 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Adversarial Learning for Detecting Unseen Falls
May 19, 2019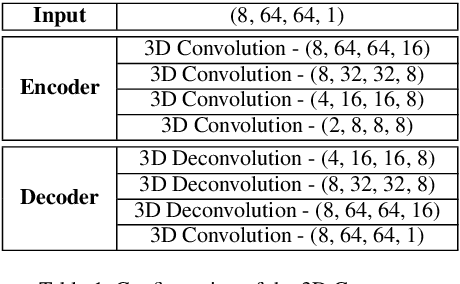
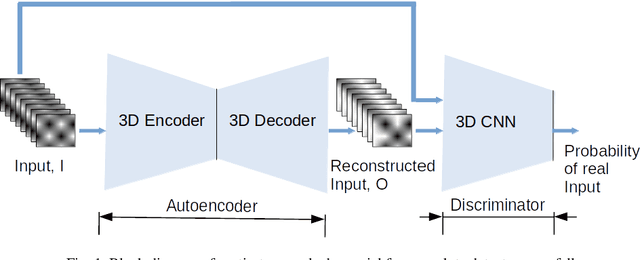

Fall detection is an important problem from both the health and machine learning perspective. A fall can lead to severe injuries, long term impairments or even death in some cases. In terms of machine learning, it presents a severely class imbalance problem with very few or no training data for falls owing to the fact that falls occur rarely. In this paper, we take an alternate philosophy to detect falls in the absence of their training data, by training the classifier on only the normal activities (that are available in abundance) and identifying a fall as an anomaly. To realize such a classifier, we use an adversarial learning framework, which comprises of a spatio-temporal autoencoder for reconstructing input video frames and a spatio-temporal convolution network to discriminate them against original video frames. 3D convolutions are used to learn spatial and temporal features from the input video frames. The adversarial learning of the spatio-temporal autoencoder will enable reconstructing the normal activities of daily living efficiently; thus, rendering detecting unseen falls plausible within this framework. We tested the performance of the proposed framework on camera sensing modalities that may preserve an individual's privacy (fully or partially), such as thermal and depth camera. Our results on three publicly available datasets show that the proposed spatio-temporal adversarial framework performed better than other frame based (or spatial) adversarial learning methods.
Limitations and Biases in Facial Landmark Detection -- An Empirical Study on Older Adults with Dementia
May 17, 2019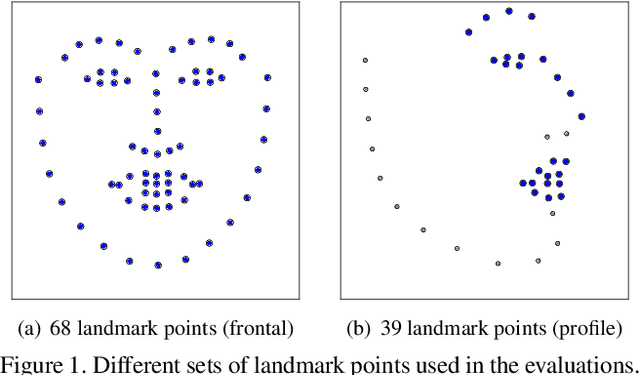
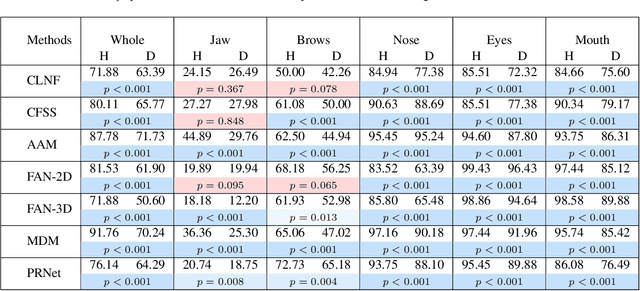
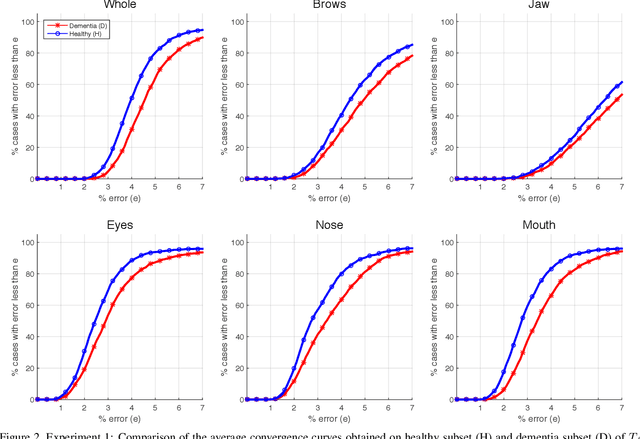
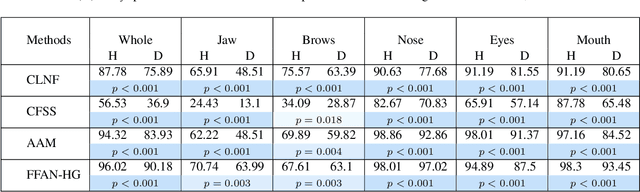
