 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Invariance Matters: Rethinking Graph Rewiring through Graph Metrics
Oct 23, 2025Graph rewiring has emerged as a key technique to alleviate over-squashing in Graph Neural Networks (GNNs) and Graph Transformers by modifying the graph topology to improve information flow. While effective, rewiring inherently alters the graph's structure, raising the risk of distorting important topology-dependent signals. Yet, despite the growing use of rewiring, little is known about which structural properties must be preserved to ensure both performance gains and structural fidelity. In this work, we provide the first systematic analysis of how rewiring affects a range of graph structural metrics, and how these changes relate to downstream task performance. We study seven diverse rewiring strategies and correlate changes in local and global graph properties with node classification accuracy. Our results reveal a consistent pattern: successful rewiring methods tend to preserve local structure while allowing for flexibility in global connectivity. These findings offer new insights into the design of effective rewiring strategies, bridging the gap between graph theory and practical GNN optimization.
A Hybrid Artificial Intelligence Method for Estimating Flicker in Power Systems
Jun 16, 2025This paper introduces a novel hybrid AI method combining H filtering and an adaptive linear neuron network for flicker component estimation in power distribution systems.The proposed method leverages the robustness of the H filter to extract the voltage envelope under uncertain and noisy conditions followed by the use of ADALINE to accurately identify flicker frequencies embedded in the envelope.This synergy enables efficient time domain estimation with rapid convergence and noise resilience addressing key limitations of existing frequency domain approaches.Unlike conventional techniques this hybrid AI model handles complex power disturbances without prior knowledge of noise characteristics or extensive training.To validate the method performance we conduct simulation studies based on IEC Standard 61000 4 15 supported by statistical analysis Monte Carlo simulations and real world data.Results demonstrate superior accuracy robustness and reduced computational load compared to Fast Fourier Transform and Discrete Wavelet Transform based estimators.
Navigating Intelligence: A Survey of Google OR-Tools and Machine Learning for Global Path Planning in Autonomous Vehicles
Mar 05, 2025We offer a new in-depth investigation of global path planning (GPP) for unmanned ground vehicles, an autonomous mining sampling robot named ROMIE. GPP is essential for ROMIE's optimal performance, which is translated into solving the traveling salesman problem, a complex graph theory challenge that is crucial for determining the most effective route to cover all sampling locations in a mining field. This problem is central to enhancing ROMIE's operational efficiency and competitiveness against human labor by optimizing cost and time. The primary aim of this research is to advance GPP by developing, evaluating, and improving a cost-efficient software and web application. We delve into an extensive comparison and analysis of Google operations research (OR)-Tools optimization algorithms. Our study is driven by the goal of applying and testing the limits of OR-Tools capabilities by integrating Reinforcement Learning techniques for the first time. This enables us to compare these methods with OR-Tools, assessing their computational effectiveness and real-world application efficiency. Our analysis seeks to provide insights into the effectiveness and practical application of each technique. Our findings indicate that Q-Learning stands out as the optimal strategy, demonstrating superior efficiency by deviating only 1.2% on average from the optimal solutions across our datasets.
A Multitask Deep Learning Model for Classification and Regression of Hyperspectral Images: Application to the large-scale dataset
Jul 23, 2024



Multitask learning is a widely recognized technique in the field of computer vision and deep learning domain. However, it is still a research question in remote sensing, particularly for hyperspectral imaging. Moreover, most of the research in the remote sensing domain focuses on small and single-task-based annotated datasets, which limits the generalizability and scalability of the developed models to more diverse and complex real-world scenarios. Thus, in this study, we propose a multitask deep learning model designed to perform multiple classification and regression tasks simultaneously on hyperspectral images. We validated our approach on a large hyperspectral dataset called TAIGA, which contains 13 forest variables, including three categorical variables and ten continuous variables with different biophysical parameters. We design a sharing encoder and task-specific decoder network to streamline feature learning while allowing each task-specific decoder to focus on the unique aspects of its respective task. Additionally, a dense atrous pyramid pooling layer and attention network were integrated to extract multi-scale contextual information and enable selective information processing by prioritizing task-specific features. Further, we computed multitask loss and optimized its parameters for the proposed framework to improve the model performance and efficiency across diverse tasks. A comprehensive qualitative and quantitative analysis of the results shows that the proposed method significantly outperforms other state-of-the-art methods. We trained our model across 10 seeds/trials to ensure robustness. Our proposed model demonstrates higher mean performance while maintaining lower or equivalent variability. To make the work reproducible, the codes will be available at https://github.com/Koushikey4596/Multitask-Deep-Learning-Model-for-Taiga-datatset.
