 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibri-Adapt: A New Speech Dataset for Unsupervised Domain Adaptation
Sep 06, 2020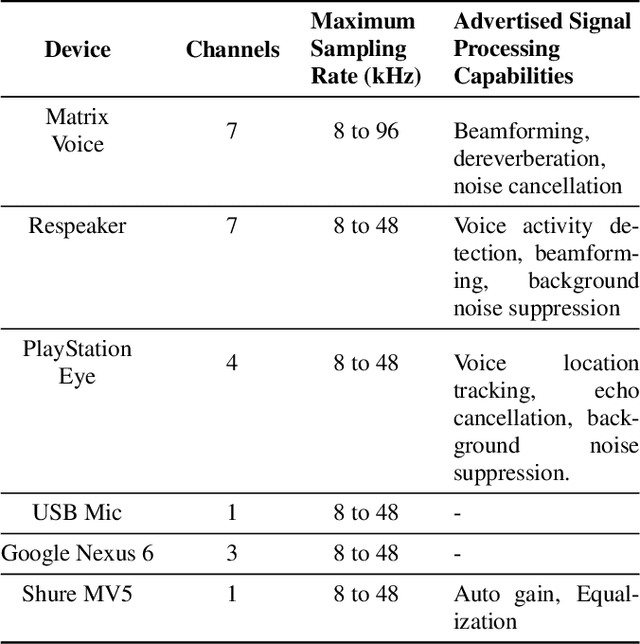
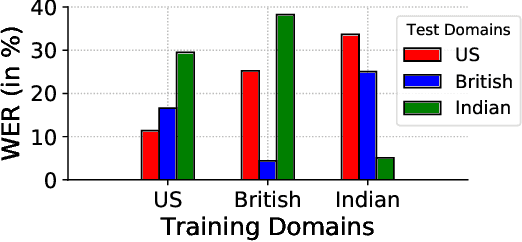
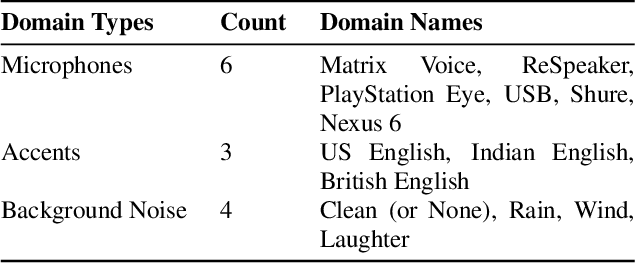
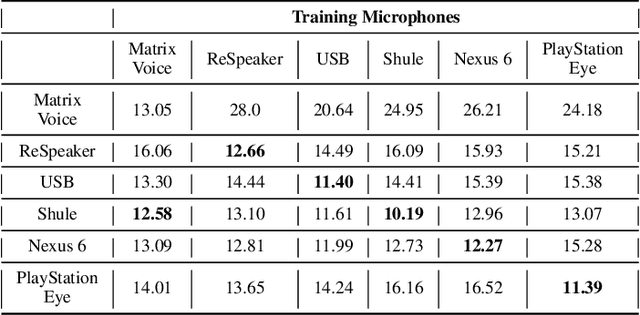
This paper introduces a new dataset, Libri-Adapt, to support unsupervised domain adaptation research on speech recognition models. Built on top of the LibriSpeech corpus, Libri-Adapt contains English speech recorded on mobile and embedded-scale microphones, and spans 72 different domains that are representative of the challenging practical scenarios encountered by ASR models. More specifically, Libri-Adapt facilitates the study of domain shifts in ASR models caused by a) different acoustic environments, b) variations in speaker accents, c) heterogeneity in the hardware and platform software of the microphones, and d) a combination of the aforementioned three shifts. We also provide a number of baseline results quantifying the impact of these domain shifts on the Mozilla DeepSpeech2 ASR model.
