 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoPose2D: Pushing the Boundaries of 2D Human Pose Estimation using Neuroevolution
Nov 17, 2020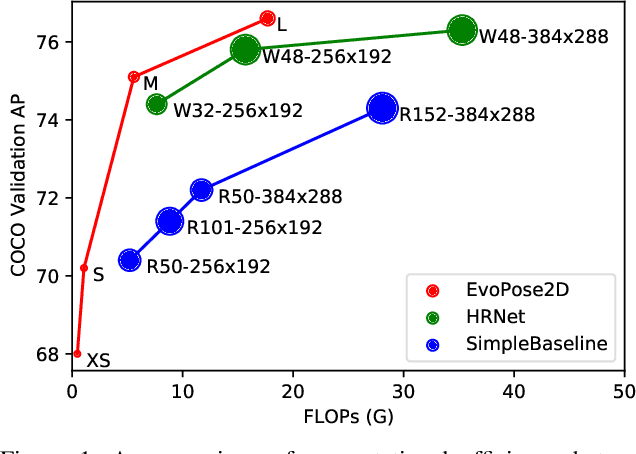
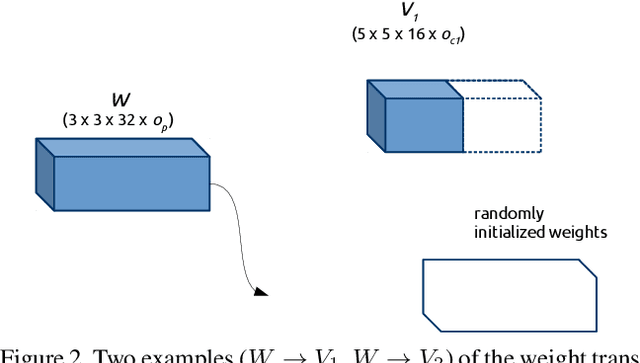
Neural architecture search has proven to be highly effective in the design of computationally efficient, task-specific convolutional neural networks across several areas of computer vision. In 2D human pose estimation, however, its application has been limited by high computational demands. Hypothesizing that neural architecture search holds great potential for 2D human pose estimation, we propose a new weight transfer scheme that relaxes function-preserving mutations, enabling us to accelerate neuroevolution in a flexible manner. Our method produces 2D human pose network designs that are more efficient and more accurate than state-of-the-art hand-designed networks. In fact, the generated networks can process images at higher resolutions using less computation than previous networks at lower resolutions, permitting us to push the boundaries of 2D human pose estimation. Our baseline network designed using neuroevolution, which we refer to as EvoPose2D-S, provides comparable accuracy to SimpleBaseline while using 4.9x fewer floating-point operations and 13.5x fewer parameters. Our largest network, EvoPose2D-L, achieves new state-of-the-art accuracy on the Microsoft COCO Keypoints benchmark while using 2.0x fewer operations and 4.3x fewer parameters than its nearest competitor.
Identifying and interpreting tuning dimensions in deep networks
Nov 05, 2020



In neuroscience, a tuning dimension is a stimulus attribute that accounts for much of the activation variance of a group of neurons. These are commonly used to decipher the responses of such groups. While researchers have attempted to manually identify an analogue to these tuning dimensions in deep neural networks, we are unaware of an automatic way to discover them. This work contributes an unsupervised framework for identifying and interpreting "tuning dimensions" in deep networks. Our method correctly identifies the tuning dimensions of a synthetic Gabor filter bank and tuning dimensions of the first two layers of InceptionV1 trained on ImageNet.