Accurate facial expression analysis is an essential step in various clinical applications that involve physical and mental health assessments of older adults (e.g. diagnosis of pain or depression). Although remarkable progress has been achieved toward developing robust facial landmark detection methods, state-of-the-art methods still face many challenges when encountering uncontrolled environments, different ranges of facial expressions, and different demographics of the population. A recent study has revealed that the health status of individuals can also affect the performance of facial landmark detection methods on front views of faces. In this work, we investigate this matter in a much greater context using seven facial landmark detection methods. We perform our evaluation not only on frontal faces but also on profile faces and in various regions of the face. Our results shed light on limitations of the existing methods and challenges of applying these methods in clinical settings by indicating: 1) a significant difference between the performance of state-of-the-art when tested on the profile or frontal faces of individuals with vs. without dementia; 2) insights on the existing bias for all regions of the face; and 3) the presence of this bias despite re-training/fine-tuning with various configurations of six datasets.
DeepFall -- Non-invasive Fall Detection with Deep Spatio-Temporal Convolutional Autoencoders
Sep 13, 2018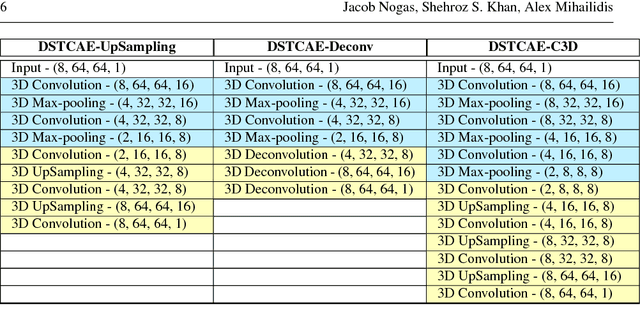
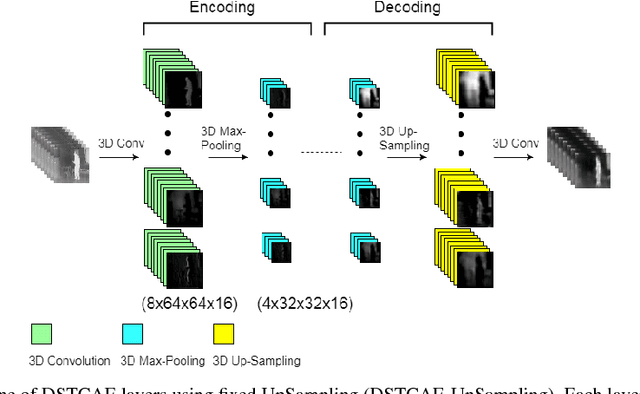
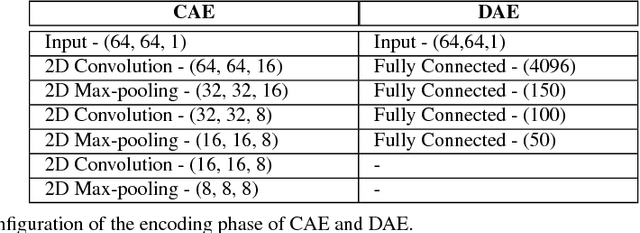
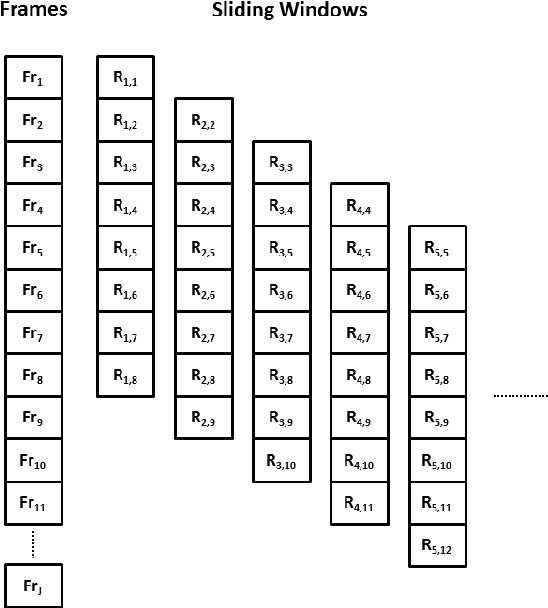
Human falls rarely occur; however, detecting falls is very important from the health and safety perspective. Due to the rarity of falls, it is difficult to employ supervised classification techniques to detect them. Moreover, in these highly skewed situations it is also difficult to extract domain specific features to identify falls. In this paper, we present a novel framework, \textit{DeepFall}, which formulates the fall detection problem as an anomaly detection problem. The \textit{DeepFall} framework presents the novel use of deep spatio-temporal convolutional