 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Overview and Discussion on Using Large Language Models for Implementation Generation of Solutions to Open-Ended Problems
Jan 03, 2025Large Language Models offer new opportunities to devise automated implementation generation methods that can tackle problem solving activities beyond traditional methods, which require algorithmic specifications and can use only static domain knowledge, like performance metrics and libraries of basic building blocks. Large Language Models could support creating new methods to support problem solving activities for open-ended problems, like problem framing, exploring possible solving approaches, feature elaboration and combination, more advanced implementation assessment, and handling unexpected situations. This report summarized the current work on Large Language Models, including model prompting, Reinforcement Learning, and Retrieval-Augmented Generation. Future research requirements were also discussed.
An Overview and Discussion of the Suitability of Existing Speech Datasets to Train Machine Learning Models for Collective Problem Solving
Dec 24, 2024This report characterized the suitability of existing datasets for devising new Machine Learning models, decision making methods, and analysis algorithms to improve Collaborative Problem Solving and then enumerated requirements for future datasets to be devised. Problem solving was assumed to be performed in teams of about three, four members, which talked to each other. A dataset consists of the speech recordings of such teams. The characterization methodology was based on metrics that capture cognitive, social, and emotional activities and situations. The report presented the analysis of a large group of datasets developed for Spoken Language Understanding, a research area with some similarity to Collaborative Problem Solving.
A Large Language Model-based Computational Approach to Improve Identity-Related Write-Ups
Dec 27, 2023Creating written products is essential to modern life, including writings about one's identity and personal experiences. However, writing is often a difficult activity that requires extensive effort to frame the central ideas, the pursued approach to communicate the central ideas, e.g., using analogies, metaphors, or other possible means, the needed presentation structure, and the actual verbal expression. Large Language Models, a recently emerged approach in Machine Learning, can offer a significant help in reducing the effort and improving the quality of written products. This paper proposes a new computational approach to explore prompts that given as inputs to a Large Language Models can generate cues to improve the considered written products. Two case studies on improving write-ups, one based on an analogy and one on a metaphor, are also presented in the paper.
A Novel Representation to Improve Team Problem Solving in Real-Time
Oct 30, 2023This paper proposes a novel representation to support computing metrics that help understanding and improving in real-time a team's behavior during problem solving in real-life. Even though teams are important in modern activities, there is little computing aid to improve their activity. The representation captures the different mental images developed, enhanced, and utilized during solving. A case study illustrates the representation.
diaLogic: Non-Invasive Speaker-Focused Data Acquisition for Team Behavior Modeling
Sep 01, 2022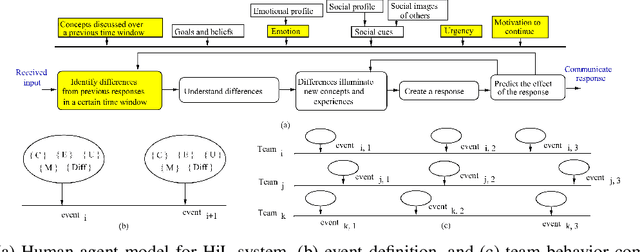
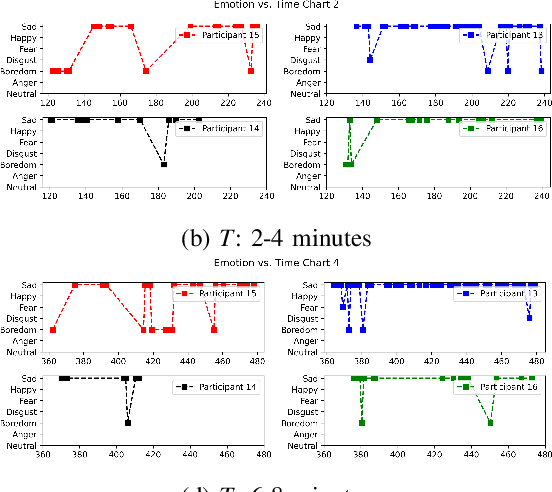
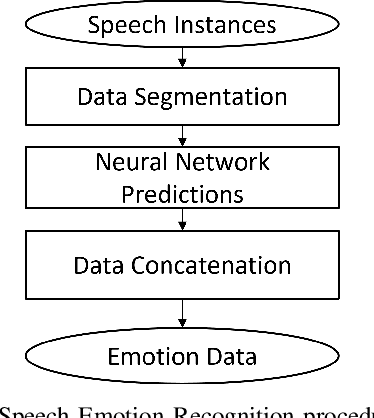
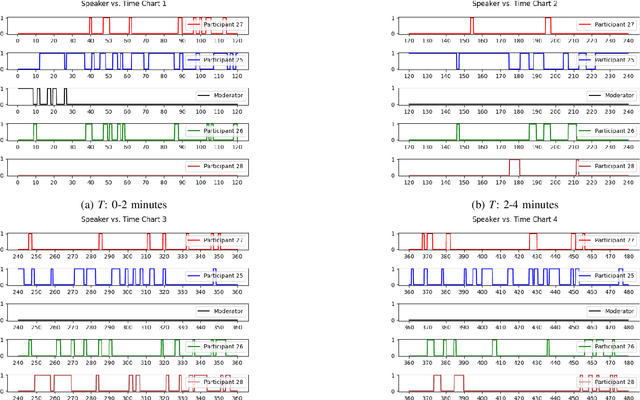
This paper presents diaLogic system, a Human-In-A-Loop system for modeling the behavior of teams during solving open-ended problems. Team behavior is modeled through the hypotheses extracted from features computed from acquired voice data. These features include speaker interactions, speaker emotions, fundamental frequencies, and the corresponding text and clauses. Hypotheses about the invariant and differentiated situations are found based on the similarities and dissimilarities of the behavior of teams over time. To provide full automation of data acquisition, the diaLogic system is executed within an intuitive, user-friendly GUI interface. Experiments present the performance of the system for a broad set of cases featuring team behavior during problem solving.