Insights into Fairness through Trust: Multi-scale Trust Quantification for Financial Deep Learning
Nov 03, 2020
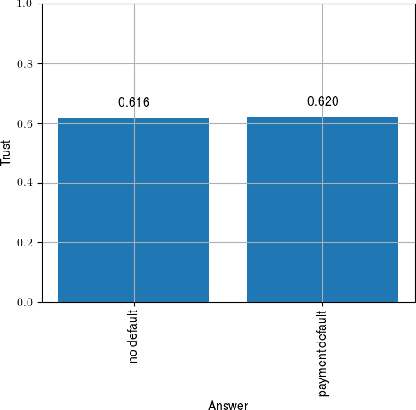
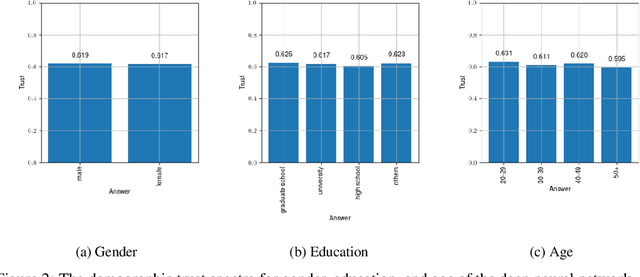
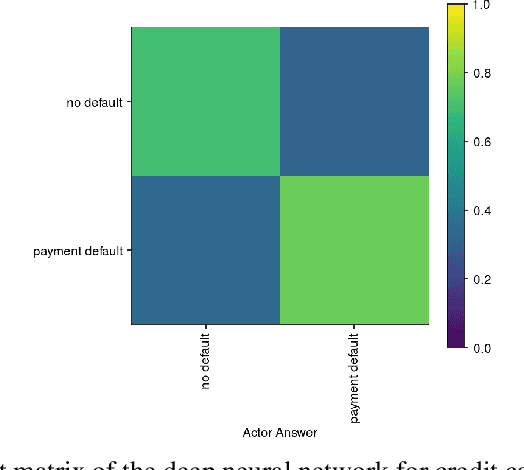
The success of deep learning in recent years have led to a significant increase in interest and prevalence for its adoption to tackle financial services tasks. One particular question that often arises as a barrier to adopting deep learning for financial services is whether the developed financial deep learning models are fair in their predictions, particularly in light of strong governance and regulatory compliance requirements in the financial services industry. A fundamental aspect of fairness that has not been explored in financial deep learning is the concept of trust, whose variations may point to an egocentric view of fairness and thus provide insights into the fairness of models. In this study we explore the feasibility and utility of a multi-scale trust quantification strategy to gain insights into the fairness of a financial deep learning model, particularly under different scenarios at different scales. More specifically, we conduct multi-scale trust quantification on a deep neural network for the purpose of credit card default prediction to study: 1) the overall trustworthiness of the model 2) the trust level under all possible prediction-truth relationships, 3) the trust level across the spectrum of possible predictions, 4) the trust level across different demographic groups (e.g., age, gender, and education), and 5) distribution of overall trust for an individual prediction scenario. The insights for this proof-of-concept study demonstrate that such a multi-scale trust quantification strategy may be helpful for data scientists and regulators in financial services as part of the verification and certification of financial deep learning solutions to gain insights into fairness and trust of these solutions.
AEGIS: A real-time multimodal augmented reality computer vision based system to assist facial expression recognition for individuals with autism spectrum disorder
Oct 22, 2020The ability to interpret social cues comes naturally for most people, but for those living with Autism Spectrum Disorder (ASD), some experience a deficiency in this area. This paper presents the development of a multimodal augmented reality (AR) system which combines the use of computer vision and deep convolutional neural networks (CNN) in order to assist individuals with the detection and interpretation of facial expressions in social settings. The proposed system, which we call AEGIS (Augmented-reality Expression Guided Interpretation System), is an assistive technology deployable on a variety of user devices including tablets, smartphones, video conference systems, or smartglasses, showcasing its extreme flexibility and wide range of use cases, to allow integration into daily life with ease. Given a streaming video camera source, each real-world frame is passed into AEGIS, processed for facial bounding boxes, and then fed into our novel deep convolutional time windowed neural network (TimeConvNet). We leverage both spatial and temporal information in order to provide an accurate expression prediction, which is then converted into its corresponding visualization and drawn on top of the original video frame. The system runs in real-time, requires minimal set up and is simple to use. With the use of AEGIS, we can assist individuals living with ASD to learn to better identify expressions and thus improve their social experiences.
