 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DPyranet Features Fusion for Spatio-temporal Feature Learning
Apr 26, 2025Convolutional neural network (CNN) slides a kernel over the whole image to produce an output map. This kernel scheme reduces the number of parameters with respect to a fully connected neural network (NN). While CNN has proven to be an effective model in recognition of handwritten characters and traffic signal sign boards, etc. recently, its deep variants have proven to be effective in similar as well as more challenging applications like object, scene and action recognition. Deep CNN add more layers and kernels to the classical CNN, increasing the number of parameters, and partly reducing the main advantage of CNN which is less parameters. In this paper, a 3D pyramidal neural network called 3DPyraNet and a discriminative approach for spatio-temporal feature learning based on it, called 3DPyraNet-F, are proposed. 3DPyraNet introduces a new weighting scheme which learns features from both spatial and temporal dimensions analyzing multiple adjacent frames and keeping a biological plausible structure. It keeps the spatial topology of the input image and presents fewer parameters and lower computational and memory costs compared to both fully connected NNs and recent deep CNNs. 3DPyraNet-F extract the features maps of the highest layer of the learned network, fuse them in a single vector, and provide it as input in such a way to a linear-SVM classifier that enhances the recognition of human actions and dynamic scenes from the videos. Encouraging results are reported with 3DPyraNet in real-world environments, especially in the presence of camera induced motion. Further, 3DPyraNet-F clearly outperforms the state-of-the-art on three benchmark datasets and shows comparable result for the fourth.
About Pyramid Structure in Convolutional Neural Networks
Aug 14, 2016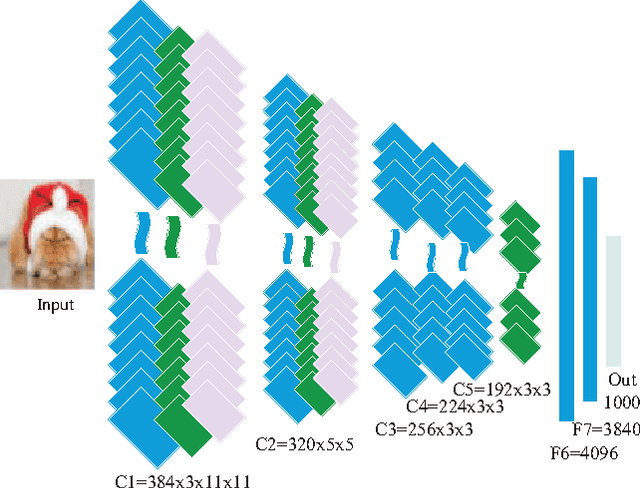
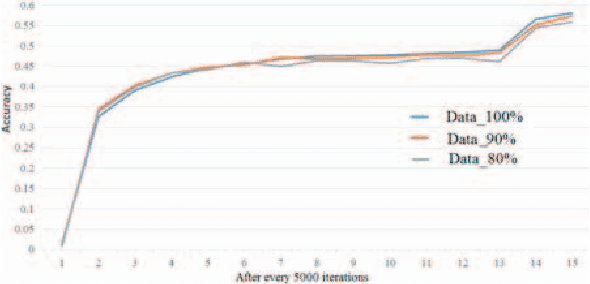
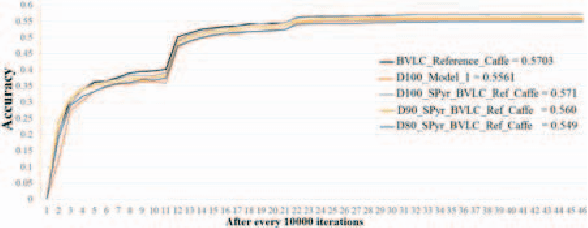
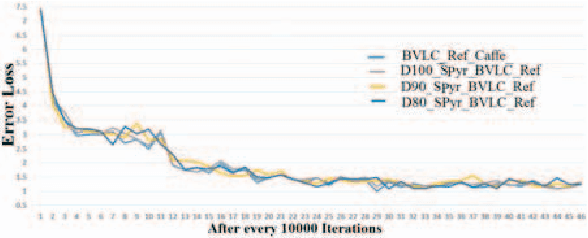
Deep convolutional neural networks (CNN) brought revolution without any doubt to various challenging tasks, mainly in computer vision. However, their model designing still requires attention to reduce number of learnable parameters, with no meaningful reduction in performance. In this paper we investigate to what extend CNN may take advantage of pyramid structure typical of biological neurons. A generalized statement over convolutional layers from input till fully connected layer is introduced that helps further in understanding and designing a successful deep network. It reduces ambiguity, number of parameters, and their size on disk without degrading overall accuracy. Performance are shown on state-of-the-art models for MNIST, Cifar-10, Cifar-100, and ImageNet-12 datasets. Despite more than 80% reduction in parameters for Caffe_LENET, challenging results are obtained. Further, despite 10-20% reduction in training data along with 10-40% reduction in parameters for AlexNet model and its variations, competitive results are achieved when compared to similar well-engineered deeper architectures.
Towards Benchmarking Scene Background Initialization
Jun 12, 2015

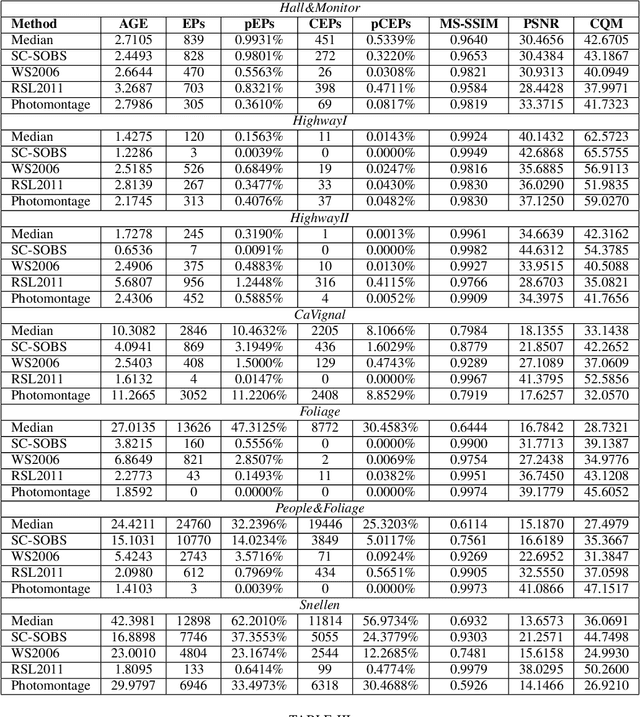
Given a set of images of a scene taken at different times, the availability of an initial background model that describes the scene without foreground objects is the prerequisite for a wide range of applications, ranging from video surveillance to computational photography. Even though several methods have been proposed for scene background initialization, the lack of a common groundtruthed dataset and of a common set of metrics makes it difficult to compare their performance. To move first steps towards an easy and fair comparison of these methods, we assembled a dataset of sequences frequently adopted for background initialization, selected or created ground truths for quantitative evaluation through a selected suite of metrics, and compared results obtained by some existing methods, making all the material publicly available.