 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond standard benchmarks: Parameterizing performance evaluation in visual object tracking
Mar 25, 2017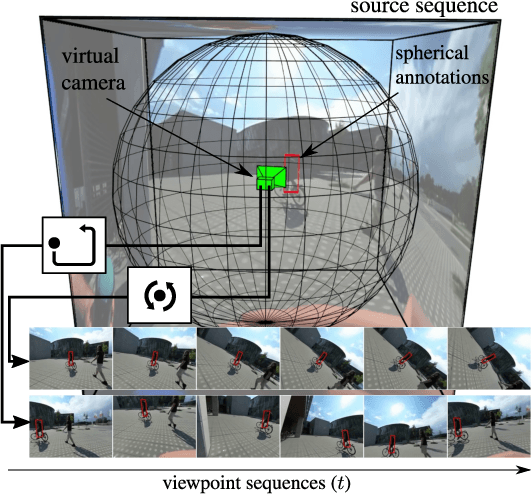
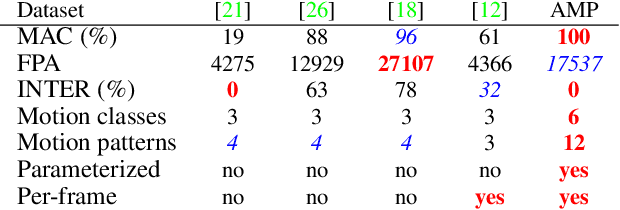
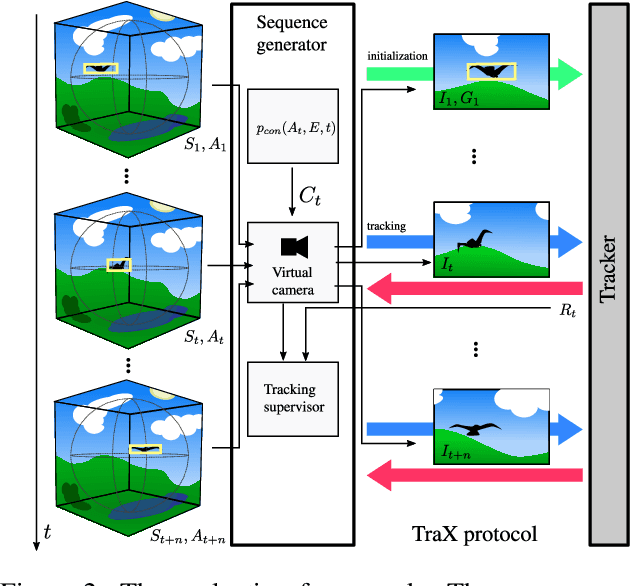
Object-to-camera motion produces a variety of apparent motion patterns that significantly affect performance of short-term visual trackers. Despite being crucial for designing robust trackers, their influence is poorly explored in standard benchmarks due to weakly defined, biased and overlapping attribute annotations. In this paper we propose to go beyond pre-recorded benchmarks with post-hoc annotations by presenting an approach that utilizes omnidirectional videos to generate realistic, consistently annotated, short-term tracking scenarios with exactly parameterized motion patterns. We have created an evaluation system, constructed a fully annotated dataset of omnidirectional videos and the generators for typical motion patterns. We provide an in-depth analysis of major tracking paradigms which is complementary to the standard benchmarks and confirms the expressiveness of our evaluation approach.
Visual Stability Prediction and Its Application to Manipulation
Sep 26, 2016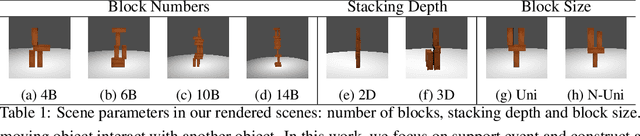
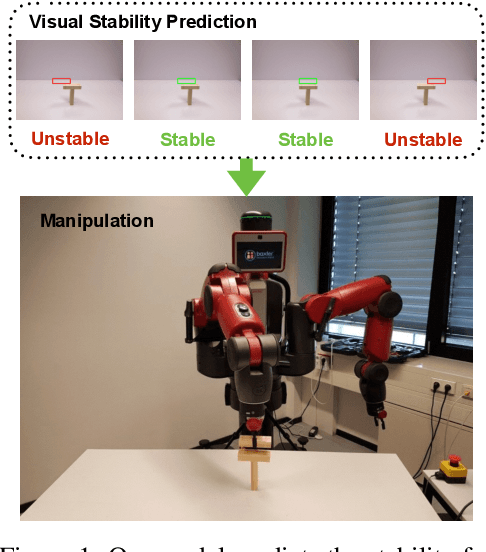
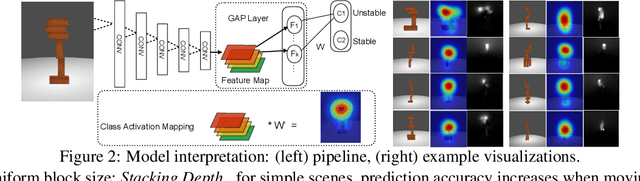

Understanding physical phenomena is a key competence that enables humans and animals to act and interact under uncertain perception in previously unseen environments containing novel objects and their configurations. Developmental psychology has shown that such skills are acquired by infants from observations at a very early stage. In this paper, we contrast a more traditional approach of taking a model-based route with explicit 3D representations and physical simulation by an {\em end-to-end} approach that directly predicts stability from appearance. We ask the question if and to what extent and quality such a skill can directly be acquired in a data-driven way---bypassing the need for an explicit simulation at run-time. We present a learning-based approach based on simulated data that predicts stability of towers comprised of wooden blocks under different conditions and quantities related to the potential fall of the towers. We first evaluate the approach on synthetic data and compared the results to human judgments on the same stimuli. Further, we extend this approach to reason about future states of such towers that in turn enables successful stacking.
