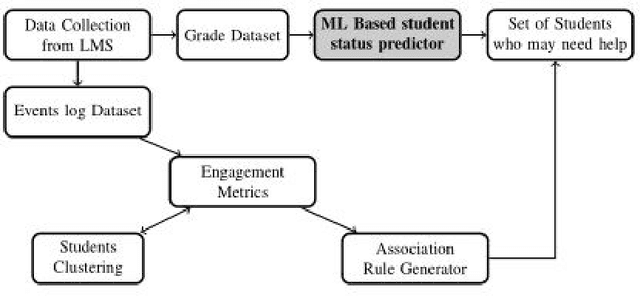
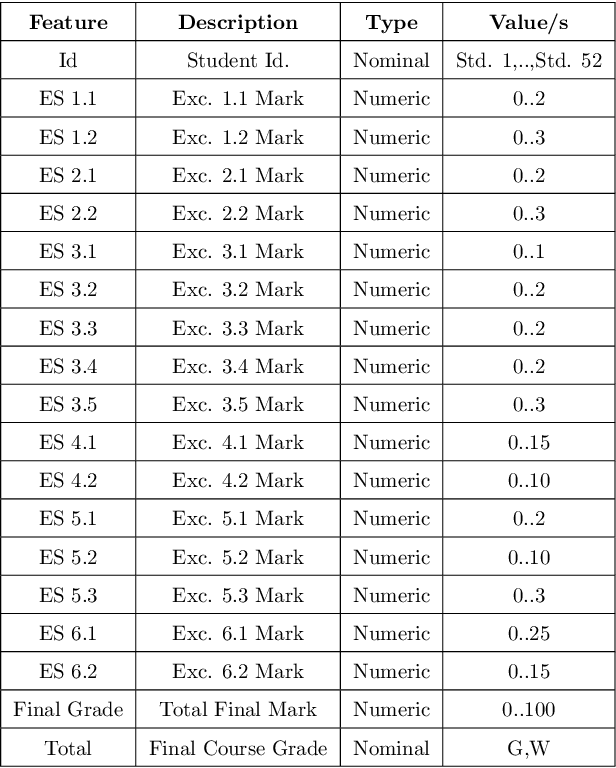
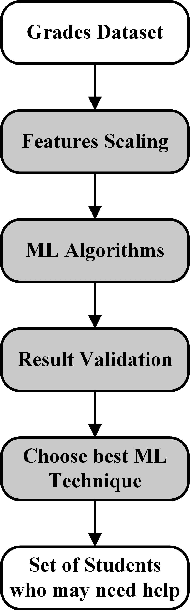
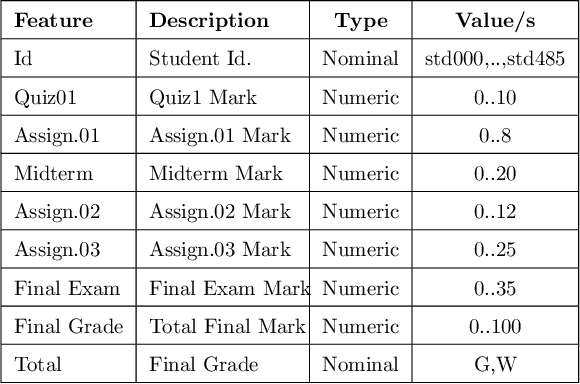
A plethora of research has been done in the past focusing on predicting student's performance in order to support their development. Many institutions are focused on improving the performance and the education quality; and this can be achieved by utilizing data mining techniques to analyze and predict students' performance and to determine possible factors that may affect their final marks. To address this issue, this work starts by thoroughly exploring and analyzing two different datasets at two separate stages of course delivery (20 percent and 50 percent respectively) using multiple graphical, statistical, and quantitative techniques. The feature analysis provides insights into the nature of the different features considered and helps in the choice of the machine learning algorithms and their parameters. Furthermore, this work proposes a systematic approach based on Gini index and p-value to select a suitable ensemble learner from a combination of six potential machine learning algorithms. Experimental results show that the proposed ensemble models achieve high accuracy and low false positive rate at all stages for both datasets.
Emirati-Accented Speaker Identification in Stressful Talking Conditions
Oct 29, 2019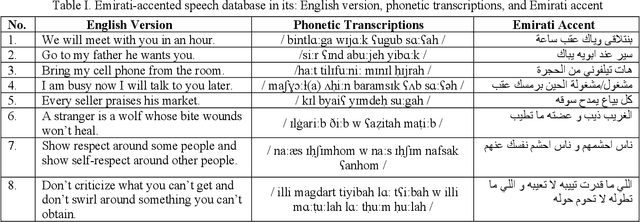
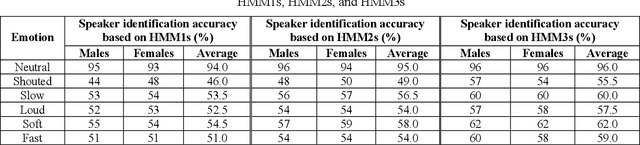
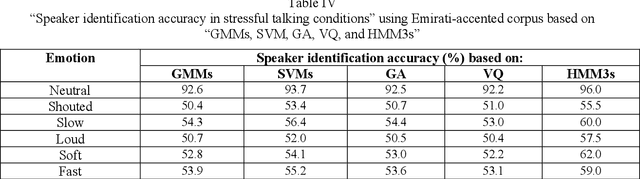
This research is dedicated to improving text-independent Emirati-accented speaker identification performance in stressful talking conditions using three distinct classifiers: First-Order Hidden Markov Models (HMM1s), Second-Order Hidden Markov Models (HMM2s), and Third-Order Hidden Markov Models (HMM3s). The database that has been used in this work was collected from 25 per gender Emirati native speakers uttering eight widespread Emirati sentences in each of neutral, shouted, slow, loud, soft, and fast talking conditions. The extracted features of the captured database are called Mel-Frequency Cepstral Coefficients (MFCCs). Based on HMM1s, HMM2s, and HMM3s, average Emirati-accented speaker identification accuracy in stressful conditions is 58.6%, 61.1%, and 65.0%, respectively. The achieved average speaker identification accuracy in stressful conditions based on HMM3s is so similar to that attained in subjective assessment by human listeners.
