 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogos as a Well-Tempered Pre-train for Sign Language Recognition
May 15, 2025



This paper examines two aspects of the isolated sign language recognition (ISLR) task. First, despite the availability of a number of datasets, the amount of data for most individual sign languages is limited. It poses the challenge of cross-language ISLR model training, including transfer learning. Second, similar signs can have different semantic meanings. It leads to ambiguity in dataset labeling and raises the question of the best policy for annotating such signs. To address these issues, this study presents Logos, a novel Russian Sign Language (RSL) dataset, the most extensive ISLR dataset by the number of signers and one of the largest available datasets while also the largest RSL dataset in size and vocabulary. It is shown that a model, pre-trained on the Logos dataset can be used as a universal encoder for other language SLR tasks, including few-shot learning. We explore cross-language transfer learning approaches and find that joint training using multiple classification heads benefits accuracy for the target lowresource datasets the most. The key feature of the Logos dataset is explicitly annotated visually similar sign groups. We show that explicitly labeling visually similar signs improves trained model quality as a visual encoder for downstream tasks. Based on the proposed contributions, we outperform current state-of-the-art results for the WLASL dataset and get competitive results for the AUTSL dataset, with a single stream model processing solely RGB video. The source code, dataset, and pre-trained models are publicly available.
HaGRIDv2: 1M Images for Static and Dynamic Hand Gesture Recognition
Dec 02, 2024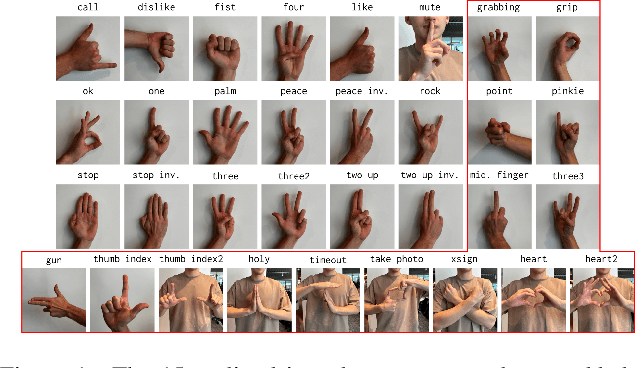
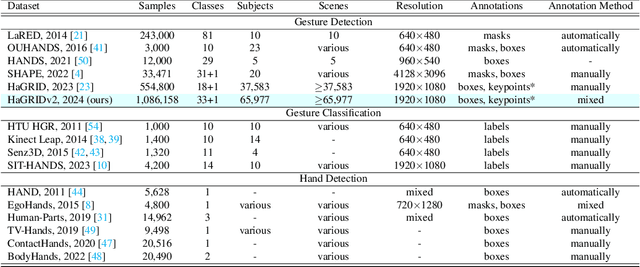
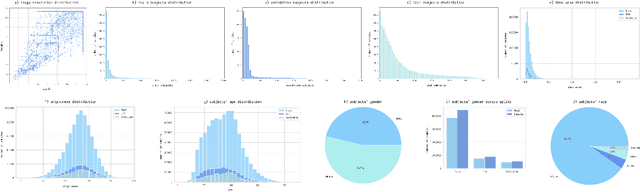
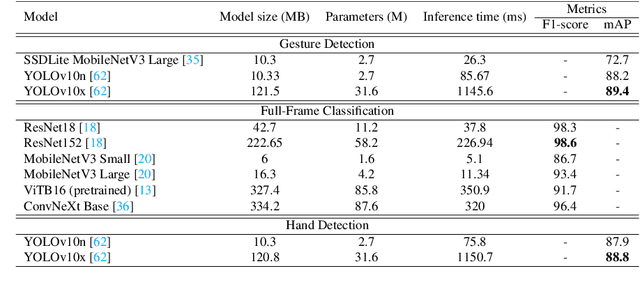
This paper proposes the second version of the widespread Hand Gesture Recognition dataset HaGRID -- HaGRIDv2. We cover 15 new gestures with conversation and control functions, including two-handed ones. Building on the foundational concepts proposed by HaGRID's authors, we implemented the dynamic gesture recognition algorithm and further enhanced it by adding three new groups of manipulation gestures. The ``no gesture" class was diversified by adding samples of natural hand movements, which allowed us to minimize false positives by 6 times. Combining extra samples with HaGRID, the received version outperforms the original in pre-training models for gesture-related tasks. Besides, we achieved the best generalization ability among gesture and hand detection datasets. In addition, the second version enhances the quality of the gestures generated by the diffusion model. HaGRIDv2, pre-trained models, and a dynamic gesture recognition algorithm are publicly available.
Bukva: Russian Sign Language Alphabet
Oct 11, 2024



This paper investigates the recognition of the Russian fingerspelling alphabet, also known as the Russian Sign Language (RSL) dactyl. Dactyl is a component of sign languages where distinct hand movements represent individual letters of a written language. This method is used to spell words without specific signs, such as proper nouns or technical terms. The alphabet learning simulator is an essential isolated dactyl recognition application. There is a notable issue of data shortage in isolated dactyl recognition: existing Russian dactyl datasets lack subject heterogeneity, contain insufficient samples, or cover only static signs. We provide Bukva, the first full-fledged open-source video dataset for RSL dactyl recognition. It contains 3,757 videos with more than 101 samples for each RSL alphabet sign, including dynamic ones. We utilized crowdsourcing platforms to increase the subject's heterogeneity, resulting in the participation of 155 deaf and hard-of-hearing experts in the dataset creation. We use a TSM (Temporal Shift Module) block to handle static and dynamic signs effectively, achieving 83.6% top-1 accuracy with a real-time inference with CPU only. The dataset, demo code, and pre-trained models are publicly available.
Slovo: Russian Sign Language Dataset
May 23, 2023One of the main challenges of the sign language recognition task is the difficulty of collecting a suitable dataset due to the gap between deaf and hearing society. In addition, the sign language in each country differs significantly, which obliges the creation of new data for each of them. This paper presents the Russian Sign Language (RSL) video dataset Slovo, produced using crowdsourcing platforms. The dataset contains 20,000 FullHD recordings, divided into 1,000 classes of RSL gestures received by 194 signers. We also provide the entire dataset creation pipeline, from data collection to video annotation, with the following demo application. Several neural networks are trained and evaluated on the Slovo to demonstrate its teaching ability. Proposed data and pre-trained models are publicly available.