 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk is (Not) Cheap: A Taxonomy and Benchmark Coverage Audit for LLM Attacks
May 14, 2026We introduce a reusable framework for auditing whether LLM attack benchmarks collectively cover the threat surface: a 4$\times$6 Target $\times$ Technique matrix grounded in STRIDE, constructed from a 507-leaf taxonomy -- 401 data-populated and 106 threat-model-derived leaves -- of inference-time attacks extracted from 932 arXiv security studies (2023--2026). The matrix enables benchmark-external validation -- auditing collective coverage rather than individual benchmark consistency. Applying it to six public benchmarks reveals that the three primary frameworks (HarmBench, InjecAgent, AgentDojo) occupy non-overlapping cells covering at most 25\% of the matrix, while entire STRIDE threat categories (Service Disruption, Model Internals) lack any standardized evaluation, despite published attacks in these categories achieving 46$\times$ token amplification and 96\% attack success rates through mechanisms which no benchmark tests. The corpus of 2,521 unique attack groups further reveals pervasive naming fragmentation (up to 29 surface forms for a single attack) and heavy concentration in Safety \& Alignment Bypass, structural properties invisible at smaller scale. The taxonomy, attack records, and coverage mappings are released as extensible artifacts; as new benchmarks emerge, they can be mapped onto the same matrix, enabling the community to track whether evaluation gaps are closing.
Telegraph English: Semantic Prompt Compression via Structured Symbolic Rewriting
May 06, 2026We introduce Telegraph English (TE), a prompt-compression protocol that rewrites natural language into a symbol-rich, formally-structured dialect. Where token-deletion methods such as LLMLingua-2 train a classifier to delete low-importance tokens at a fixed ratio, TE performs a full semantic rewrite: it decomposes the input into atomic fact lines, substitutes verbose phrases with $\sim$40 logical and relational symbols, and lets the compression ratio adapt to each document's information density. A consequence of the line-structure rule is that compression and semantic chunking become the same operation -- each output line is an independently addressable fact, so the compressed representation is simultaneously a semantic index. We evaluate TE on 4{,}081 question-answer pairs from LongBench-v2 across five OpenAI models and two difficulty levels. At roughly 50\% token reduction, TE preserves 99.1\% accuracy on key facts with GPT-4.1 and outperforms LLMLingua-2 at matched compression ratios on every model and task tested. The gap widens on smaller models -- up to 11 percentage points on fine-detail tasks -- suggesting that explicit relational structure compensates for limited model capacity. We release the grammar specification, compression prompt, benchmark data, and reference implementation.
Beyond Exponential Decay: Rethinking Error Accumulation in Large Language Models
May 30, 2025The prevailing assumption of an exponential decay in large language model (LLM) reliability with sequence length, predicated on independent per-token error probabilities, posits an inherent limitation for long autoregressive outputs. Our research fundamentally challenges this view by synthesizing emerging evidence that LLM errors are not uniformly distributed but are concentrated at sparse "key tokens" ($5-10\%$ of total tokens) representing critical decision junctions. By distinguishing these high-impact tokens from the increasingly predictable majority, we introduce a new reliability formula explaining the sustained coherence of modern LLMs over thousands of tokens. Converging research streams reveal that long-context performance primarily depends on accurately navigating a few crucial semantic decision points rather than on uniform token-level accuracy, enabling targeted strategies that significantly outperform brute-force approaches. We thus propose a framework for next-generation systems centered on selective preservation of semantically vital tokens, dynamic computational allocation at uncertain decision boundaries, multi-path exploration at ambiguities, and architectures aligned with natural semantic domains. This marks a fundamental shift from raw scaling to strategic reasoning, promising breakthrough performance without proportionate computational scaling and offering a more nuanced understanding that supersedes the exponential decay hypothesis, thereby opening pathways toward substantially more powerful and efficient language systems.
