 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA systematic literature Review for Transformer-based Software Vulnerability detection
Apr 27, 2026Context: Software vulnerabilities pose significant security threats to software systems, especially as software is increasingly used across many areas of daily life, including health, government, and finance. Recently, transformer-based models have demonstrated promising results in automatic software vulnerability identification due to their robust contextual modelling and representation learning capabilities. Objectives: While numerous systematic literature reviews (SLRs) have examined machine learning and deep learning methods for identifying vulnerabilities, a more transformer-centric analysis remains to be explored. This SLR critically analysed 80 studies published between 2021 and 2025 that utilised transformer models to identify software vulnerabilities. Methods: Using Kitchenhams SLR guidelines, we methodically evaluate current research from various perspectives, encompassing study trends, datasets and sources, programming languages, transformer frameworks, detection detail levels, assessment metrics, reference models, types of vulnerabilities, and experimental configurations. Results: We classify transformer models into encoder, decoder, and combined architectures and analyse both pre-trained and fine-tuned versions utilized on source code, logs, and smart contracts. The results emphasise prevailing research trends, frequently utilised benchmarks, and main baselines. It also uncovers crucial technical issues like data imbalance, interpretability, scalability, and generalization across programming languages. Conclusion: By integrating current evidence and recognising unaddressed research areas, this SLR provides a consolidated resource for researchers and professionals seeking to develop more reliable, precise, and interpretable transformer-based vulnerability identification systems.
Launching Adversarial Attacks against Network Intrusion Detection Systems for IoT
Apr 26, 2021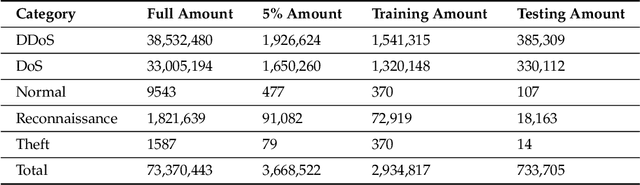
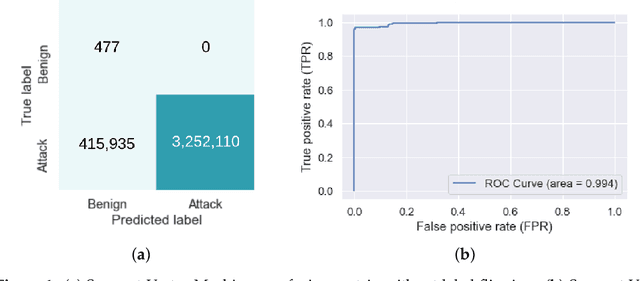
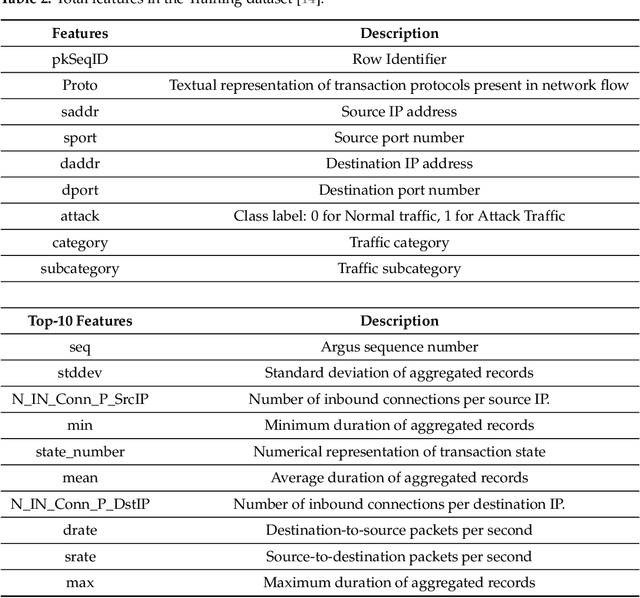
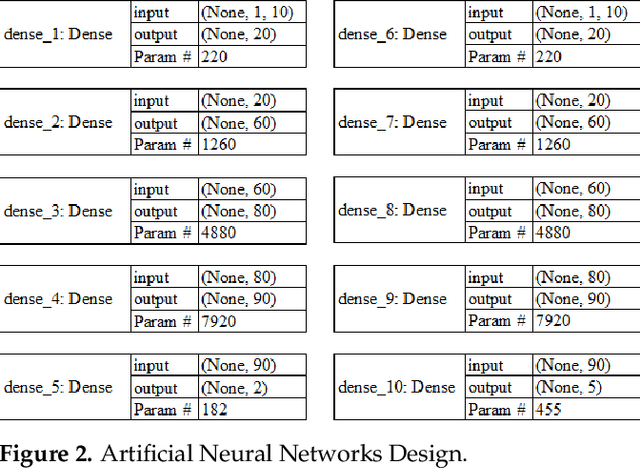
As the internet continues to be populated with new devices and emerging technologies, the attack surface grows exponentially. Technology is shifting towards a profit-driven Internet of Things market where security is an afterthought. Traditional defending approaches are no longer sufficient to detect both known and unknown attacks to high accuracy. Machine learning intrusion detection systems have proven their success in identifying unknown attacks with high precision. Nevertheless, machine learning models are also vulnerable to attacks. Adversarial examples can be used to evaluate the robustness of a designed model before it is deployed. Further, using adversarial examples is critical to creating a robust model designed for an adversarial environment. Our work evaluates both traditional machine learning and deep learning models' robustness using the Bot-IoT dataset. Our methodology included two main approaches. First, label poisoning, used to cause incorrect classification by the model. Second, the fast gradient sign method, used to evade detection measures. The experiments demonstrated that an attacker could manipulate or circumvent detection with significant probability.
* MDPI Mach. Learn. Knowl. Extr. 2021, 3(2), 333-356; https://www.mdpi.com/2624-800X/1/2/14