Where's the Question? A Multi-channel Deep Convolutional Neural Network for Question Identification in Textual Data
Oct 15, 2020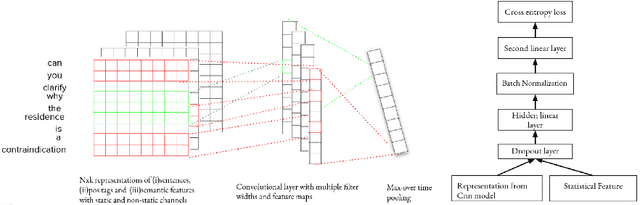
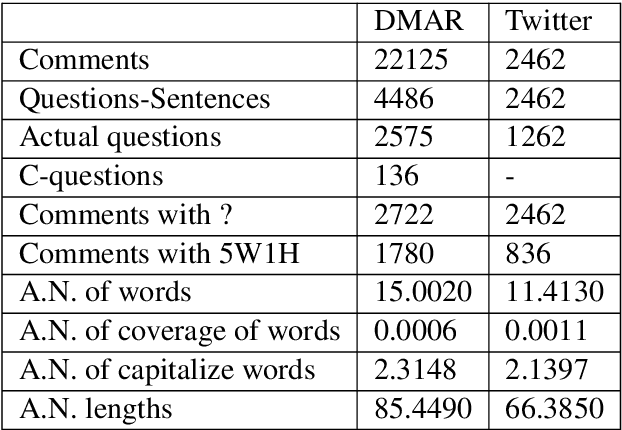
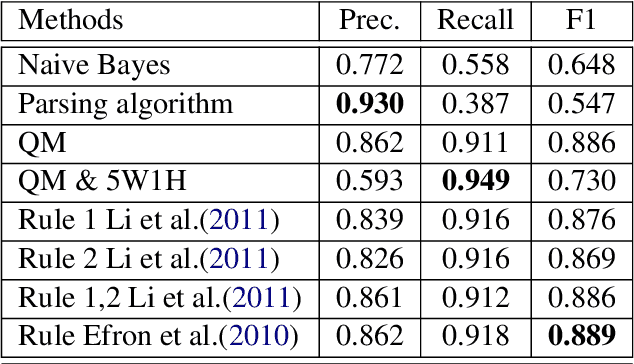
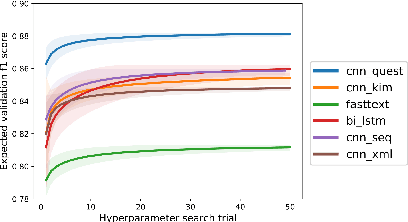
In most clinical practice settings, there is no rigorous reviewing of the clinical documentation, resulting in inaccurate information captured in the patient medical records. The gold standard in clinical data capturing is achieved via "expert-review", where clinicians can have a dialogue with a domain expert (reviewers) and ask them questions about data entry rules. Automatically identifying "real questions" in these dialogues could uncover ambiguities or common problems in data capturing in a given clinical setting. In this study, we proposed a novel multi-channel deep convolutional neural network architecture, namely Quest-CNN, for the purpose of separating real questions that expect an answer (information or help) about an issue from sentences that are not questions, as well as from questions referring to an issue mentioned in a nearby sentence (e.g., can you clarify this?), which we will refer as "c-questions". We conducted a comprehensive performance comparison analysis of the proposed multi-channel deep convolutional neural network against other deep neural networks. Furthermore, we evaluated the performance of traditional rule-based and learning-based methods for detecting question sentences. The proposed Quest-CNN achieved the best F1 score both on a dataset of data entry-review dialogue in a dialysis care setting, and on a general domain dataset.
