 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Translation Without Parallel Data
Jan 30, 2018
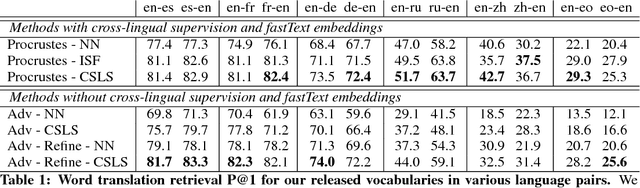
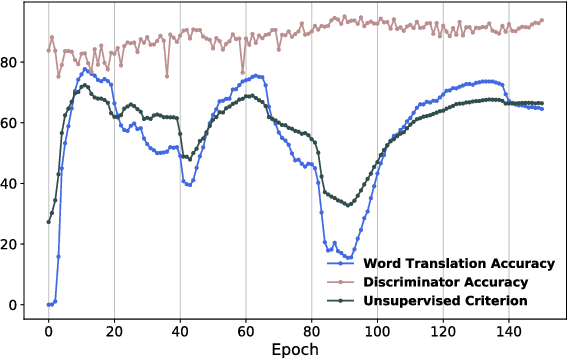
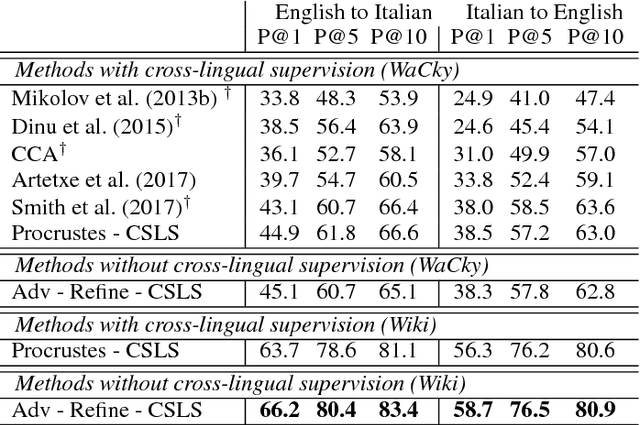
State-of-the-art methods for learning cross-lingual word embeddings have relied on bilingual dictionaries or parallel corpora. Recent studies showed that the need for parallel data supervision can be alleviated with character-level information. While these methods showed encouraging results, they are not on par with their supervised counterparts and are limited to pairs of languages sharing a common alphabet. In this work, we show that we can build a bilingual dictionary between two languages without using any parallel corpora, by aligning monolingual word embedding spaces in an unsupervised way. Without using any character information, our model even outperforms existing supervised methods on cross-lingual tasks for some language pairs. Our experiments demonstrate that our method works very well also for distant language pairs, like English-Russian or English-Chinese. We finally describe experiments on the English-Esperanto low-resource language pair, on which there only exists a limited amount of parallel data, to show the potential impact of our method in fully unsupervised machine translation. Our code, embeddings and dictionaries are publicly available.
Very Deep Convolutional Networks for Text Classification
Jan 27, 2017
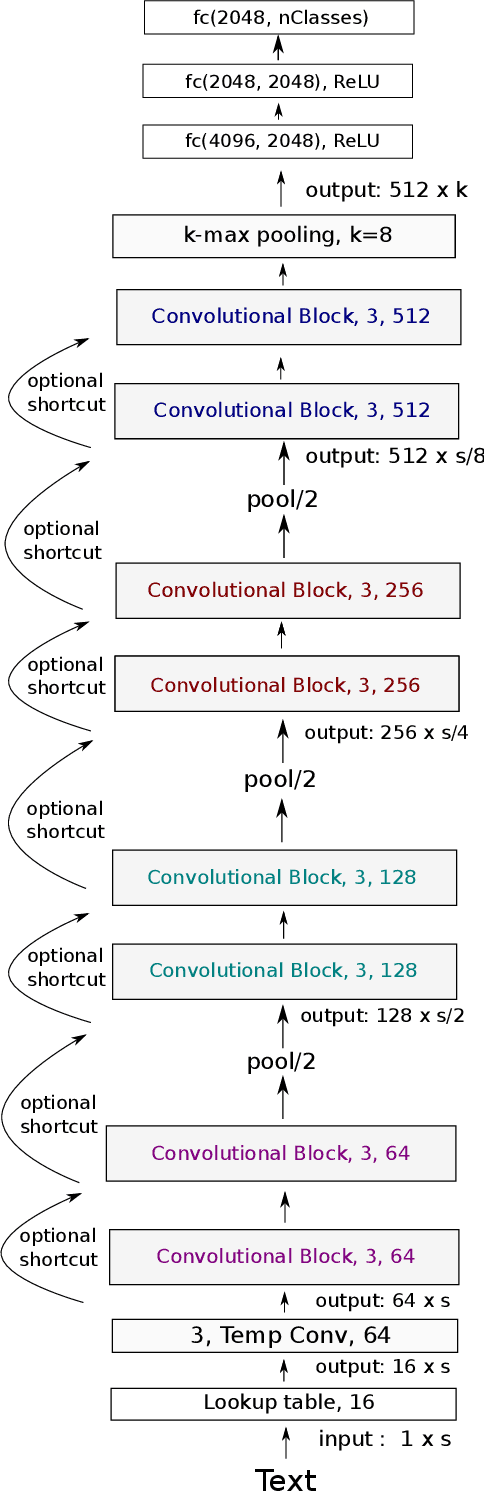
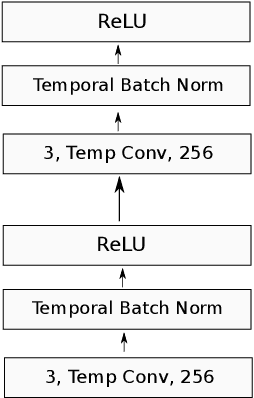