Breast Tumor Cellularity Assessment using Deep Neural Networks
May 05, 2019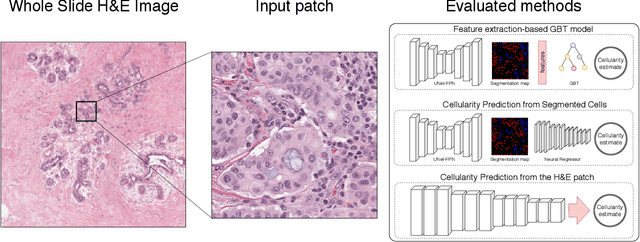
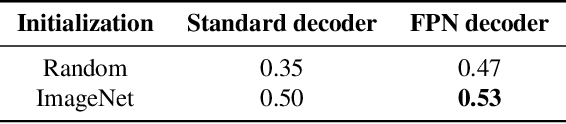
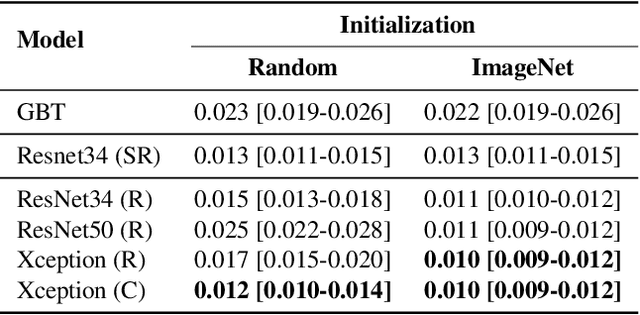
Breast cancer is one of the main causes of death worldwide. Histopathological cellularity assessment of residual tumors in post-surgical tissues is used to analyze a tumor's response to a therapy. Correct cellularity assessment increases the chances of getting an appropriate treatment and facilitates the patient's survival. In current clinical practice, tumor cellularity is manually estimated by pathologists; this process is tedious and prone to errors or low agreement rates between assessors. In this work, we evaluated three strong novel Deep Learning-based approaches for automatic assessment of tumor cellularity from post-treated breast surgical specimens stained with hematoxylin and eosin. We validated the proposed methods on the BreastPathQ SPIE challenge dataset that consisted of 2395 image patches selected from whole slide images acquired from 64 patients. Compared to expert pathologist scoring, our best performing method yielded the Cohen's kappa coefficient of 0.70 (vs. 0.42 previously known in literature) and the intra-class correlation coefficient of 0.89 (vs. 0.83). Our results suggest that Deep Learning-based methods have a significant potential to alleviate the burden on pathologists, enhance the diagnostic workflow, and, thereby, facilitate better clinical outcomes in breast cancer treatment.
Fully Convolutional Network for Automatic Road Extraction from Satellite Imagery
Jun 19, 2018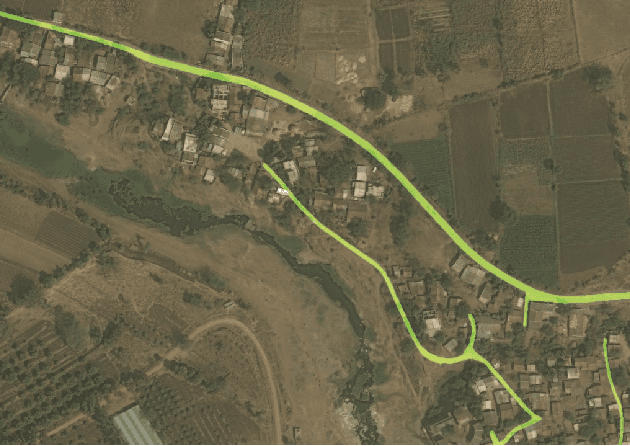
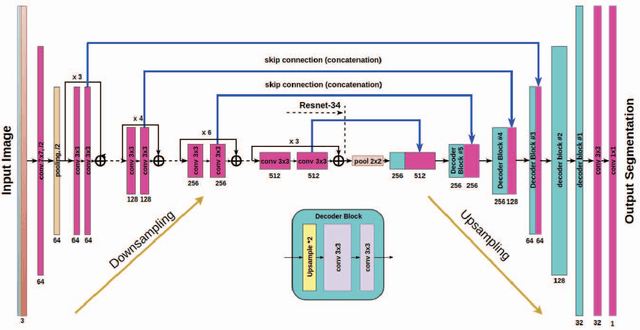
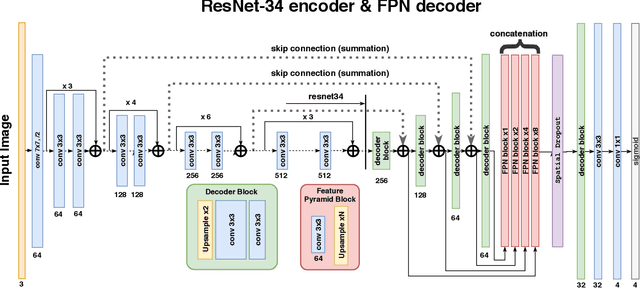
