 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Master-Follower Teleoperation System for Robotic Catheterization: Design, Characterization, and Tracking Control
Jul 18, 2024Minimally invasive robotic surgery has gained significant attention over the past two decades. Telerobotic systems, combined with robot-mediated minimally invasive techniques, have enabled surgeons and clinicians to mitigate radiation exposure for medical staff and extend medical services to remote and hard-to-reach areas. To enhance these services, teleoperated robotic surgery systems incorporating master and follower devices should offer transparency, enabling surgeons and clinicians to remotely experience a force interaction similar to the one the follower device experiences with patients' bodies. This paper presents the design and development of a three-degree-of-freedom master-follower teleoperated system for robotic catheterization. To resemble manual intervention by clinicians, the follower device features a grip-insert-release mechanism to eliminate catheter buckling and torsion during operation. The bidirectionally navigable ablation catheter is statically characterized for force-interactive medical interventions. The system's performance is evaluated through approaching and open-loop path tracking over typical circular, infinity-like, and spiral paths. Path tracking errors are presented as mean Euclidean error (MEE) and mean absolute error (MAE). The MEE ranges from 0.64 cm (infinity-like path) to 1.53 cm (spiral path). The MAE also ranges from 0.81 cm (infinity-like path) to 1.92 cm (spiral path). The results indicate that while the system's precision and accuracy with an open-loop controller meet the design targets, closed-loop controllers are necessary to address the catheter's hysteresis and dead zone, and system nonlinearities.
Deep Direct Visual Servoing of Tendon-Driven Continuum Robots
Nov 04, 2021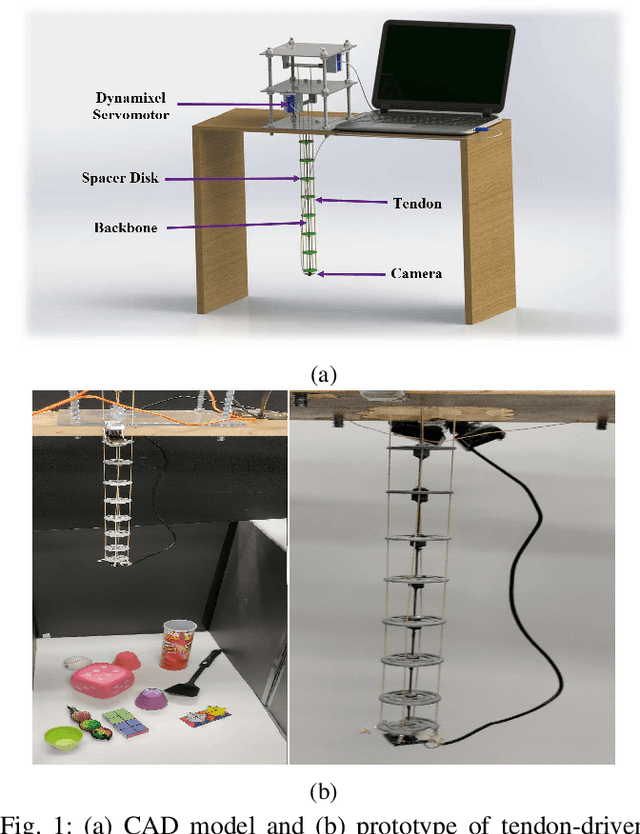

