 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible image analysis for law enforcement agencies with deep neural networks to determine: where, who and what
May 15, 2024Due to the increasing need for effective security measures and the integration of cameras in commercial products, a hugeamount of visual data is created today. Law enforcement agencies (LEAs) are inspecting images and videos to findradicalization, propaganda for terrorist organizations and illegal products on darknet markets. This is time consuming.Instead of an undirected search, LEAs would like to adapt to new crimes and threats, and focus only on data from specificlocations, persons or objects, which requires flexible interpretation of image content. Visual concept detection with deepconvolutional neural networks (CNNs) is a crucial component to understand the image content. This paper has fivecontributions. The first contribution allows image-based geo-localization to estimate the origin of an image. CNNs andgeotagged images are used to create a model that determines the location of an image by its pixel values. The secondcontribution enables analysis of fine-grained concepts to distinguish sub-categories in a generic concept. The proposedmethod encompasses data acquisition and cleaning and concept hierarchies. The third contribution is the recognition ofperson attributes (e.g., glasses or moustache) to enable query by textual description for a person. The person-attributeproblem is treated as a specific sub-task of concept classification. The fourth contribution is an intuitive image annotationtool based on active learning. Active learning allows users to define novel concepts flexibly and train CNNs with minimalannotation effort. The fifth contribution increases the flexibility for LEAs in the query definition by using query expansion.Query expansion maps user queries to known and detectable concepts. Therefore, no prior knowledge of the detectableconcepts is required for the users. The methods are validated on data with varying locations (popular and non-touristiclocations), varying person attributes (CelebA dataset), and varying number of annotations.
Visual Relationship Detection Based on Guided Proposals and Semantic Knowledge Distillation
May 28, 2018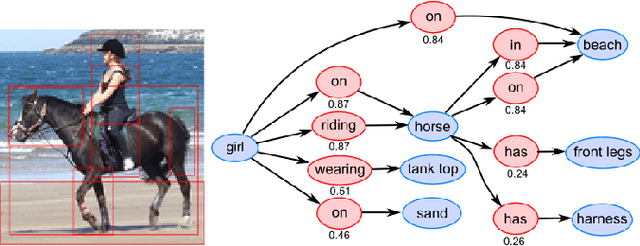
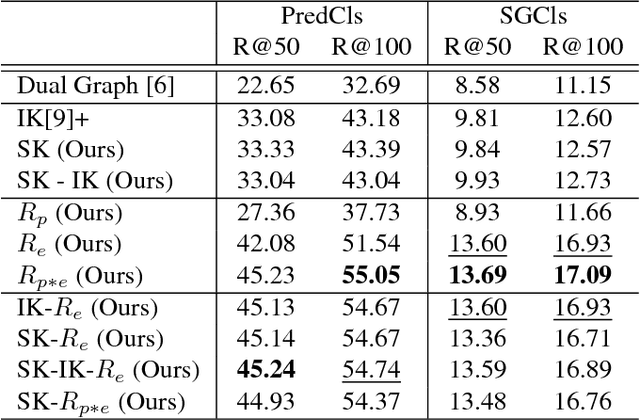
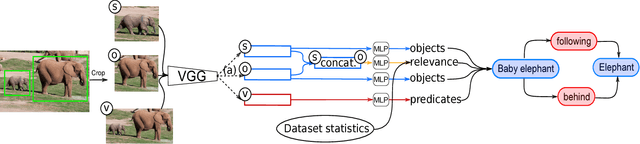
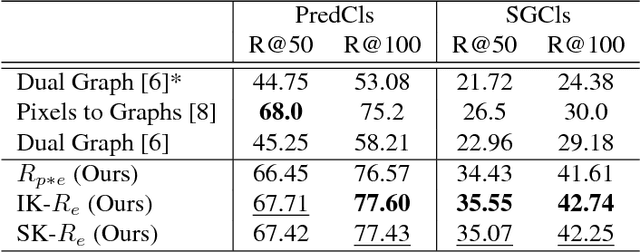
A thorough comprehension of image content demands a complex grasp of the interactions that may occur in the natural world. One of the key issues is to describe the visual relationships between objects. When dealing with real world data, capturing these very diverse interactions is a difficult problem. It can be alleviated by incorporating common sense in a network. For this, we propose a framework that makes use of semantic knowledge and estimates the relevance of object pairs during both training and test phases. Extracted from precomputed models and training annotations, this information is distilled into the neural network dedicated to this task. Using this approach, we observe a significant improvement on all classes of Visual Genome, a challenging visual relationship dataset. A 68.5% relative gain on the recall at 100 is directly related to the relevance estimate and a 32.7% gain to the knowledge distillation.
On Deep Representation Learning from Noisy Web Images
Jul 15, 2016
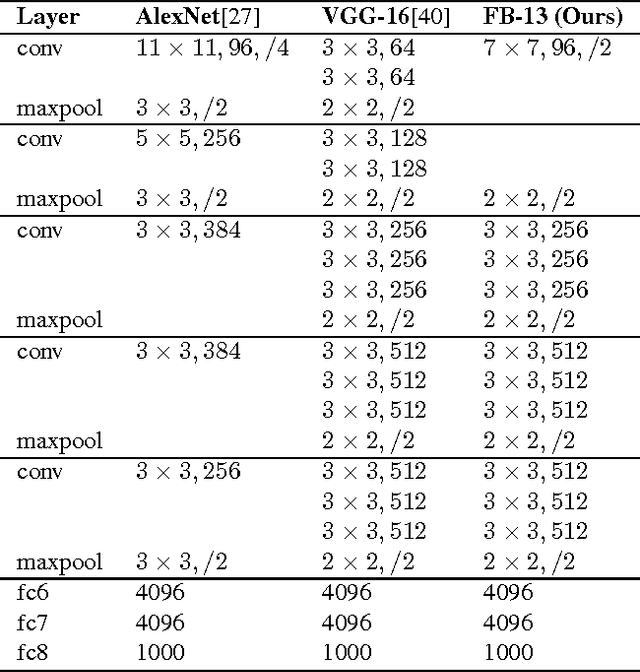

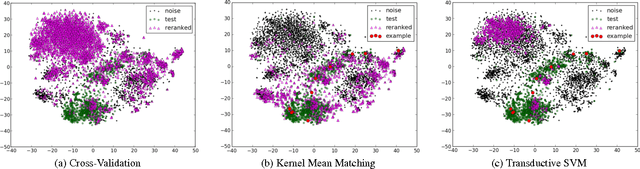
The keep-growing content of Web images may be the next important data source to scale up deep neural networks, which recently obtained a great success in the ImageNet classification challenge and related tasks. This prospect, however, has not been validated on convolutional networks (convnet) -- one of best performing deep models -- because of their supervised regime. While unsupervised alternatives are not so good as convnet in generalizing the learned model to new domains, we use convnet to leverage semi-supervised representation learning. Our approach is to use massive amounts of unlabeled and noisy Web images to train convnets as general feature detectors despite challenges coming from data such as high level of mislabeled data, outliers, and data biases. Extensive experiments are conducted at several data scales, different network architectures, and data reranking techniques. The learned representations are evaluated on nine public datasets of various topics. The best results obtained by our convnets, trained on 3.14 million Web images, outperform AlexNet trained on 1.2 million clean images of ILSVRC 2012 and is closing the gap with VGG-16. These prominent results suggest a budget solution to use deep learning in practice and motivate more research in semi-supervised representation learning.