 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributionally-Robust Framework for Nuisance in Causal Effect Estimation
May 23, 2025Causal inference requires evaluating models on balanced distributions between treatment and control groups, while training data often exhibits imbalance due to historical decision-making policies. Most conventional statistical methods address this distribution shift through inverse probability weighting (IPW), which requires estimating propensity scores as an intermediate step. These methods face two key challenges: inaccurate propensity estimation and instability from extreme weights. We decompose the generalization error to isolate these issues--propensity ambiguity and statistical instability--and address them through an adversarial loss function. Our approach combines distributionally robust optimization for handling propensity uncertainty with weight regularization based on weighted Rademacher complexity. Experiments on synthetic and real-world datasets demonstrate consistent improvements over existing methods.
Regret Minimization for Causal Inference on Large Treatment Space
Jun 10, 2020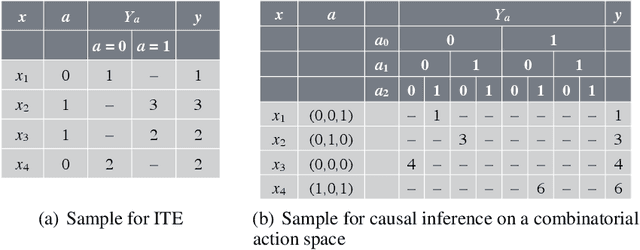
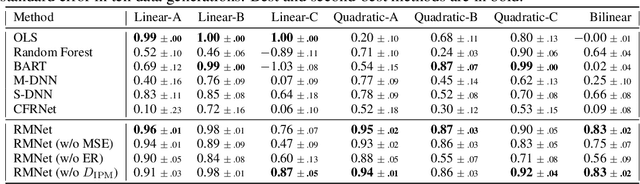
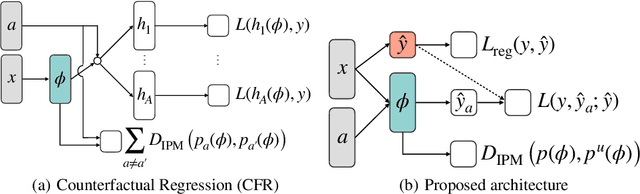
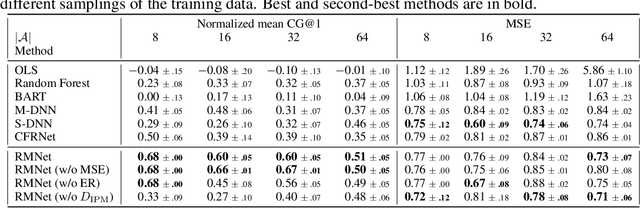
Predicting which action (treatment) will lead to a better outcome is a central task in decision support systems. To build a prediction model in real situations, learning from biased observational data is a critical issue due to the lack of randomized controlled trial (RCT) data. To handle such biased observational data, recent efforts in causal inference and counterfactual machine learning have focused on debiased estimation of the potential outcomes on a binary action space and the difference between them, namely, the individual treatment effect. When it comes to a large action space (e.g., selecting an appropriate combination of medicines for a patient), however, the regression accuracy of the potential outcomes is no longer sufficient in practical terms to achieve a good decision-making performance. This is because the mean accuracy on the large action space does not guarantee the nonexistence of a single potential outcome misestimation that might mislead the whole decision. Our proposed loss minimizes a classification error of whether or not the action is relatively good for the individual target among all feasible actions, which further improves the decision-making performance, as we prove. We also propose a network architecture and a regularizer that extracts a debiased representation not only from the individual feature but also from the biased action for better generalization in large action spaces. Extensive experiments on synthetic and semi-synthetic datasets demonstrate the superiority of our method for large combinatorial action spaces.