Where Does Trust Break Down? A Quantitative Trust Analysis of Deep Neural Networks via Trust Matrix and Conditional Trust Densities
Sep 30, 2020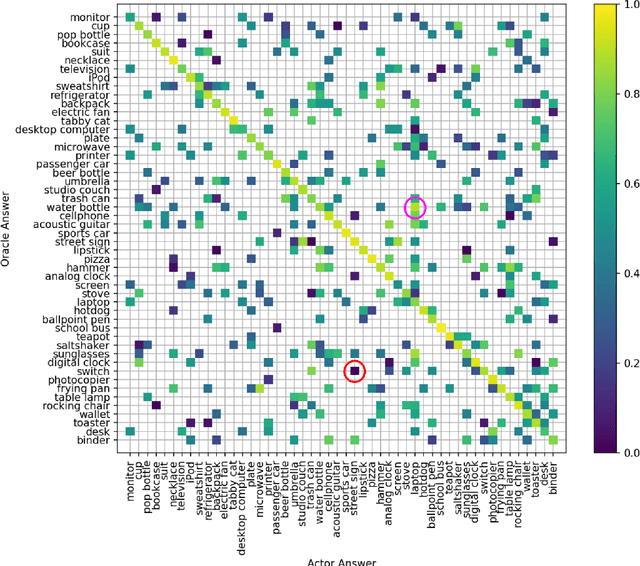
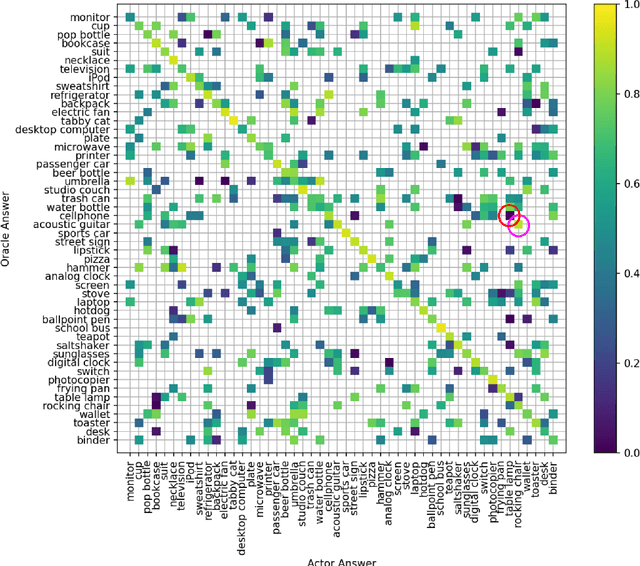
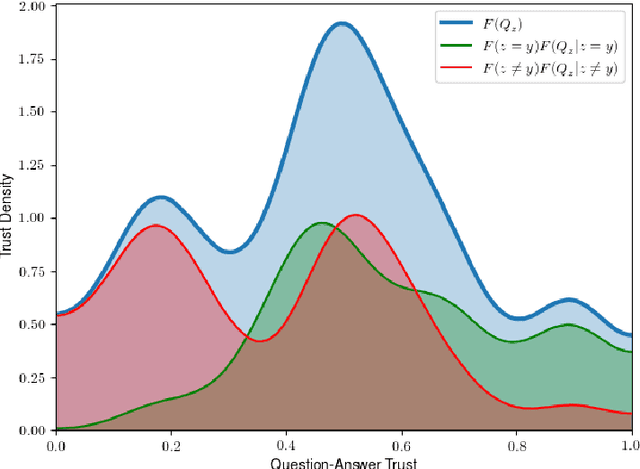
The advances and successes in deep learning in recent years have led to considerable efforts and investments into its widespread ubiquitous adoption for a wide variety of applications, ranging from personal assistants and intelligent navigation to search and product recommendation in e-commerce. With this tremendous rise in deep learning adoption comes questions about the trustworthiness of the deep neural networks that power these applications. Motivated to answer such questions, there has been a very recent interest in trust quantification. In this work, we introduce the concept of trust matrix, a novel trust quantification strategy that leverages the recently introduced question-answer trust metric by Wong et al. to provide deeper, more detailed insights into where trust breaks down for a given deep neural network given a set of questions. More specifically, a trust matrix defines the expected question-answer trust for a given actor-oracle answer scenario, allowing one to quickly spot areas of low trust that needs to be addressed to improve the trustworthiness of a deep neural network. The proposed trust matrix is simple to calculate, humanly interpretable, and to the best of the authors' knowledge is the first to study trust at the actor-oracle answer level. We further extend the concept of trust densities with the notion of conditional trust densities. We experimentally leverage trust matrices to study several well-known deep neural network architectures for image recognition, and further study the trust density and conditional trust densities for an interesting actor-oracle answer scenario. The results illustrate that trust matrices, along with conditional trust densities, can be useful tools in addition to the existing suite of trust quantification metrics for guiding practitioners and regulators in creating and certifying deep learning solutions for trusted operation.