Dynamic Diagnosis of the Progress and Shortcomings of Student Learning using Machine Learning based on Cognitive, Social, and Emotional Features
Apr 13, 2022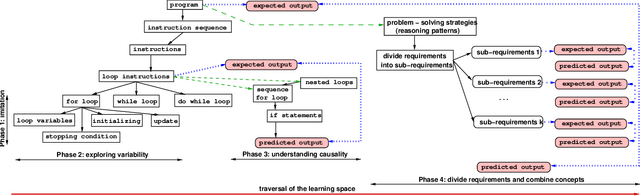
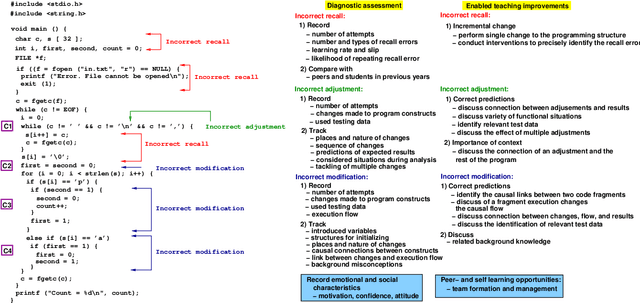
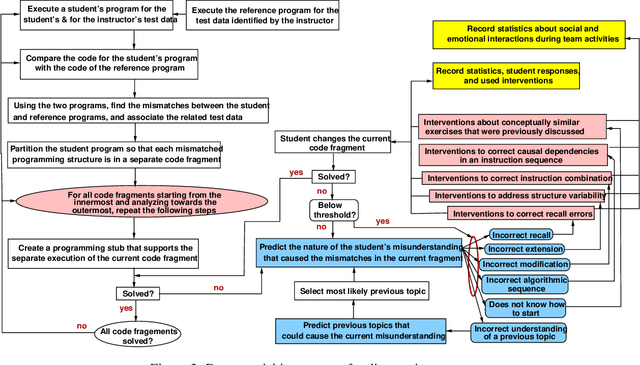
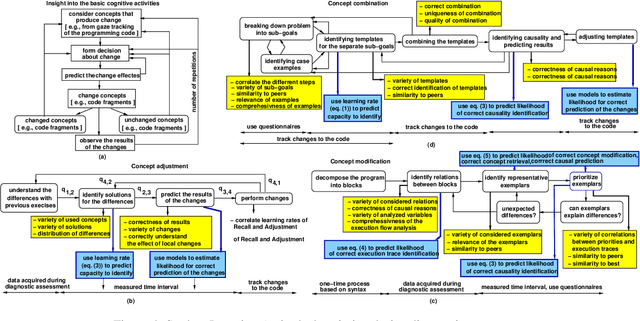
Student diversity, like academic background, learning styles, career and life goals, ethnicity, age, social and emotional characteristics, course load and work schedule, offers unique opportunities in education, like learning new skills, peer mentoring and example setting. But student diversity can be challenging too as it adds variability in the way in which students learn and progress over time. A single teaching approach is likely to be ineffective and result in students not meeting their potential. Automated support could address limitations of traditional teaching by continuously assessing student learning and implementing needed interventions. This paper discusses a novel methodology based on data analytics and Machine Learning to measure and causally diagnose the progress and shortcomings of student learning, and then utilizes the insight gained on individuals to optimize learning. Diagnosis pertains to dynamic diagnostic formative assessment, which aims to uncover the causes of learning shortcomings. The methodology groups learning difficulties into four categories: recall from memory, concept adjustment, concept modification, and problem decomposition into sub-goals (sub-problems) and concept combination. Data models are predicting the occurrence of each of the four challenge types, as well as a student's learning trajectory. The models can be used to automatically create real-time, student-specific interventions (e.g., learning cues) to address less understood concepts. We envision that the system will enable new adaptive pedagogical approaches to unleash student learning potential through customization of the course material to the background, abilities, situation, and progress of each student; and leveraging diversity-related learning experiences.
