 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge#HashtagWars: Learning a Sense of Humor
Apr 15, 2017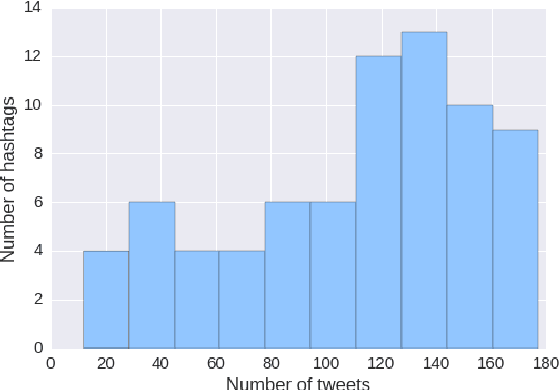
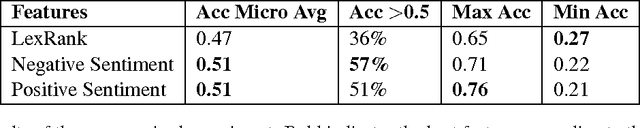

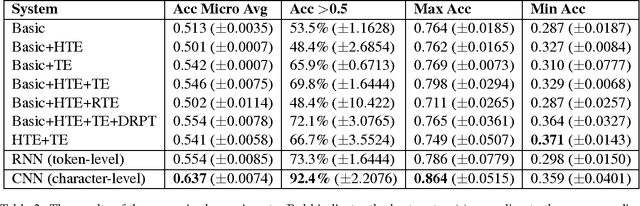
In this work, we present a new dataset for computational humor, specifically comparative humor ranking, which attempts to eschew the ubiquitous binary approach to humor detection. The dataset consists of tweets that are humorous responses to a given hashtag. We describe the motivation for this new dataset, as well as the collection process, which includes a description of our semi-automated system for data collection. We also present initial experiments for this dataset using both unsupervised and supervised approaches. Our best supervised system achieved 63.7% accuracy, suggesting that this task is much more difficult than comparable humor detection tasks. Initial experiments indicate that a character-level model is more suitable for this task than a token-level model, likely due to a large amount of puns that can be captured by a character-level model.
Evaluating Creative Language Generation: The Case of Rap Lyric Ghostwriting
Dec 09, 2016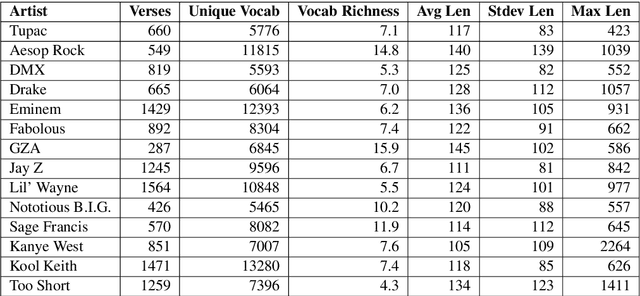

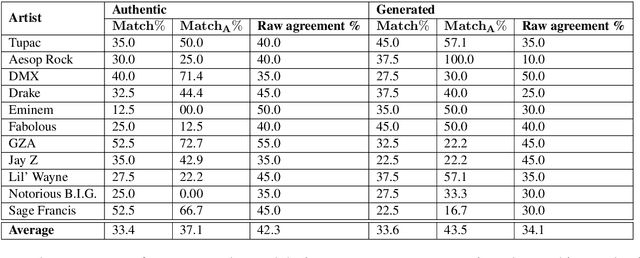
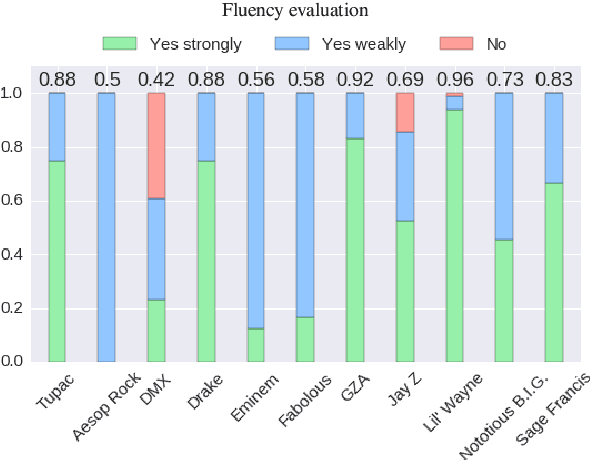
Language generation tasks that seek to mimic human ability to use language creatively are difficult to evaluate, since one must consider creativity, style, and other non-trivial aspects of the generated text. The goal of this paper is to develop evaluation methods for one such task, ghostwriting of rap lyrics, and to provide an explicit, quantifiable foundation for the goals and future directions of this task. Ghostwriting must produce text that is similar in style to the emulated artist, yet distinct in content. We develop a novel evaluation methodology that addresses several complementary aspects of this task, and illustrate how such evaluation can be used to meaningfully analyze system performance. We provide a corpus of lyrics for 13 rap artists, annotated for stylistic similarity, which allows us to assess the feasibility of manual evaluation for generated verse.