AttendNets: Tiny Deep Image Recognition Neural Networks for the Edge via Visual Attention Condensers
Sep 30, 2020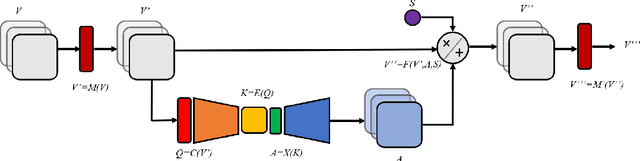
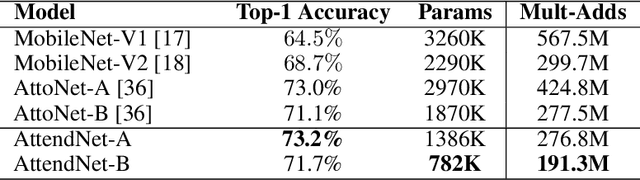
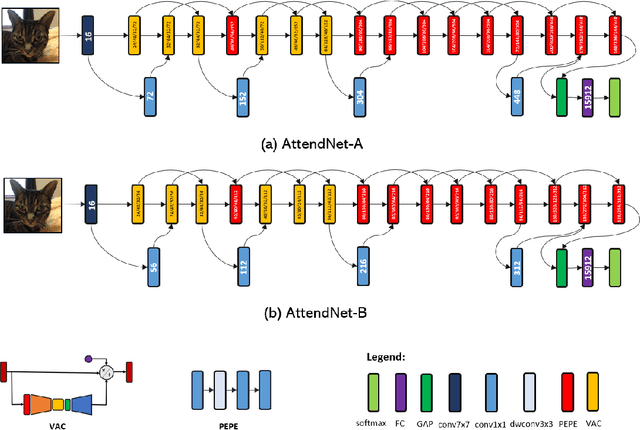
While significant advances in deep learning has resulted in state-of-the-art performance across a large number of complex visual perception tasks, the widespread deployment of deep neural networks for TinyML applications involving on-device, low-power image recognition remains a big challenge given the complexity of deep neural networks. In this study, we introduce AttendNets, low-precision, highly compact deep neural networks tailored for on-device image recognition. More specifically, AttendNets possess deep self-attention architectures based on visual attention condensers, which extends on the recently introduced stand-alone attention condensers to improve spatial-channel selective attention. Furthermore, AttendNets have unique machine-designed macroarchitecture and microarchitecture designs achieved via a machine-driven design exploration strategy. Experimental results on ImageNet$_{50}$ benchmark dataset for the task of on-device image recognition showed that AttendNets have significantly lower architectural and computational complexity when compared to several deep neural networks in research literature designed for efficiency while achieving highest accuracies (with the smallest AttendNet achieving $\sim$7.2% higher accuracy, while requiring $\sim$3$\times$ fewer multiply-add operations, $\sim$4.17$\times$ fewer parameters, and $\sim$16.7$\times$ lower weight memory requirements than MobileNet-V1). Based on these promising results, AttendNets illustrate the effectiveness of visual attention condensers as building blocks for enabling various on-device visual perception tasks for TinyML applications.