* 5 pages, Published at IEEE ICASSP 2020
Flower: A Friendly Federated Learning Research Framework
Jul 28, 2020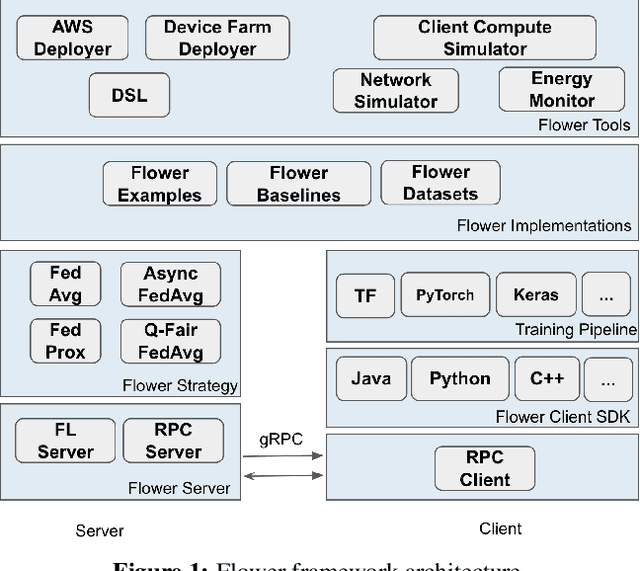
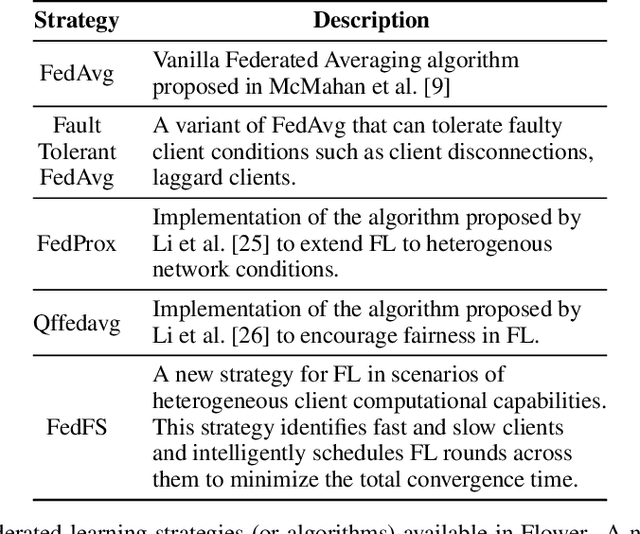
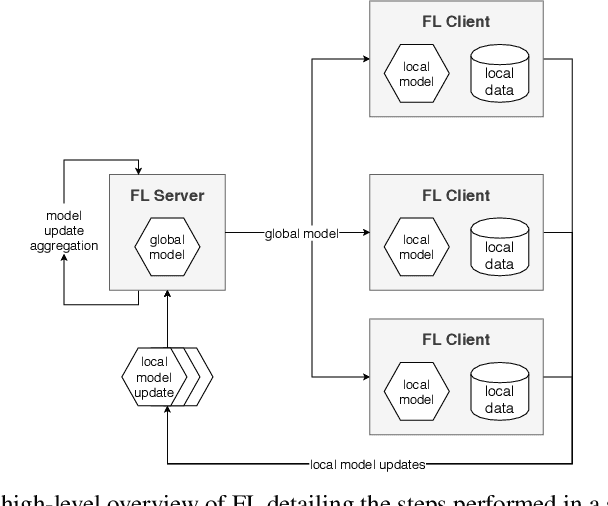
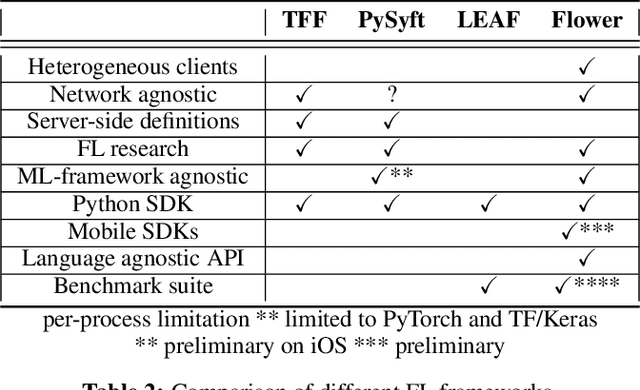
Federated Learning (FL) has emerged as a promising technique for edge devices to collaboratively learn a shared prediction model, while keeping their training data on the device, thereby decoupling the ability to do machine learning from the need to store the data in the cloud. However, FL is difficult to implement and deploy in practice, considering the heterogeneity in mobile devices, e.g., different programming languages, frameworks, and hardware accelerators. Although there are a few frameworks available to simulate FL algorithms (e.g., TensorFlow Federated), they do not support implementing FL workloads on mobile devices. Furthermore, these frameworks are designed to simulate FL in a server environment and hence do not allow experimentation in distributed mobile settings for a large number of clients. In this paper, we present Flower (https://flower.dev/), a FL framework which is both agnostic towards heterogeneous client environments and also scales to a large number of clients, including mobile and embedded devices. Flower's abstractions let developers port existing mobile workloads with little overhead, regardless of the programming language or ML framework used, while also allowing researchers flexibility to experiment with novel approaches to advance the state-of-the-art. We describe the design goals and implementation considerations of Flower and show our experiences in evaluating the performance of FL across clients with heterogeneous computational and communication capabilities.
