 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Label Resynthesized Audio: The Dual Role of Neural Audio Codecs in Audio Deepfake Detection
Feb 18, 2026Since Text-to-Speech systems typically don't produce waveforms directly, recent spoof detection studies use resynthesized waveforms from vocoders and neural audio codecs to simulate an attacker. Unlike vocoders, which are specifically designed for speech synthesis, neural audio codecs were originally developed for compressing audio for storage and transmission. However, their ability to discretize speech also sparked interest in language-modeling-based speech synthesis. Owing to this dual functionality, codec resynthesized data may be labeled as either bonafide or spoof. So far, very little research has addressed this issue. In this study, we present a challenging extension of the ASVspoof 5 dataset constructed for this purpose. We examine how different labeling choices affect detection performance and provide insights into labeling strategies.
VRAIN-UPV MLLP's system for the Blizzard Challenge 2021
Oct 29, 2021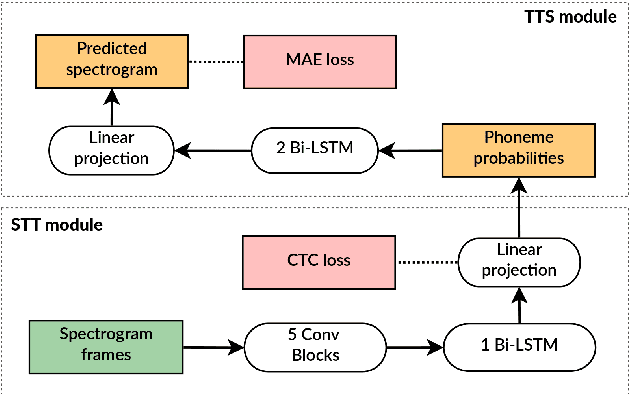
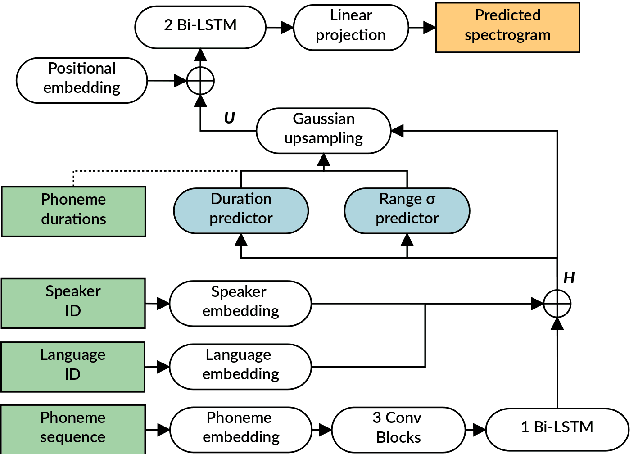

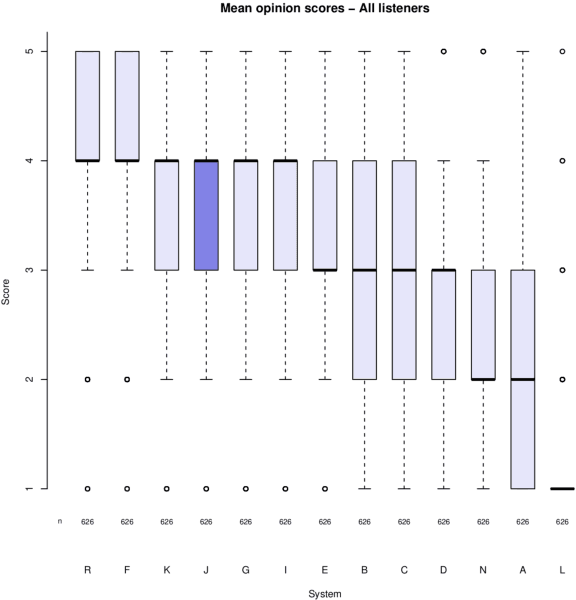
This paper presents the VRAIN-UPV MLLP's speech synthesis system for the SH1 task of the Blizzard Challenge 2021. The SH1 task consisted in building a Spanish text-to-speech system trained on (but not limited to) the corpus released by the Blizzard Challenge 2021 organization. It included 5 hours of studio-quality recordings from a native Spanish female speaker. In our case, this dataset was solely used to build a two-stage neural text-to-speech pipeline composed of a non-autoregressive acoustic model with explicit duration modeling and a HiFi-GAN neural vocoder. Our team is identified as J in the evaluation results. Our system obtained very good results in the subjective evaluation tests. Only one system among other 11 participants achieved better naturalness than ours. Concretely, it achieved a naturalness MOS of 3.61 compared to 4.21 for real samples.