The dominant approach for many NLP tasks are recurrent neural networks, in particular LSTMs, and convolutional neural networks. However, these architectures are rather shallow in comparison to the deep convolutional networks which have pushed the state-of-the-art in computer vision. We present a new architecture (VDCNN) for text processing which operates directly at the character level and uses only small convolutions and pooling operations. We are able to show that the performance of this model increases with depth: using up to 29 convolutional layers, we report improvements over the state-of-the-art on several public text classification tasks. To the best of our knowledge, this is the first time that very deep convolutional nets have been applied to text processing.
Meta-Prod2Vec - Product Embeddings Using Side-Information for Recommendation
Jul 25, 2016

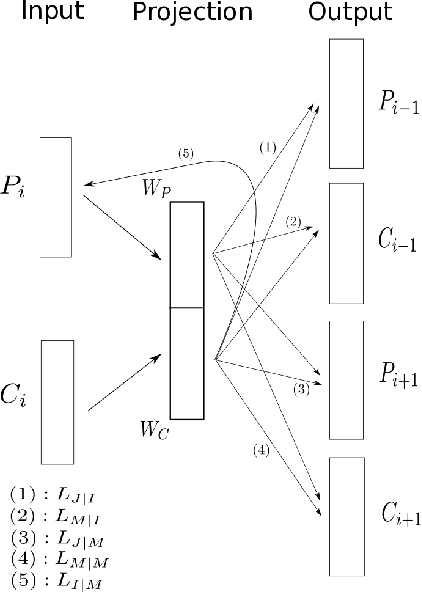

We propose Meta-Prod2vec, a novel method to compute item similarities for recommendation that leverages existing item metadata. Such scenarios are frequently encountered in applications such as content recommendation, ad targeting and web search. Our method leverages past user interactions with items and their attributes to compute low-dimensional embeddings of items. Specifically, the item metadata is in- jected into the model as side information to regularize the item embeddings. We show that the new item representa- tions lead to better performance on recommendation tasks on an open music dataset.