Analysis of high-resolution satellite images has been an important research topic for traffic management, city planning, and road monitoring. One of the problems here is automatic and precise road extraction. From an original image, it is difficult and computationally expensive to extract roads due to presences of other road-like features with straight edges. In this paper, we propose an approach for automatic road extraction based on a fully convolutional neural network of U-net family. This network consists of ResNet-34 pre-trained on ImageNet and decoder adapted from vanilla U-Net. Based on validation results, leaderboard and our own experience this network shows superior results for the DEEPGLOBE - CVPR 2018 road extraction sub-challenge. Moreover, this network uses moderate memory that allows using just one GTX 1080 or 1080ti video cards to perform whole training and makes pretty fast predictions.
Feature Pyramid Network for Multi-Class Land Segmentation
Jun 19, 2018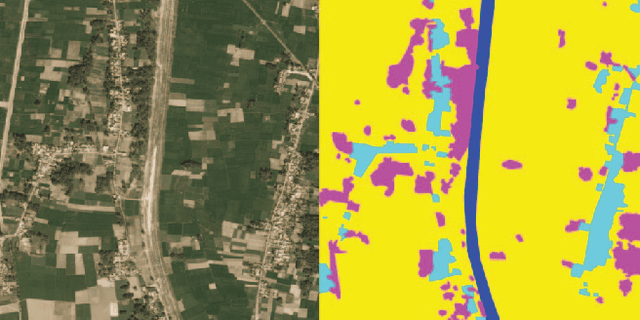
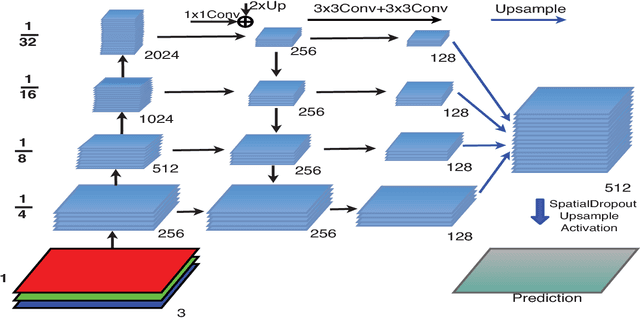
Semantic segmentation is in-demand in satellite imagery processing. Because of the complex environment, automatic categorization and segmentation of land cover is a challenging problem. Solving it can help to overcome many obstacles in urban planning, environmental engineering or natural landscape monitoring. In this paper, we propose an approach for automatic multi-class land segmentation based on a fully convolutional neural network of feature pyramid network (FPN) family. This network is consisted of pre-trained on ImageNet Resnet50 encoder and neatly developed decoder. Based on validation results, leaderboard score and our own experience this network shows reliable results for the DEEPGLOBE - CVPR 2018 land cover classification sub-challenge. Moreover, this network moderately uses memory that allows using GTX 1080 or 1080 TI video cards to perform whole training and makes pretty fast predictions.