 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveform to Single Sinusoid Regression to Estimate the F0 Contour from Noisy Speech Using Recurrent Deep Neural Networks
Jul 02, 2018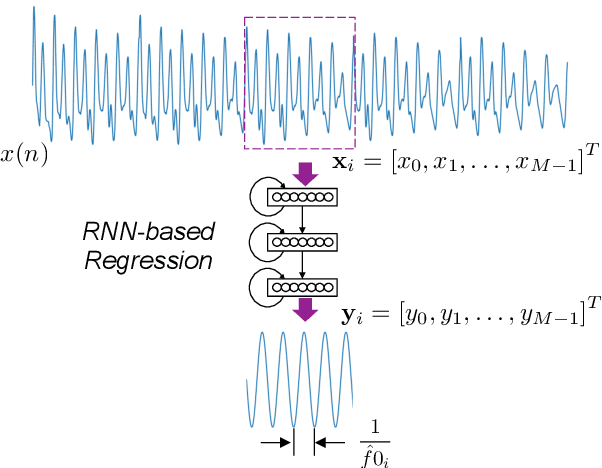
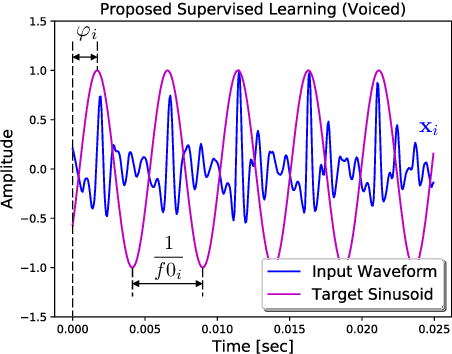
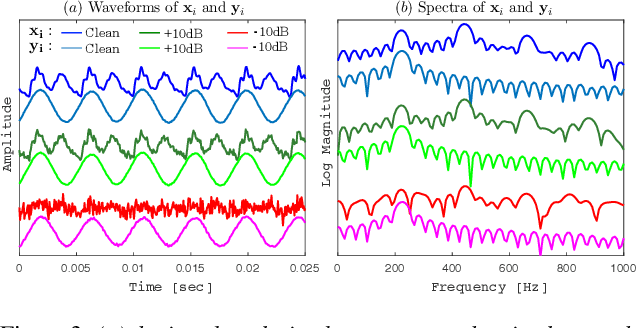
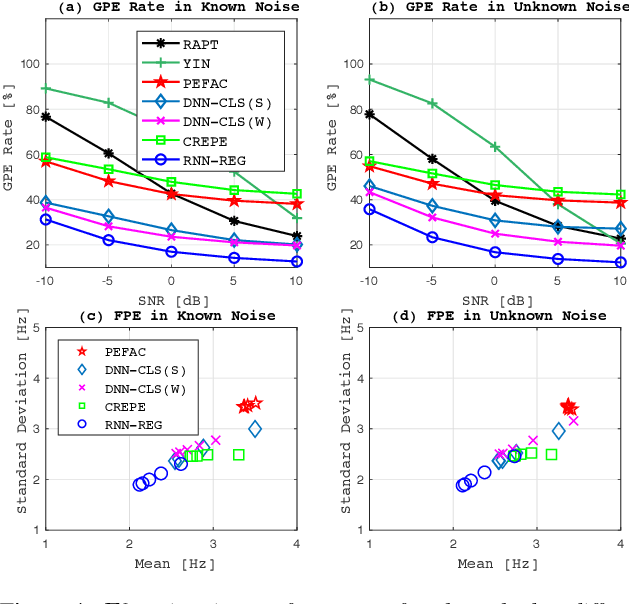
The fundamental frequency (F0) represents pitch in speech that determines prosodic characteristics of speech and is needed in various tasks for speech analysis and synthesis. Despite decades of research on this topic, F0 estimation at low signal-to-noise ratios (SNRs) in unexpected noise conditions remains difficult. This work proposes a new approach to noise robust F0 estimation using a recurrent neural network (RNN) trained in a supervised manner. Recent studies employ deep neural networks (DNNs) for F0 tracking as a frame-by-frame classification task into quantised frequency states but we propose waveform-to-sinusoid regression instead to achieve both noise robustness and accurate estimation with increased frequency resolution. Experimental results with PTDB-TUG corpus contaminated by additive noise (NOISEX-92) demonstrate that the proposed method improves gross pitch error (GPE) rate and fine pitch error (FPE) by more than 35 % at SNRs between -10 dB and +10 dB compared with well-known noise robust F0 tracker, PEFAC. Furthermore, the proposed method also outperforms state-of-the-art DNN-based approaches by more than 15 % in terms of both FPE and GPE rate over the preceding SNR range.