How Much Can We Really Trust You? Towards Simple, Interpretable Trust Quantification Metrics for Deep Neural Networks
Sep 20, 2020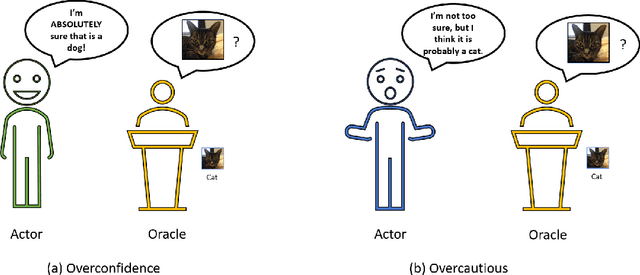

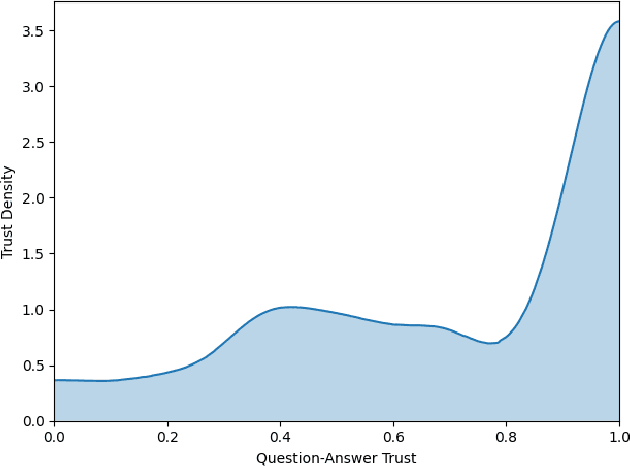
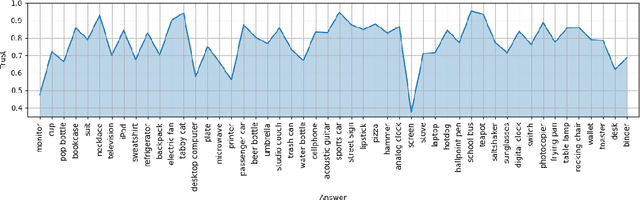
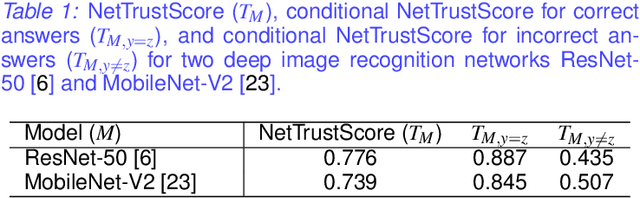
A critical step to building trustworthy deep neural networks is trust quantification, where we ask the question: How much can we trust a deep neural network? In this study, we take a step towards simple, interpretable metrics for trust quantification by introducing a suite of metrics for assessing the overall trustworthiness of deep neural networks based on their behaviour when answering a set of questions. We conduct a thought experiment and explore two key questions about trust in relation to confidence: 1) How much trust do we have in actors who give wrong answers with great confidence? and 2) How much trust do we have in actors who give right answers hesitantly? Based on insights gained, we introduce the concept of question-answer trust to quantify trustworthiness of an individual answer based on confident behaviour under correct and incorrect answer scenarios, and the concept of trust density to characterize the distribution of overall trust for an individual answer scenario. We further introduce the concept of trust spectrum for representing overall trust with respect to the spectrum of possible answer scenarios across correctly and incorrectly answered questions. Finally, we introduce NetTrustScore, a scalar metric summarizing overall trustworthiness. The suite of metrics aligns with past social psychology studies that study the relationship between trust and confidence. Leveraging these metrics, we quantify the trustworthiness of several well-known deep neural network architectures for image recognition to get a deeper understanding of where trust breaks down. The proposed metrics are by no means perfect, but the hope is to push the conversation towards better metrics to help guide practitioners and regulators in producing, deploying, and certifying deep learning solutions that can be trusted to operate in real-world, mission-critical scenarios.