autoencoders to learn spatial and temporal features from normal activities using non-invasive sensing modalities. We also present a new anomaly scoring method that combines the reconstruction score of frames across a video sequences to detect unseen falls. We tested the \textit{DeepFall} framework on three publicly available datasets collected through non-invasive sensing modalities, thermal camera and depth cameras and show superior results in comparison to traditional autoencoder and convolutional autoencoder methods to identify unseen falls.
Bootstrapping and Multiple Imputation Ensemble Approaches for Missing Data
Feb 06, 2018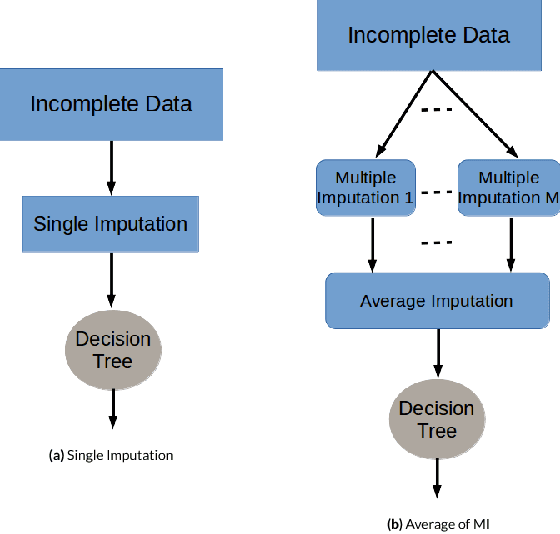

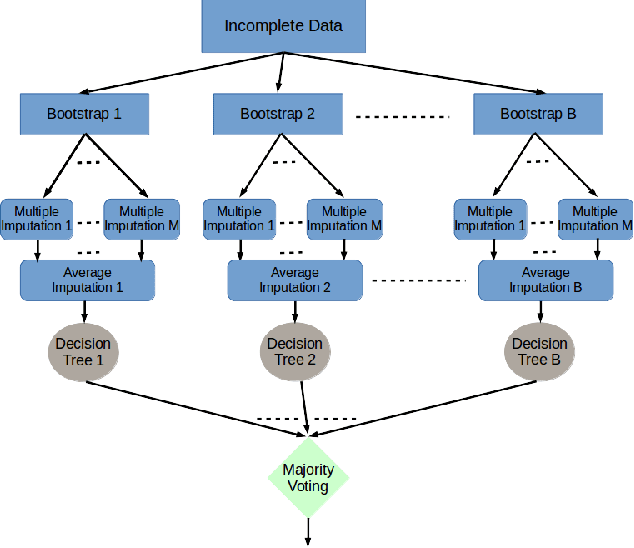

Presence of missing values in a dataset can adversely affect the performance of a classifier. Single and Multiple Imputation are normally performed to fill in the missing values. In this paper, we present several variants of combining single and multiple imputation with bootstrapping to create ensembles that can model uncertainty and diversity in the data, and that are robust to high missingness in the data. We present three ensemble strategies: bootstrapping on incomplete data followed by (i) single imputation and (ii) multiple imputation, and (iii) multiple imputation ensemble without bootstrapping. We perform an extensive evaluation of the performance of the these ensemble strategies on 8 datasets by varying the missingness ratio. Our results show that bootstrapping followed by multiple imputation using expectation maximization is the most robust method even at high missingness ratio (up to 30%). For small missingness ratio (up to 10%) most of the ensemble methods perform quivalently but better than single imputation. Kappa-error plots suggest that accurate classifiers with reasonable diversity is the reason for this behaviour. A consistent observation in all the datasets suggests that for small missingness (up to 10%), bootstrapping on incomplete data without any imputation produces equivalent results to other ensemble methods.