Mic2Mic: Using Cycle-Consistent Generative Adversarial Networks to Overcome Microphone Variability in Speech Systems
Mar 27, 2020
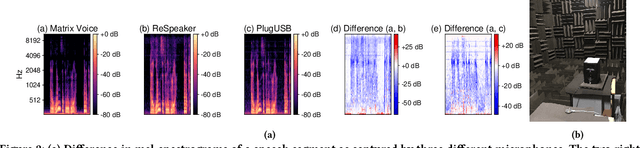
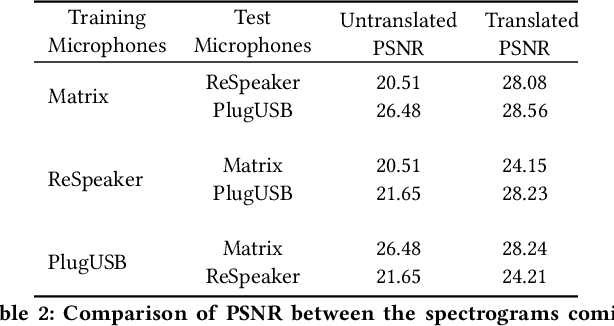
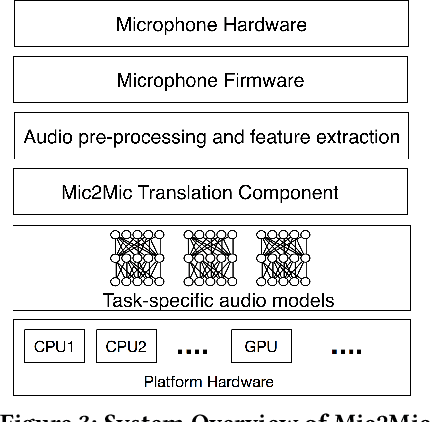
Mobile and embedded devices are increasingly using microphones and audio-based computational models to infer user context. A major challenge in building systems that combine audio models with commodity microphones is to guarantee their accuracy and robustness in the real-world. Besides many environmental dynamics, a primary factor that impacts the robustness of audio models is microphone variability. In this work, we propose Mic2Mic -- a machine-learned system component -- which resides in the inference pipeline of audio models and at real-time reduces the variability in audio data caused by microphone-specific factors. Two key considerations for the design of Mic2Mic were: a) to decouple the problem of microphone variability from the audio task, and b) put a minimal burden on end-users to provide training data. With these in mind, we apply the principles of cycle-consistent generative adversarial networks (CycleGANs) to learn Mic2Mic using unlabeled and unpaired data collected from different microphones. Our experiments show that Mic2Mic can recover between 66% to 89% of the accuracy lost due to microphone variability for two common audio tasks.
Automatic Detection of Protective Behavior in Chronic Pain Physical Rehabilitation: A Recurrent Neural Network Approach
Feb 24, 2019
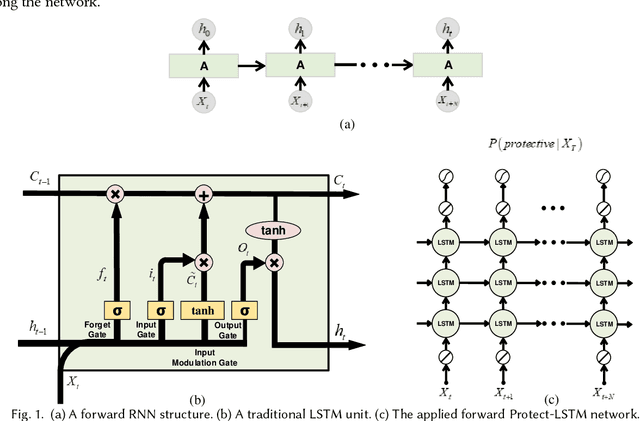
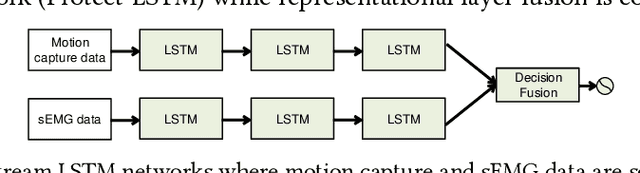
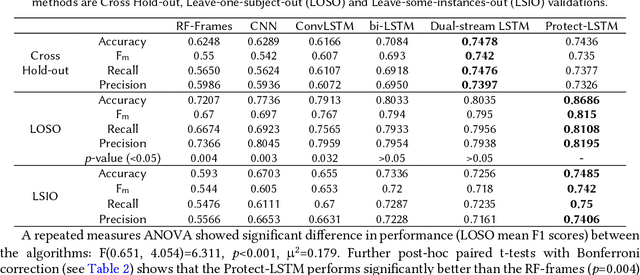
In chronic pain physical rehabilitation, physiotherapists adapt movement to current performance of patients especially based on the expression of protective behavior, gradually exposing them to feared but harmless and essential everyday movements. As physical rehabilitation moves outside the clinic, physical rehabilitation technology needs to automatically detect such behaviors so as to provide similar personalized support. In this paper, we investigate the use of a Long Short-Term Memory (LSTM) network, which we call Protect-LSTM, to detect events of protective behavior, based on motion capture and electromyography data of healthy people and people with chronic low back pain engaged in five everyday movements. Differently from previous work on the same dataset, we aim to continuously detect protective behavior within a movement rather than overall estimate the presence of such behavior. The Protect-LSTM reaches best average F1 score of 0.815 with leave-one-subject-out (LOSO) validation, using low level features, better than other algorithms. Performances increase for some movements when modelled separately (mean F1 scores: bending=0.77, standing on one leg=0.81, sit-to-stand=0.72, stand-to-sit=0.83, reaching forward=0.67). These results reach excellent level of agreement with the average ratings of physiotherapists. As such, the results show clear potential for in-home technology supported affect-based personalized physical rehabilitation.