COVIDNet-CT: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest CT Images
Sep 08, 2020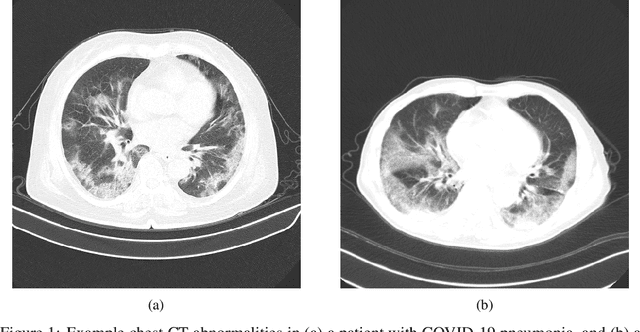

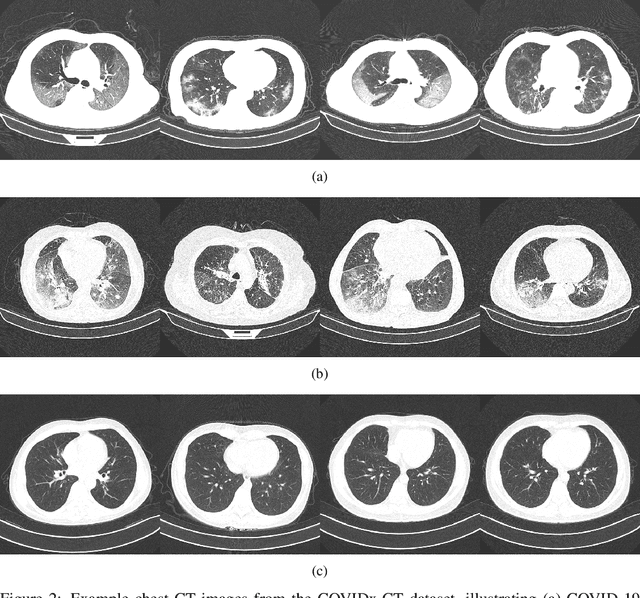
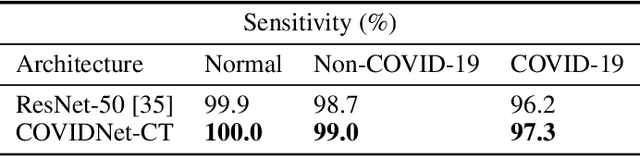
The coronavirus disease 2019 (COVID-19) pandemic continues to have a tremendous impact on patients and healthcare systems around the world. In the fight against this novel disease, there is a pressing need for rapid and effective screening tools to identify patients infected with COVID-19, and to this end CT imaging has been proposed as one of the key screening methods which may be used as a complement to RT-PCR testing, particularly in situations where patients undergo routine CT scans for non-COVID-19 related reasons, patients with worsening respiratory status or developing complications that require expedited care, and patients suspected to be COVID-19-positive but have negative RT-PCR test results. Motivated by this, in this study we introduce COVIDNet-CT, a deep convolutional neural network architecture that is tailored for detection of COVID-19 cases from chest CT images via a machine-driven design exploration approach. Additionally, we introduce COVIDx-CT, a benchmark CT image dataset derived from CT imaging data collected by the China National Center for Bioinformation comprising 104,009 images across 1,489 patient cases. Furthermore, in the interest of reliability and transparency, we leverage an explainability-driven performance validation strategy to investigate the decision-making behaviour of COVIDNet-CT, and in doing so ensure that COVIDNet-CT makes predictions based on relevant indicators in CT images. Both COVIDNet-CT and the COVIDx-CT dataset are available to the general public in an open-source and open access manner as part of the COVID-Net initiative. While COVIDNet-CT is not yet a production-ready screening solution, we hope that releasing the model and dataset will encourage researchers, clinicians, and citizen data scientists alike to leverage and build upon them.