How Deep is Your Art: An Experimental Study on the Limits of Artistic Understanding in a Single-Task, Single-Modality Neural Network
Apr 01, 2022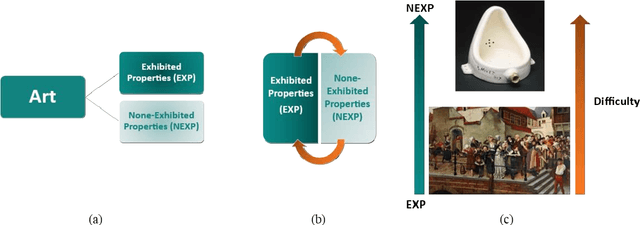
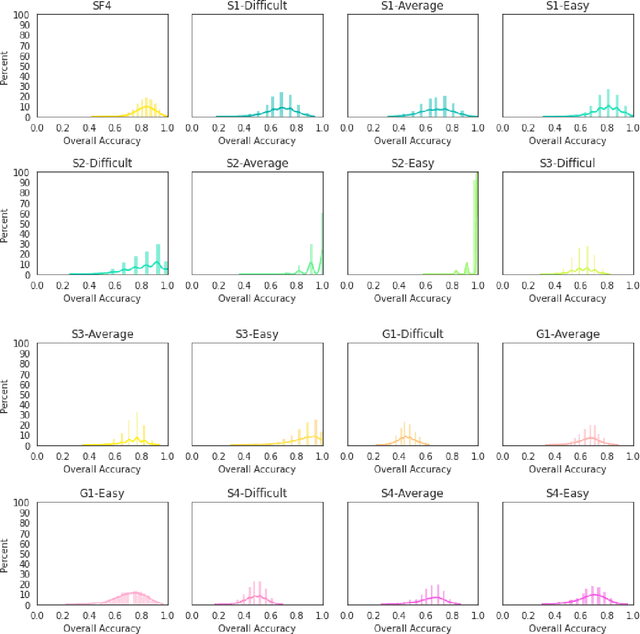
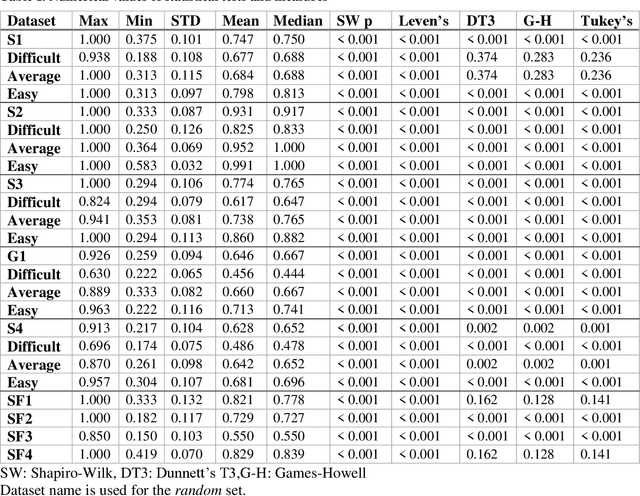
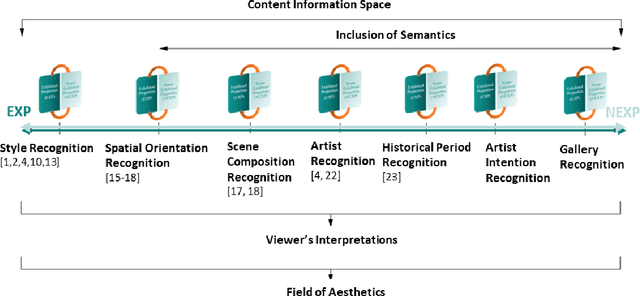
Mathematical modeling and aesthetic rule extraction of works of art are complex activities. This is because art is a multidimensional, subjective discipline. Perception and interpretation of art are, to many extents, relative and open-ended rather than measurable. Following the explainable Artificial Intelligence paradigm, this paper investigated in a human-understandable fashion the limits to which a single-task, single-modality benchmark computer vision model performs in classifying contemporary 2D visual arts. It is important to point out that this work does not introduce an interpreting method to open the black box of Deep Neural Networks, instead it uses existing evaluating metrics derived from the confusion matrix to try to uncover the mechanism with which Deep Neural Networks understand art. To achieve so, VGG-11, pre-trained on ImageNet and discriminatively fine-tuned, was used on handcrafted small-data datasets designed from real-world photography gallery shows. We demonstrated that the artwork's Exhibited Properties or formal factors such as shape and color, rather than Non-Exhibited Properties or content factors such as history and intention, have much higher potential to be the determinant when art pieces have very similar Exhibited Properties. We also showed that a single-task and single-modality model's understanding of art is inadequate as it largely ignores Non-Exhibited Properties.