 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning: Progress and Prospects
Dec 08, 2025This Inaugural Lecture was given at Royal Holloway University of London in 1996. It covers an introduction to machine learning and describes various theoretical advances and practical projects in the field. The Lecture here is presented in its original format, but a few remarks have been added in 2025 to reflect recent developments, and the list of references has been updated to enhance the convenience and accuracy for readers. When did machine learning start? Maybe a good starting point is 1949, when Claude Shannon proposed a learning algorithm for chess-playing programs. Or maybe we should go back to the 1930s when Ronald Fisher developed discriminant analysis - a type of learning where the problem is to construct a decision rule that separates two types of vectors. Or could it be the 18th century when David Hume discussed the idea of induction? Or the 14th century, when William of Ockham formulated the principle of "simplicity" known as "Ockham's razor" (Ockham, by the way, is a small village not far from Royal Holloway). Or it may be that, like almost everything else in Western civilisation and culture, the origin of these ideas lies in the Mediterranean. After all, it was Aristotle who said that "we learn some things only by doing things". The field of machine learning has been greatly influenced by other disciplines and the subject is in itself not a very homogeneous discipline, but includes separate, overlapping subfields. There are many parallel lines of research in ML: inductive learning, neural networks, clustering, and theories of learning. They are all part of the more general field of machine learning.
Calibrated Large Language Models for Binary Question Answering
Jul 01, 2024Quantifying the uncertainty of predictions made by large language models (LLMs) in binary text classification tasks remains a challenge. Calibration, in the context of LLMs, refers to the alignment between the model's predicted probabilities and the actual correctness of its predictions. A well-calibrated model should produce probabilities that accurately reflect the likelihood of its predictions being correct. We propose a novel approach that utilizes the inductive Venn--Abers predictor (IVAP) to calibrate the probabilities associated with the output tokens corresponding to the binary labels. Our experiments on the BoolQ dataset using the Llama 2 model demonstrate that IVAP consistently outperforms the commonly used temperature scaling method for various label token choices, achieving well-calibrated probabilities while maintaining high predictive quality. Our findings contribute to the understanding of calibration techniques for LLMs and provide a practical solution for obtaining reliable uncertainty estimates in binary question answering tasks, enhancing the interpretability and trustworthiness of LLM predictions.
Inductive Conformal Martingales for Change-Point Detection
Jun 11, 2017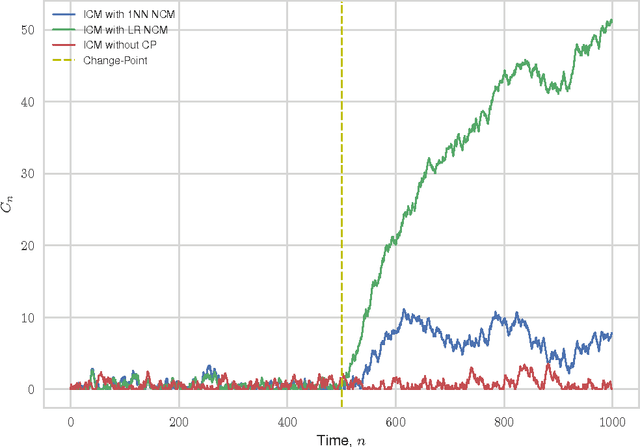