Ensemble of Learning Project Productivity in Software Effort Based on Use Case Points
Dec 16, 2018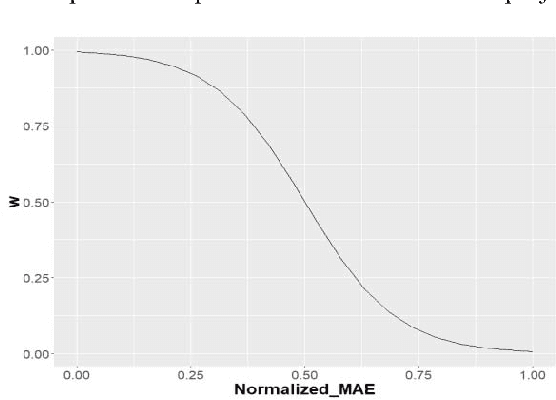
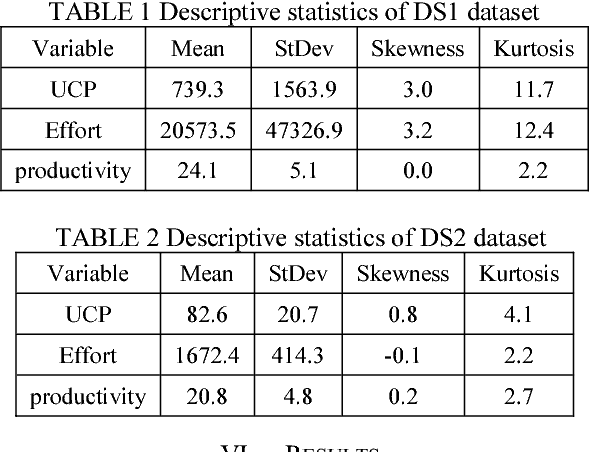
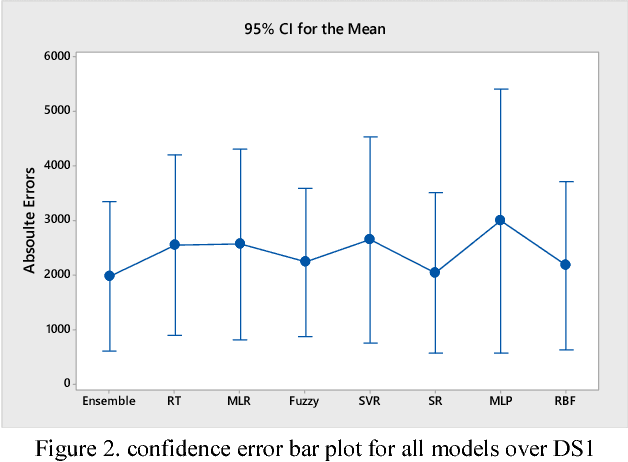
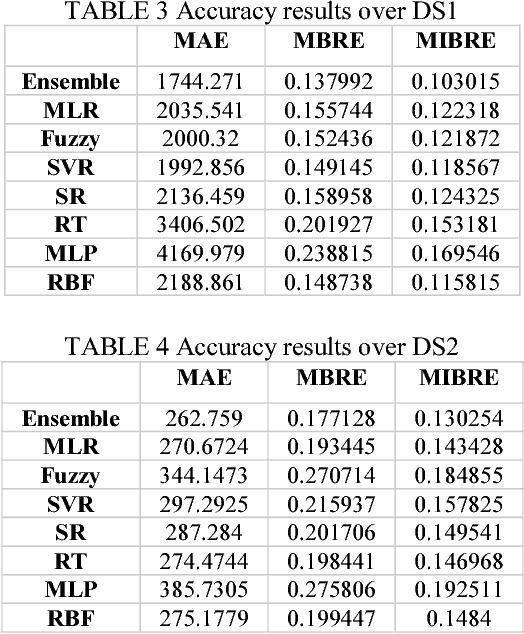
It is well recognized that the project productivity is a key driver in estimating software project effort from Use Case Point size metric at early software development stages. Although, there are few proposed models for predicting productivity, there is no consistent conclusion regarding which model is the superior. Therefore, instead of building a new productivity prediction model, this paper presents a new ensemble construction mechanism applied for software project productivity prediction. Ensemble is an effective technique when performance of base models is poor. We proposed a weighted mean method to aggregate predicted productivities based on average of errors produced by training model. The obtained results show that the using ensemble is a good alternative approach when accuracies of base models are not consistently accurate over different datasets, and when models behave diversely.