Depth image hand tracking from an overhead perspective using partially labeled, unbalanced data: Development and real-world testing
Sep 06, 2014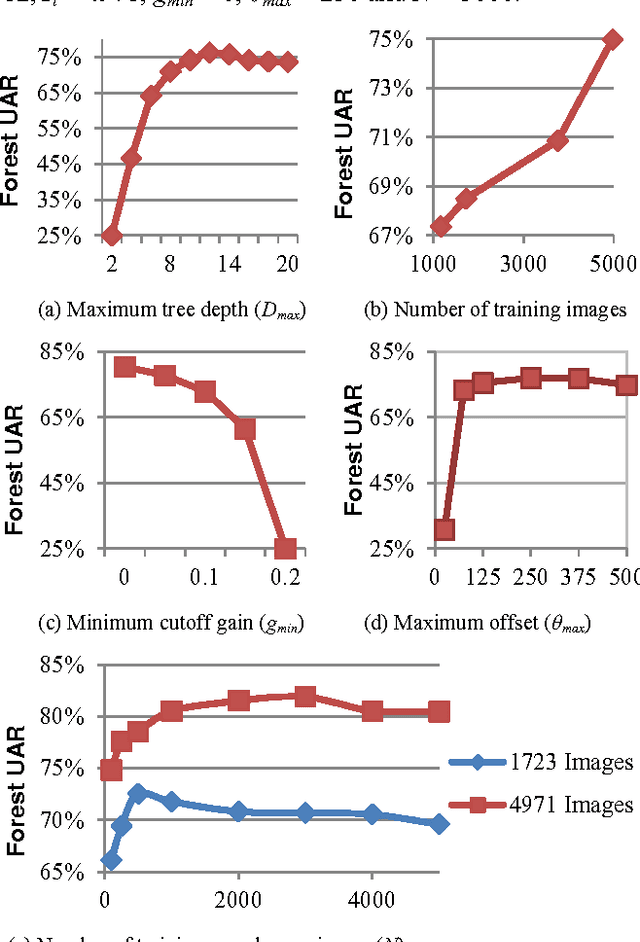
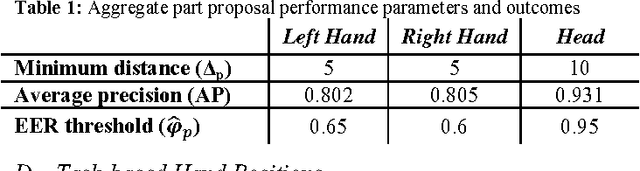
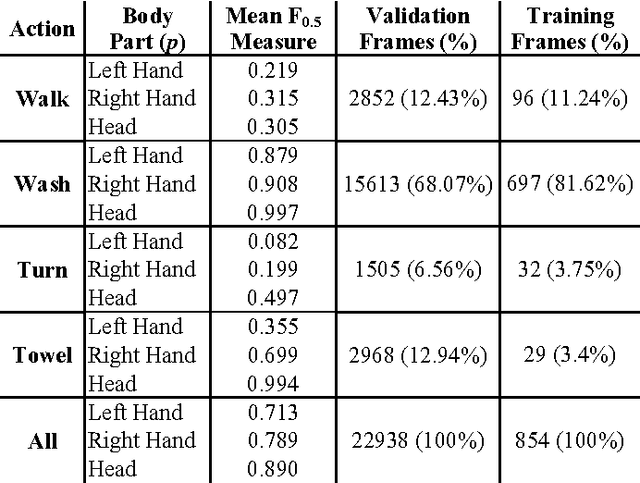
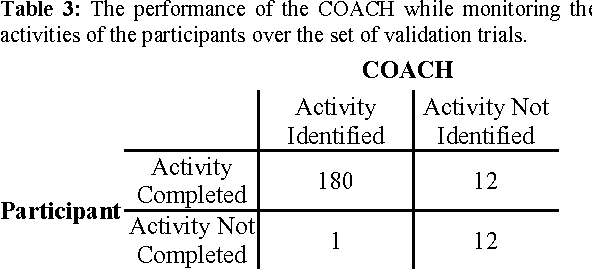
We present the development and evaluation of a hand tracking algorithm based on single depth images captured from an overhead perspective for use in the COACH prompting system. We train a random decision forest body part classifier using approximately 5,000 manually labeled, unbalanced, partially labeled training images. The classifier represents a random subset of pixels in each depth image with a learned probability density function across all trained body parts. A local mode-find approach is used to search for clusters present in the underlying feature space sampled by the classified pixels. In each frame, body part positions are chosen as the mode with the highest confidence. User hand positions are translated into hand washing task actions based on proximity to environmental objects. We validate the performance of the classifier and task action proposals on a large set of approximately 24,000 manually labeled images.