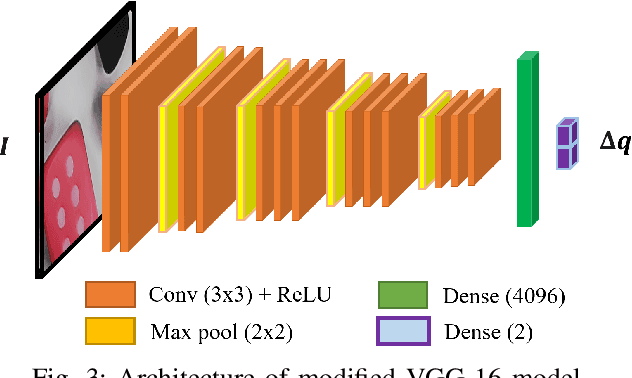

Vision-based control has found a key place in the research to tackle the requirement of the state feedback when controlling a continuum robot under physical sensing limitations. Traditional visual servoing requires feature extraction and tracking while the imaging device captures the images, which limits the controller's efficiency. We hypothesize that employing deep learning models and implementing direct visual servoing can effectively resolve the issue by eliminating the tracking requirement and controlling the continuum robot without requiring an exact system model. In this paper, we control a single-section tendon-driven continuum robot utilizing a modified VGG-16 deep learning network and an eye-in-hand direct visual servoing approach. The proposed algorithm is first developed in Blender using only one input image of the target and then implemented on a real robot. The convergence and accuracy of the results in normal, shadowed, and occluded scenes reflected by the sum of absolute difference between the normalized target and captured images prove the effectiveness and robustness of the proposed controller.
Forward and Inverse Kinematics of a Single Section Inextensible Continuum Arm
Jul 15, 2019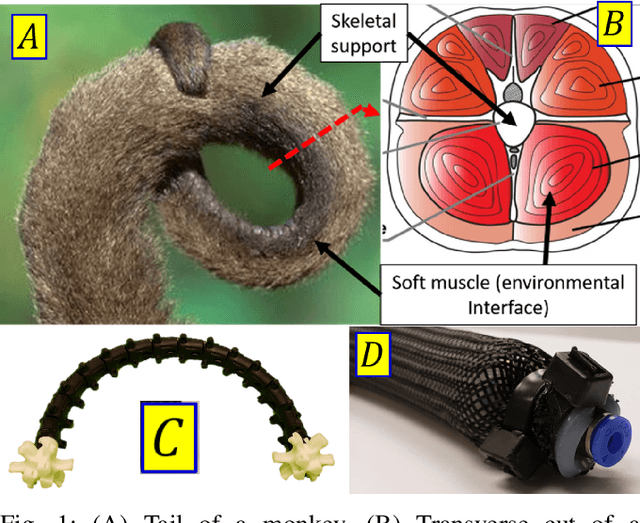

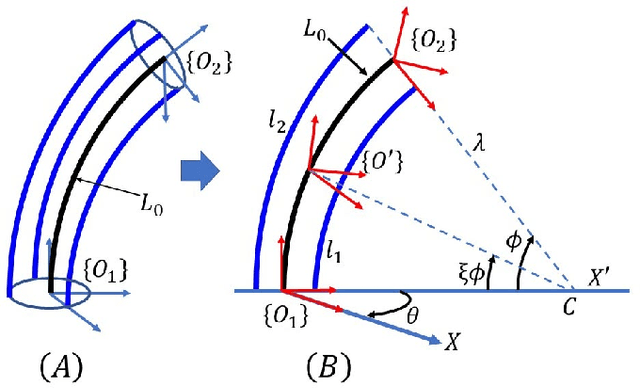
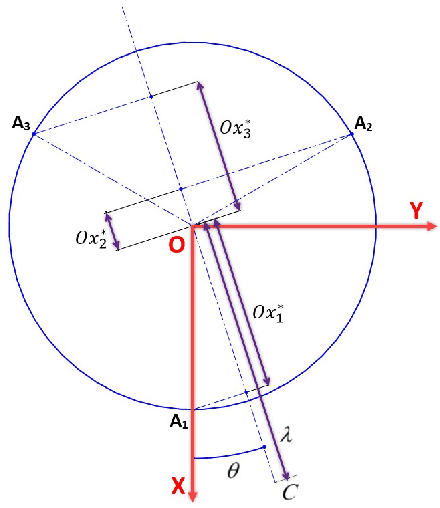
Continuum arms, such as trunk and tentacle robots, lie between the two extremities of rigid and soft robots and promise to capture the best of both worlds in terms of manipulability, dexterity, and compliance. This paper proposes a new kinematic model for a novel constant-length continuum robot that incorporates both soft and rigid elements. In contrast to traditional pneumatically actuated, variable-length continuum arms, the proposed design utilizes a hyper-redundant rigid chain to provide extra structural strength. The proposed model introduces a reduced-order mapping to account for mechanical constraints arising from the rigid-linked chain to derive a closed-form curve parametric model. The model is numerically evaluated and the results show that the derived model is reliable.