First Full-Event Reconstruction from Imaging Atmospheric Cherenkov Telescope Real Data with Deep Learning
May 31, 2021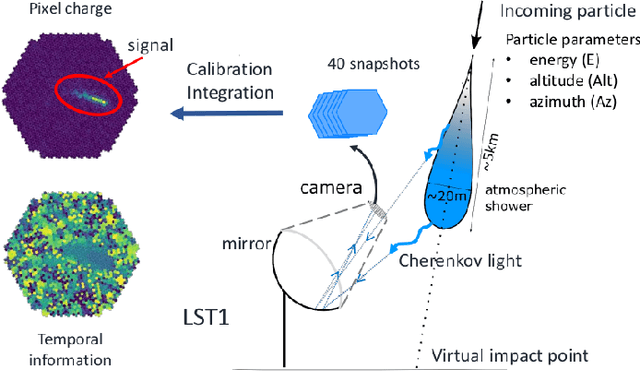
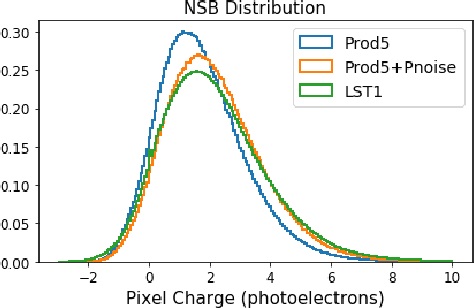
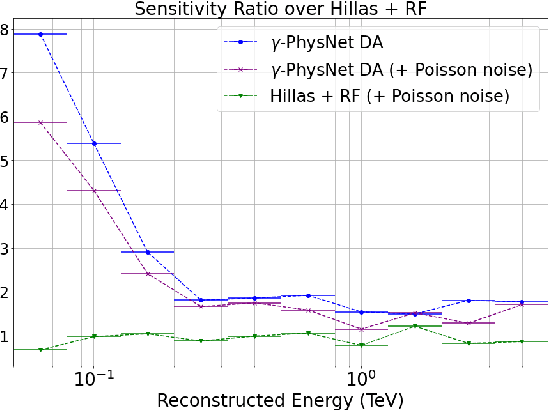
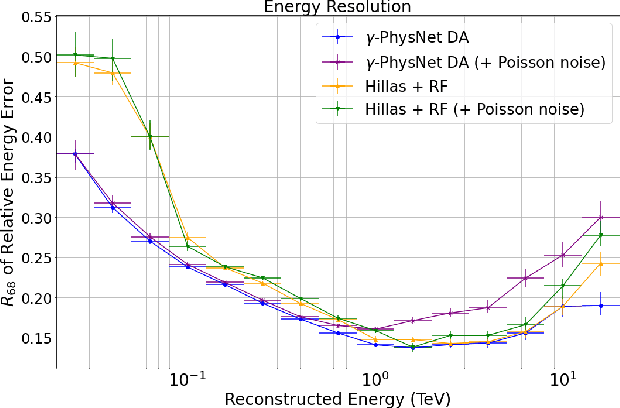
The Cherenkov Telescope Array is the future of ground-based gamma-ray astronomy. Its first prototype telescope built on-site, the Large Size Telescope 1, is currently under commissioning and taking its first scientific data. In this paper, we present for the first time the development of a full-event reconstruction based on deep convolutional neural networks and its application to real data. We show that it outperforms the standard analysis, both on simulated and on real data, thus validating the deep approach for the CTA data analysis. This work also illustrates the difficulty of moving from simulated data to actual data.
Deep Learning for automatic sale receipt understanding
Dec 05, 2017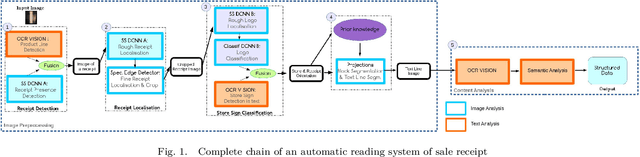
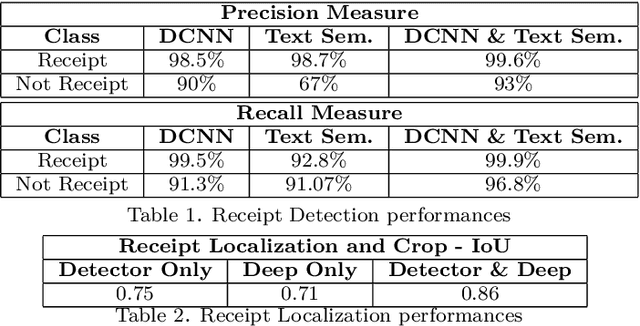
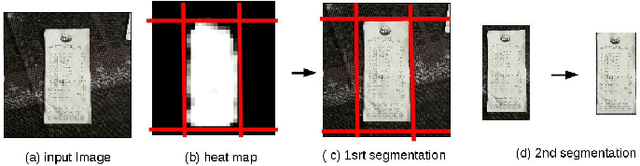

As a general rule, data analytics are now mandatory for companies. Scanned document analysis brings additional challenges introduced by paper damages and scanning quality.In an industrial context, this work focuses on the automatic understanding of sale receipts which enable access to essential and accurate consumption statistics. Given an image acquired with a smart-phone, the proposed work mainly focuses on the first steps of the full tool chain which aims at providing essential information such as the store brand, purchased products and related prices with the highest possible confidence. To get this high confidence level, even if scanning is not perfectly controlled, we propose a double check processing tool-chain using Deep Convolutional Neural Networks (DCNNs) on one hand and more classical image and text processings on another hand.The originality of this work relates in this double check processing and in the joint use of DCNNs for different applications and text analysis.
