 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs (Selective) Round-To-Nearest Quantization All You Need?
May 21, 2025Quantization became a necessary tool for serving ever-increasing Large Language Models (LLMs). RTN (Round-to-Nearest) is perhaps the simplest quantization technique that has been around well before LLMs surged to the forefront of machine learning (ML) research. Yet, it has been largely dismissed by recent and more advanced quantization methods that claim superiority over RTN in nearly every aspect of performance. This work aims to dispel this established point of view, showing that RTN is not only much cheaper to apply, but also its token generation throughput can be better than and accuracy can be similar to more advanced alternatives. In particular, we discuss our implementation of RTN based on the recent Marlin kernels and demonstrate how the accuracy of RTN can be gradually improved by selectively increasing the data precision format of certain model layers and modules. Based on our results, we argue that RTN presents a viable and practical choice for quantizing LLMs.
Improving Inference Performance of Machine Learning with the Divide-and-Conquer Principle
Jan 12, 2023Many popular machine learning models scale poorly when deployed on CPUs. In this paper we explore the reasons why and propose a simple, yet effective approach based on the well-known Divide-and-Conquer Principle to tackle this problem of great practical importance. Given an inference job, instead of using all available computing resources (i.e., CPU cores) for running it, the idea is to break the job into independent parts that can be executed in parallel, each with the number of cores according to its expected computational cost. We implement this idea in the popular OnnxRuntime framework and evaluate its effectiveness with several use cases, including the well-known models for optical character recognition (PaddleOCR) and natural language processing (BERT).
Optimizing Inference Performance of Transformers on CPUs
Feb 22, 2021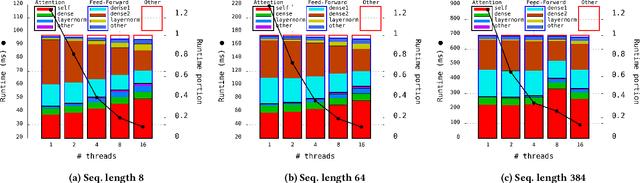
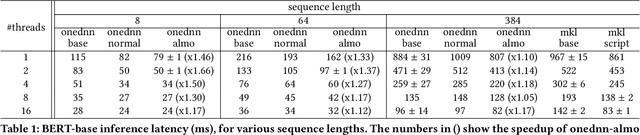
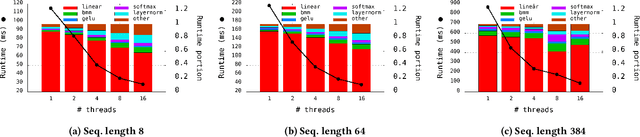
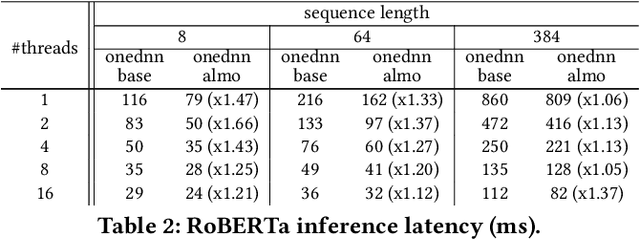
The Transformer architecture revolutionized the field of natural language processing (NLP). Transformers-based models (e.g., BERT) power many important Web services, such as search, translation, question-answering, etc. While enormous research attention is paid to the training of those models, relatively little efforts are made to improve their inference performance. This paper comes to address this gap by presenting an empirical analysis of scalability and performance of inferencing a Transformer-based model on CPUs. Focusing on the highly popular BERT model, we identify key components of the Transformer architecture where the bulk of the computation happens, and propose three optimizations to speed them up. The optimizations are evaluated using the inference benchmark from HuggingFace, and are shown to achieve the speedup of up to x2.37. The considered optimizations do not require any changes to the implementation of the models nor affect their accuracy.