TinySpeech: Attention Condensers for Deep Speech Recognition Neural Networks on Edge Devices
Aug 23, 2020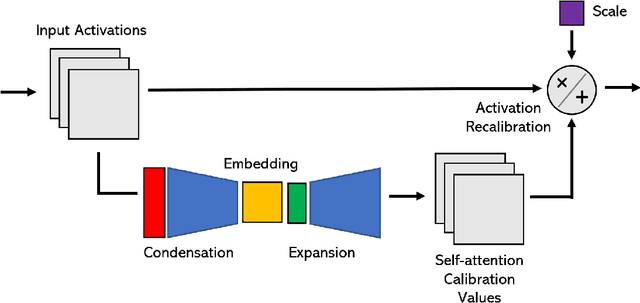

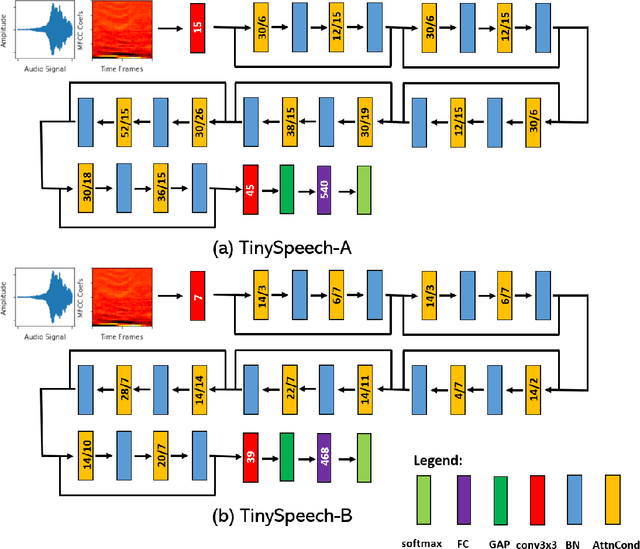
Advances in deep learning have led to state-of-the-art performance across a multitude of speech recognition tasks. Nevertheless, the widespread deployment of deep neural networks for on-device speech recognition remains a challenge, particularly in edge scenarios where the memory and computing resources are highly constrained (e.g., low-power embedded devices) or where the memory and computing budget dedicated to speech recognition is low (e.g., mobile devices performing numerous tasks besides speech recognition). In this study, we introduce the concept of attention condensers for building low-footprint, highly-efficient deep neural networks for on-device speech recognition on the edge. More specifically, an attention condenser is a self-attention mechanism that learns and produces a condensed embedding characterizing joint local and cross-channel activation relationships, and performs selective attention accordingly. To illustrate its efficacy, we introduce TinySpeech, low-precision deep neural networks comprising largely of attention condensers tailored for on-device speech recognition using a machine-driven design exploration strategy. Experimental results on the Google Speech Commands benchmark dataset for limited-vocabulary speech recognition showed that TinySpeech networks achieved significantly lower architectural complexity (as much as $207\times$ fewer parameters) and lower computational complexity (as much as $21\times$ fewer multiply-add operations) when compared to previous deep neural networks in research literature. These results not only demonstrate the efficacy of attention condensers for building highly efficient deep neural networks for on-device speech recognition, but also illuminate its potential for accelerating deep learning on the edge and empowering a wide range of TinyML applications.