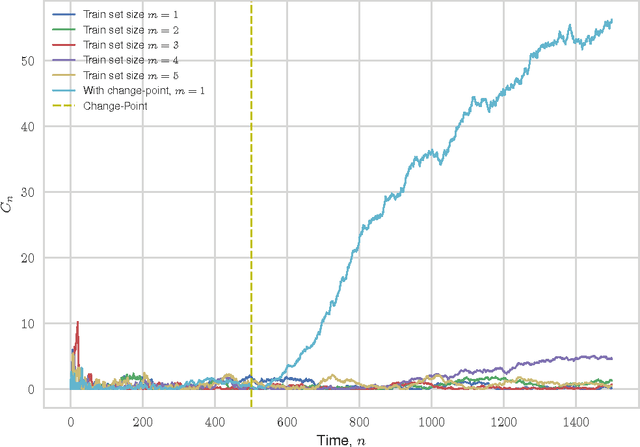

We consider the problem of quickest change-point detection in data streams. Classical change-point detection procedures, such as CUSUM, Shiryaev-Roberts and Posterior Probability statistics, are optimal only if the change-point model is known, which is an unrealistic assumption in typical applied problems. Instead we propose a new method for change-point detection based on Inductive Conformal Martingales, which requires only the independence and identical distribution of observations. We compare the proposed approach to standard methods, as well as to change-point detection oracles, which model a typical practical situation when we have only imprecise (albeit parametric) information about pre- and post-change data distributions. Results of comparison provide evidence that change-point detection based on Inductive Conformal Martingales is an efficient tool, capable to work under quite general conditions unlike traditional approaches.
Conformal Predictors for Compound Activity Prediction
Mar 14, 2016
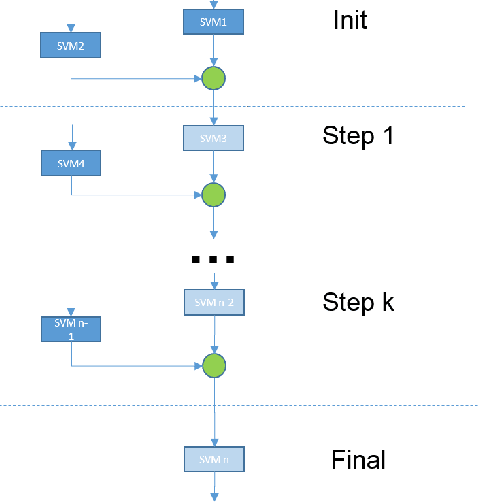

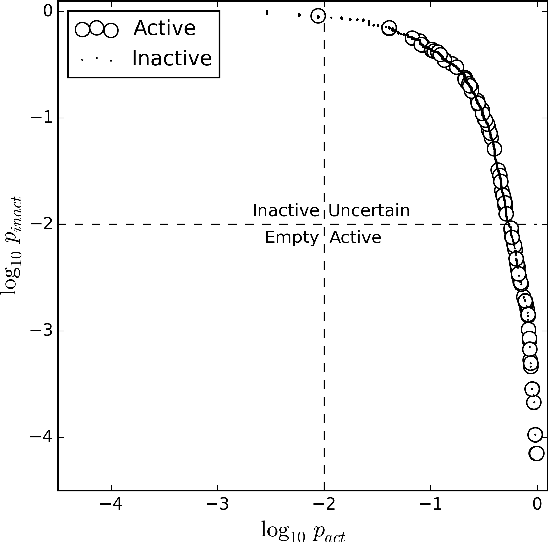
The paper presents an application of Conformal Predictors to a chemoinformatics problem of identifying activities of chemical compounds. The paper addresses some specific challenges of this domain: a large number of compounds (training examples), high-dimensionality of feature space, sparseness and a strong class imbalance. A variant of conformal predictors called Inductive Mondrian Conformal Predictor is applied to deal with these challenges. Results are presented for several non-conformity measures (NCM) extracted from underlying algorithms and different kernels. A number of performance measures are used in order to demonstrate the flexibility of Inductive Mondrian Conformal Predictors in dealing with such a complex set of data. Keywords: Conformal Prediction, Confidence Estimation, Chemoinformatics, Non-Conformity Measure.
Hedging predictions in machine learning
Nov 02, 2006


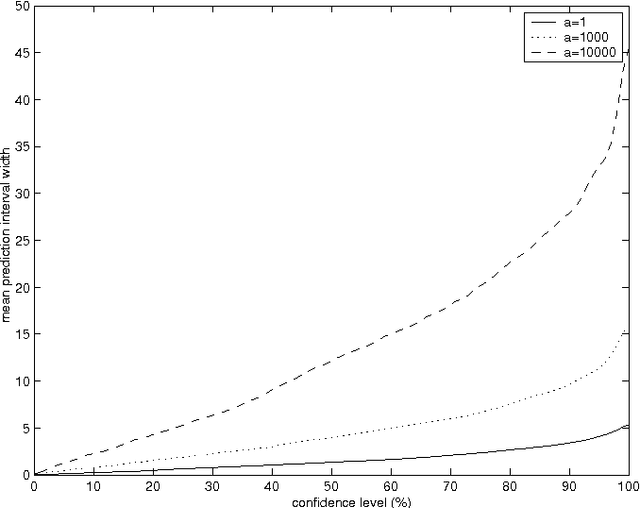
Recent advances in machine learning make it possible to design efficient prediction algorithms for data sets with huge numbers of parameters. This paper describes a new technique for "hedging" the predictions output by many such algorithms, including support vector machines, kernel ridge regression, kernel nearest neighbours, and by many other state-of-the-art methods. The hedged predictions for the labels of new objects include quantitative measures of their own accuracy and reliability. These measures are provably valid under the assumption of randomness, traditional in machine learning: the objects and their labels are assumed to be generated independently from the same probability distribution. In particular, it becomes possible to control (up to statistical fluctuations) the number of erroneous predictions by selecting a suitable confidence level. Validity being achieved automatically, the remaining goal of hedged prediction is efficiency: taking full account of the new objects' features and other available information to produce as accurate predictions as possible. This can be done successfully using the powerful machinery of modern machine learning.
* 24 pages; 9 figures; 2 tables; a version of this paper (with discussion and rejoinder) is to appear in "The Computer Journal"