Towards Deep Compositional Networks
Sep 13, 2016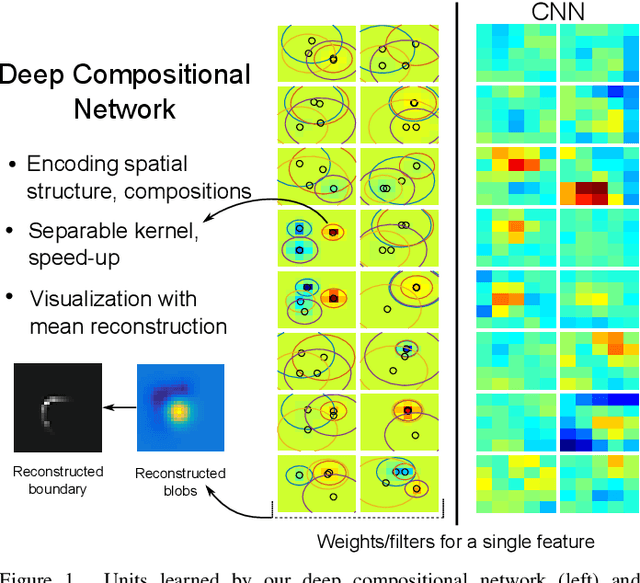
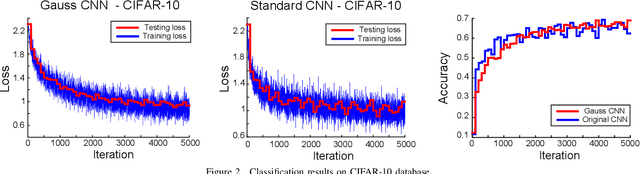
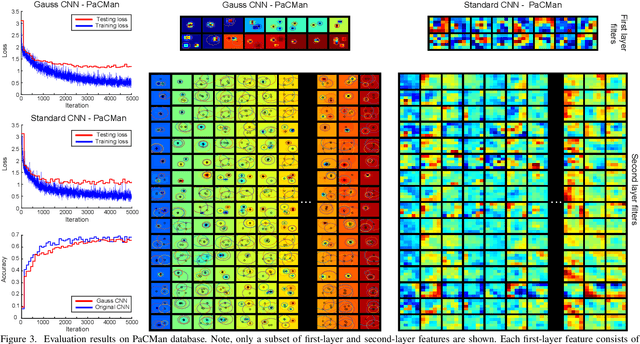
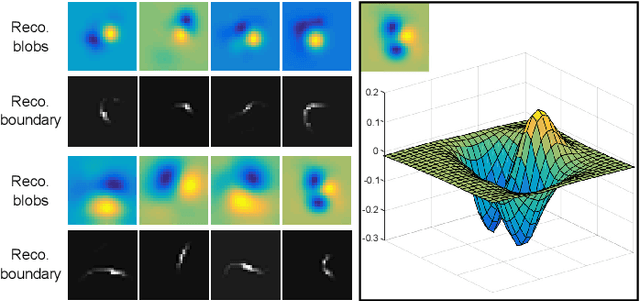
Hierarchical feature learning based on convolutional neural networks (CNN) has recently shown significant potential in various computer vision tasks. While allowing high-quality discriminative feature learning, the downside of CNNs is the lack of explicit structure in features, which often leads to overfitting, absence of reconstruction from partial observations and limited generative abilities. Explicit structure is inherent in hierarchical compositional models, however, these lack the ability to optimize a well-defined cost function. We propose a novel analytic model of a basic unit in a layered hierarchical model with both explicit compositional structure and a well-defined discriminative cost function. Our experiments on two datasets show that the proposed compositional model performs on a par with standard CNNs on discriminative tasks, while, due to explicit modeling of the structure in the feature units, affording a straight-forward visualization of parts and faster inference due to separability of the units. Actions
To Fall Or Not To Fall: A Visual Approach to Physical Stability Prediction
Mar 31, 2016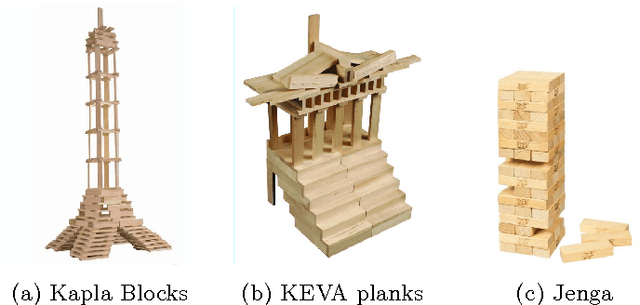
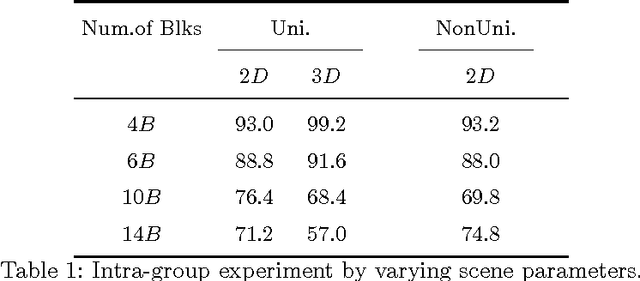
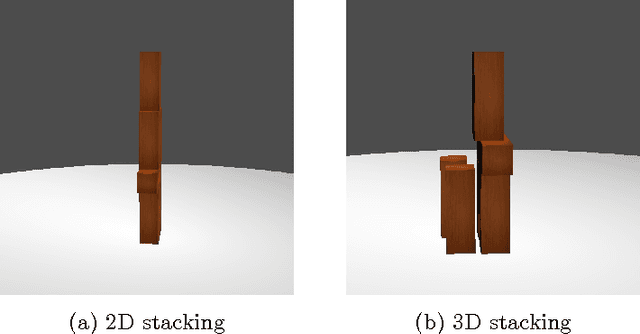
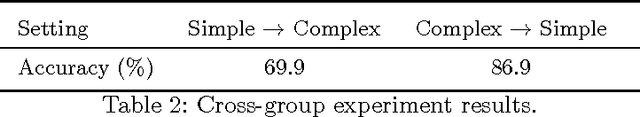
Understanding physical phenomena is a key competence that enables humans and animals to act and interact under uncertain perception in previously unseen environments containing novel object and their configurations. Developmental psychology has shown that such skills are acquired by infants from observations at a very early stage. In this paper, we contrast a more traditional approach of taking a