 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2: Scalable Rubric-Augmented Reward Modeling from Binary Preferences
Apr 15, 2026Rubric-augmented verification guides reward models with explicit evaluation criteria, yielding more reliable judgments than single-model verification. However, most existing methods require costly rubric annotations, limiting scalability. Moreover, we find that rubric generation is vulnerable to a failure of cooperation; low-quality rubrics actively mislead reward models rather than help. Inspired by the principle of cooperative communication, we propose Cooperative yet Critical reward modeling (C2), a framework that significantly improves reward model judgments by having the reward model critically collaborate with a rubric generator trained solely from binary preferences. In C2, we synthesize helpful and misleading rubric pairs by measuring how each rubric shifts the reward model toward or away from the correct preference. Using these contrastive pairs, we train a cooperative rubric generator to propose helpful rubrics, and a critical verifier to assess rubric validity before making its judgment, following only rubrics it deems helpful at inference time. C2 outperforms reasoning reward models trained on the same binary preferences, with gains of up to 6.5 points on RM-Bench and 6.0 points length-controlled win rate on AlpacaEval 2.0. Without external rubric annotations, C2 enables an 8B reward model to match performance achieved with rubrics from a 4$\times$ larger model. Overall, our work demonstrates that eliciting deliberate cooperation in rubric-augmented verification makes reward models more trustworthy in a scalable way.
Rationale-Aware Answer Verification by Pairwise Self-Evaluation
Oct 07, 2024Answer verification identifies correct solutions among candidates generated by large language models (LLMs). Current approaches typically train verifier models by labeling solutions as correct or incorrect based solely on whether the final answer matches the gold answer. However, this approach neglects any flawed rationale in the solution yielding the correct answer, undermining the verifier's ability to distinguish between sound and flawed rationales. We empirically show that in StrategyQA, only 19% of LLM-generated solutions with correct answers have valid rationales, thus leading to an unreliable verifier. Furthermore, we demonstrate that training a verifier on valid rationales significantly improves its ability to distinguish valid and flawed rationale. To make a better verifier without extra human supervision, we introduce REPS (Rationale Enhancement through Pairwise Selection), a method for selecting valid rationales from candidates by iteratively applying pairwise self-evaluation using the same LLM that generates the solutions. Verifiers trained on solutions selected by REPS outperform those trained using conventional training methods on three reasoning benchmarks (ARC-Challenge, DROP, and StrategyQA). Our results suggest that training reliable verifiers requires ensuring the validity of rationales in addition to the correctness of the final answers, which would be critical for models assisting humans in solving complex reasoning tasks.
Evaluating the Rationale Understanding of Critical Reasoning in Logical Reading Comprehension
Nov 30, 2023
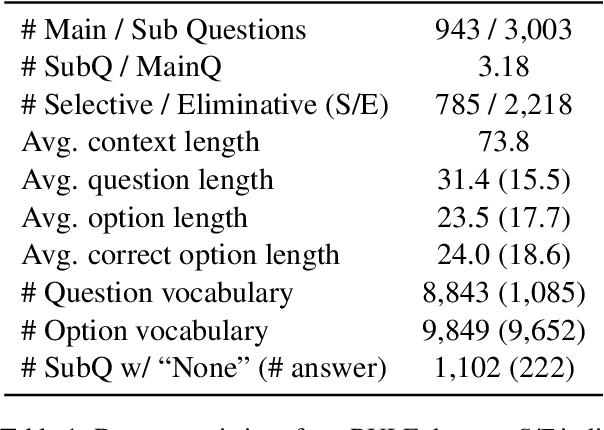

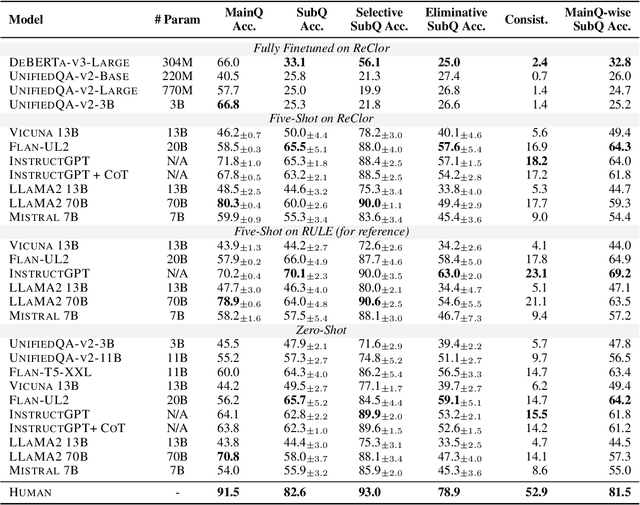
To precisely evaluate a language model's capability for logical reading comprehension, we present a dataset for testing the understanding of the rationale behind critical reasoning. For questions taken from an existing multiplechoice logical reading comprehension dataset, we crowdsource rationale texts that explain why we should select or eliminate answer options, resulting in 3,003 multiple-choice subquestions that are associated with 943 main questions. Experiments on our dataset show that recent large language models (e.g., InstructGPT) struggle to answer the subquestions even if they are able to answer the main questions correctly. We find that the models perform particularly poorly in answering subquestions written for the incorrect options of the main questions, implying that the models have a limited capability for explaining why incorrect alternatives should be eliminated. These results suggest that our dataset encourages further investigation into the critical reasoning ability of language models while focusing on the elimination process of relevant alternatives.