 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Topological Sorting Criterion for Random Causal Directed Acyclic Graphs
May 07, 2026Random directed acyclic graphs (DAGs) based on imposing an order on Erdős-Rényi and scale free random graphs are widely used for evaluating causal discovery algorithms. We show that in such DAGs, the set of nodes reachable via open paths, termed relatives, increases monotonically along the causal order. We assess the prevalence of this pattern numerically, and demonstrate that it can be exploited for causal order recovery via sorting by the estimated number of relatives. We note that many simulations in the literature feature settings where this yields an excellent proxy for the causal order, and show that a strict increase of relatives along the causal order leads to a singular Markov equivalence class. We propose sampling time-series DAGs as a possible alternative and discuss implications for causal discovery algorithms and their evaluation on synthetic data.
Simple Sorting Criteria Help Find the Causal Order in Additive Noise Models
Mar 31, 2023



Additive Noise Models (ANM) encode a popular functional assumption that enables learning causal structure from observational data. Due to a lack of real-world data meeting the assumptions, synthetic ANM data are often used to evaluate causal discovery algorithms. Reisach et al. (2021) show that, for common simulation parameters, a variable ordering by increasing variance is closely aligned with a causal order and introduce var-sortability to quantify the alignment. Here, we show that not only variance, but also the fraction of a variable's variance explained by all others, as captured by the coefficient of determination $R^2$, tends to increase along the causal order. Simple baseline algorithms can use $R^2$-sortability to match the performance of established methods. Since $R^2$-sortability is invariant under data rescaling, these algorithms perform equally well on standardized or rescaled data, addressing a key limitation of algorithms exploiting var-sortability. We characterize and empirically assess $R^2$-sortability for different simulation parameters. We show that all simulation parameters can affect $R^2$-sortability and must be chosen deliberately to control the difficulty of the causal discovery task and the real-world plausibility of the simulated data. We provide an implementation of the sortability measures and sortability-based algorithms in our library CausalDisco (https://github.com/CausalDisco/CausalDisco).
Beware of the Simulated DAG! Varsortability in Additive Noise Models
Feb 26, 2021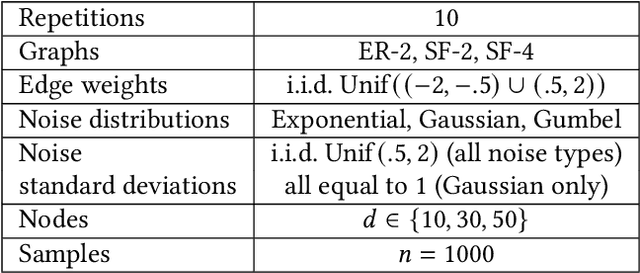
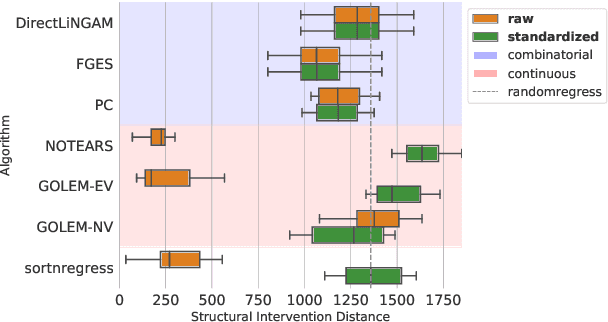
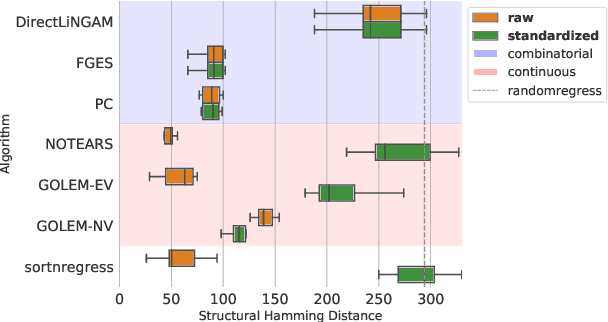
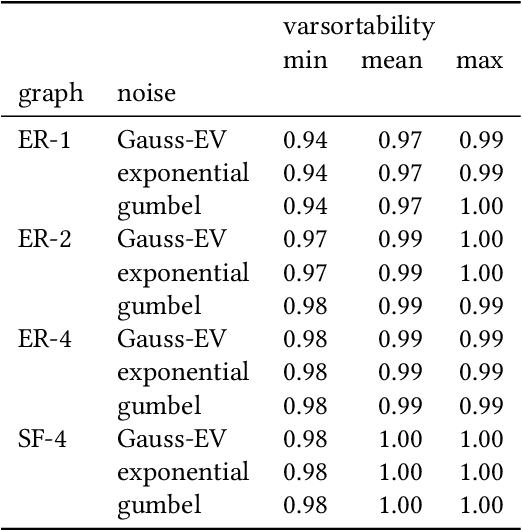
Additive noise models are a class of causal models in which each variable is defined as a function of its causes plus independent noise. In such models, the ordering of variables by marginal variances may be indicative of the causal order. We introduce varsortability as a measure of agreement between the ordering by marginal variance and the causal order. We show how varsortability dominates the performance of continuous structure learning algorithms on synthetic data. On real-world data, varsortability is an implausible and untestable assumption and we find no indication of high varsortability. We aim to raise awareness that varsortability easily occurs in simulated additive noise models. We provide a baseline method that explicitly exploits varsortability and advocate reporting varsortability in benchmarking data.