model-based route with explicit 3D representations and physical simulation by an end-to-end approach that directly predicts stability and related quantities from appearance. We ask the question if and to what extent and quality such a skill can directly be acquired in a data-driven way bypassing the need for an explicit simulation. We present a learning-based approach based on simulated data that predicts stability of towers comprised of wooden blocks under different conditions and quantities related to the potential fall of the towers. The evaluation is carried out on synthetic data and compared to human judgments on the same stimuli.
Visual object tracking performance measures revisited
Mar 07, 2016


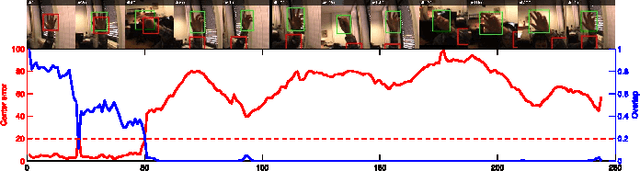
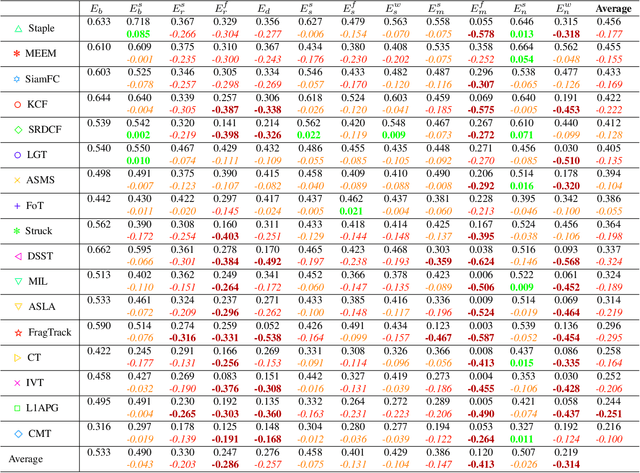
The problem of visual tracking evaluation is sporting a large variety of performance measures, and largely suffers from lack of consensus about which measures should be used in experiments. This makes the cross-paper tracker comparison difficult. Furthermore, as some measures may be less effective than others, the tracking results may be skewed or biased towards particular tracking aspects. In this paper we revisit the popular performance measures and tracker performance visualizations and analyze them theoretically and experimentally. We show that several measures are equivalent from the point of information they provide for tracker comparison and, crucially, that some are more brittle than the others. Based on our analysis we narrow down the set of potential measures to only two complementary ones, describing accuracy and robustness, thus pushing towards homogenization of the tracker evaluation methodology. These two measures can be intuitively interpreted and visualized and have been employed by the recent Visual Object Tracking (VOT) challenges as the foundation for the evaluation methodology.