 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Graph Attention for Routing and Wavelength Assignment with Lightpath Reuse
Feb 20, 2025



Many works have investigated reinforcement learning (RL) for routing and spectrum assignment on flex-grid networks but only one work to date has examined RL for fixed-grid with flex-rate transponders, despite production systems using this paradigm. Flex-rate transponders allow existing lightpaths to accommodate new services, a task we term routing and wavelength assignment with lightpath reuse (RWA-LR). We re-examine this problem and present a thorough benchmarking of heuristic algorithms for RWA-LR, which are shown to have 6% increased throughput when candidate paths are ordered by number of hops, rather than total length. We train an RL agent for RWA-LR with graph attention networks for the policy and value functions to exploit the graph-structured data. We provide details of our methodology and open source all of our code for reproduction. We outperform the previous state-of-the-art RL approach by 2.5% (17.4 Tbps mean additional throughput) and the best heuristic by 1.2% (8.5 Tbps mean additional throughput). This marginal gain highlights the difficulty in learning effective RL policies on long horizon resource allocation tasks.
Resource Allocation in Multicore Elastic Optical Networks: A Deep Reinforcement Learning Approach
Jul 05, 2022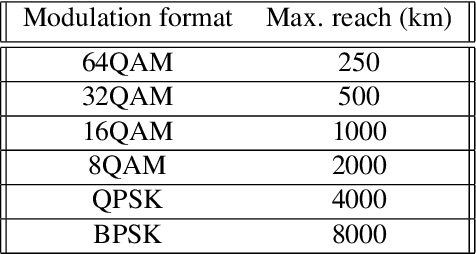
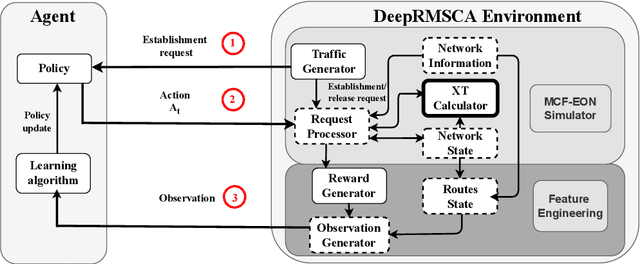
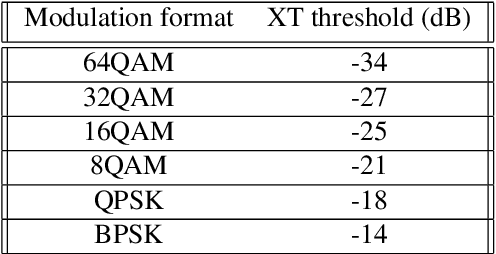
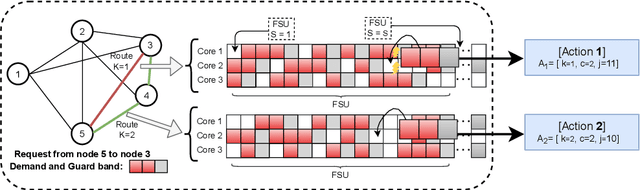
A deep reinforcement learning approach is applied, for the first time, to solve the routing, modulation, spectrum and core allocation (RMSCA) problem in dynamic multicore fiber elastic optical networks (MCF-EONs). To do so, a new environment - compatible with OpenAI's Gym - was designed and implemented to emulate the operation of MCF-EONs. The new environment processes the agent actions (selection of route, core and spectrum slot) by considering the network state and physical-layer-related aspects. The latter includes the available modulation formats and their reach and the inter-core crosstalk (XT), an MCF-related impairment. If the resulting quality of the signal is acceptable, the environment allocates the resources selected by the agent. After processing the agent's action, the environment is configured to give the agent a numerical reward and information about the new network state. The blocking performance of four different agents was compared through simulation to 3 baseline heuristics used in MCF-EONs. Results obtained for the NSFNet and COST239 network topologies show that the best-performing agent achieves, on average, up to a four-times decrease in blocking probability concerning the best-performing baseline heuristic methods.