Relational Approach to Knowledge Engineering for POMDP-based Assistance Systems as a Translation of a Psychological Model
Jun 25, 2012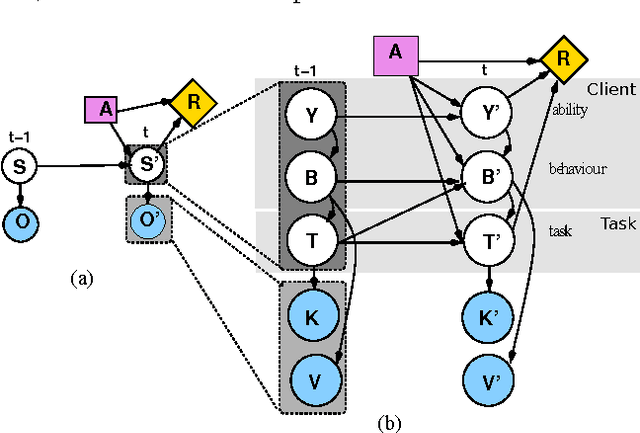
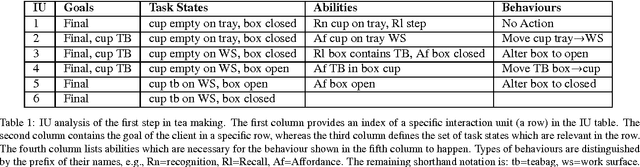
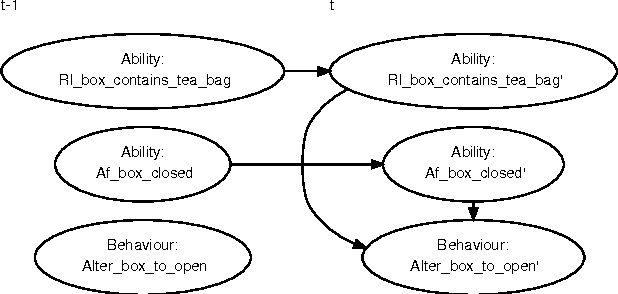
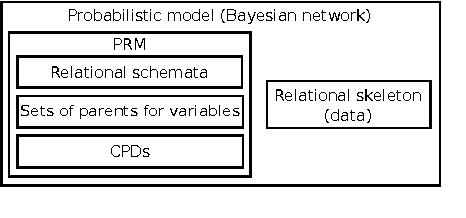
Assistive systems for persons with cognitive disabilities (e.g. dementia) are difficult to build due to the wide range of different approaches people can take to accomplishing the same task, and the significant uncertainties that arise from both the unpredictability of client's behaviours and from noise in sensor readings. Partially observable Markov decision process (POMDP) models have been used successfully as the reasoning engine behind such assistive systems for small multi-step tasks such as hand washing. POMDP models are a powerful, yet flexible framework for modelling assistance that can deal with uncertainty and utility. Unfortunately, POMDPs usually require a very labour intensive, manual procedure for their definition and construction. Our previous work has described a knowledge driven method for automatically generating POMDP activity recognition and context sensitive prompting systems for complex tasks. We call the resulting POMDP a SNAP (SyNdetic Assistance Process). The spreadsheet-like result of the analysis does not correspond to the POMDP model directly and the translation to a formal POMDP representation is required. To date, this translation had to be performed manually by a trained POMDP expert. In this paper, we formalise and automate this translation process using a probabilistic relational model (PRM) encoded in a relational database. We demonstrate the method by eliciting three assistance tasks from non-experts. We validate the resulting POMDP models using case-based simulations to show that they are reasonable for the domains. We also show a complete case study of a designer specifying one database, including an evaluation in a real-life experiment with a human actor.