Sign Language Tutoring Tool
Feb 18, 2008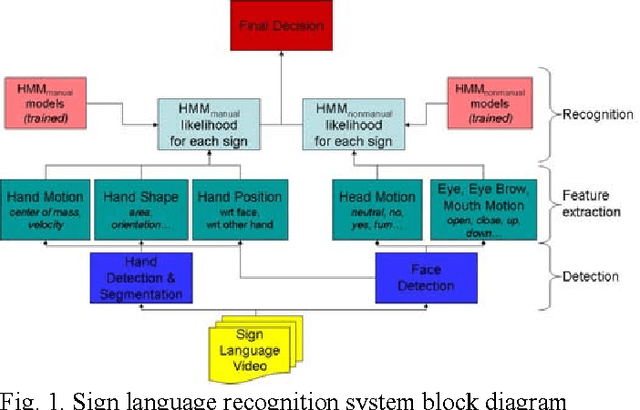
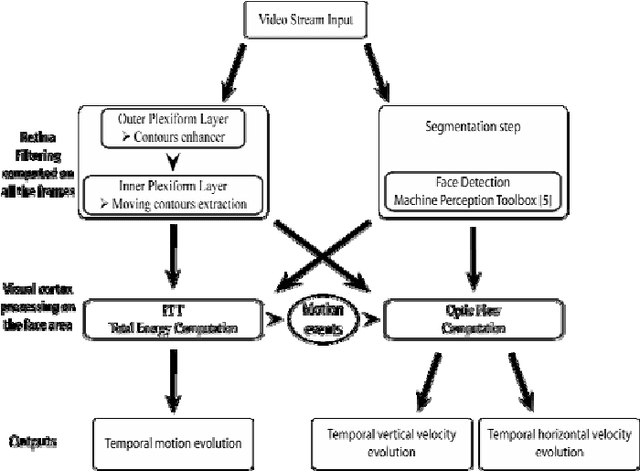
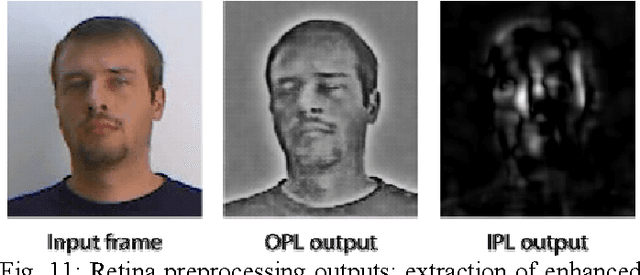
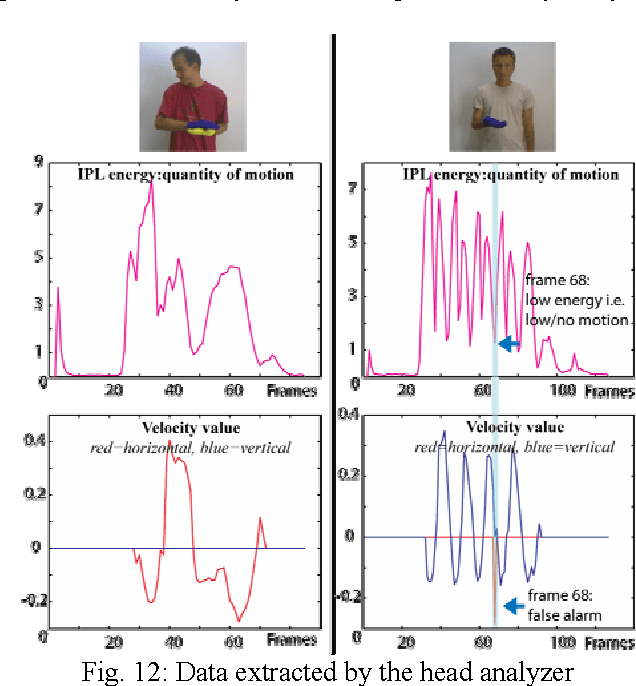
In this project, we have developed a sign language tutor that lets users learn isolated signs by watching recorded videos and by trying the same signs. The system records the user's video and analyses it. If the sign is recognized, both verbal and animated feedback is given to the user. The system is able to recognize complex signs that involve both hand gestures and head movements and expressions. Our performance tests yield a 99% recognition rate on signs involving only manual gestures and 85% recognition rate on signs that involve both manual and non manual components, such as head movement and facial expressions.