A Regression Model of Recurrent Deep Neural Networks for Noise Robust Estimation of the Fundamental Frequency Contour of Speech
May 08, 2018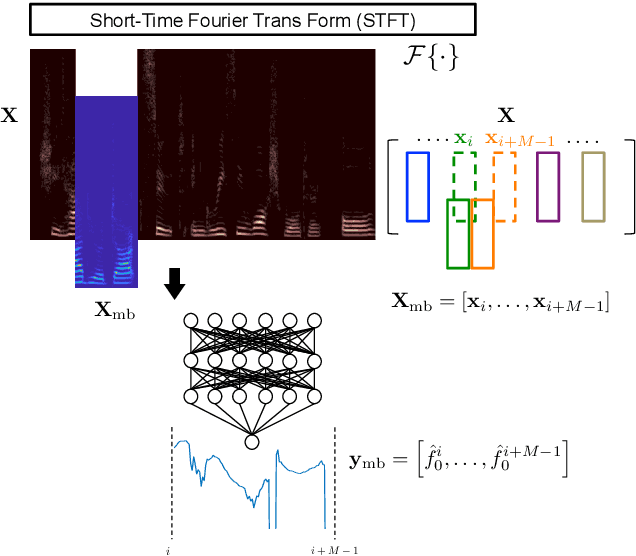
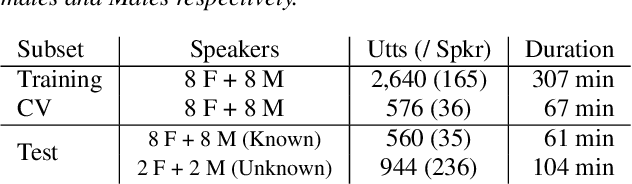
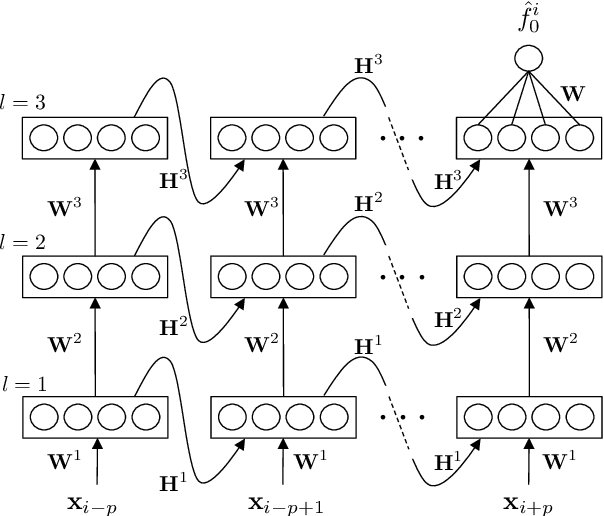

The fundamental frequency (F0) contour of speech is a key aspect to represent speech prosody that finds use in speech and spoken language analysis such as voice conversion and speech synthesis as well as speaker and language identification. This work proposes new methods to estimate the F0 contour of speech using deep neural networks (DNNs) and recurrent neural networks (RNNs). They are trained using supervised learning with the ground truth of F0 contours. The latest prior research addresses this problem first as a frame-by-frame-classification problem followed by sequence tracking using deep neural network hidden Markov model (DNN-HMM) hybrid architecture. This study, however, tackles the problem as a regression problem instead, in order to obtain F0 contours with higher frequency resolution from clean and noisy speech. Experiments using PTDB-TUG corpus contaminated with additive noise (NOISEX-92) show the proposed method improves gross pitch error (GPE) by more than 25 % at signal-to-noise ratios (SNRs) between -10 dB and +10 dB as compared with one of the most noise-robust F0 trackers, PEFAC. Furthermore, the performance on fine pitch error (FPE) is improved by approximately 20 % against a state-of-the-art DNN-HMM-based approach.