 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Supervised Learning Pipeline for Demographically Fair Facial Attribute Classification
Jul 14, 2024



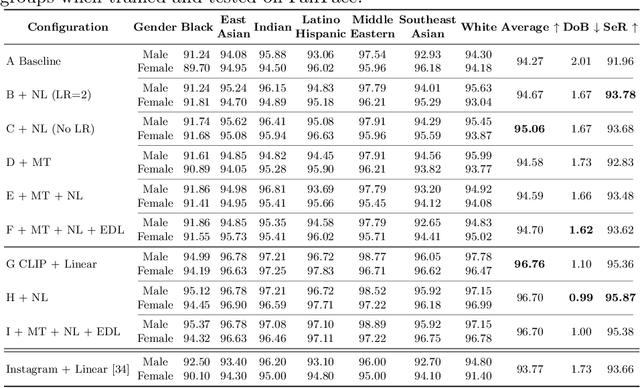
Published research highlights the presence of demographic bias in automated facial attribute classification. The proposed bias mitigation techniques are mostly based on supervised learning, which requires a large amount of labeled training data for generalizability and scalability. However, labeled data is limited, requires laborious annotation, poses privacy risks, and can perpetuate human bias. In contrast, self-supervised learning (SSL) capitalizes on freely available unlabeled data, rendering trained models more scalable and generalizable. However, these label-free SSL models may also introduce biases by sampling false negative pairs, especially at low-data regimes 200K images) under low compute settings. Further, SSL-based models may suffer from performance degradation due to a lack of quality assurance of the unlabeled data sourced from the web. This paper proposes a fully self-supervised pipeline for demographically fair facial attribute classifiers. Leveraging completely unlabeled data pseudolabeled via pre-trained encoders, diverse data curation techniques, and meta-learning-based weighted contrastive learning, our method significantly outperforms existing SSL approaches proposed for downstream image classification tasks. Extensive evaluations on the FairFace and CelebA datasets demonstrate the efficacy of our pipeline in obtaining fair performance over existing baselines. Thus, setting a new benchmark for SSL in the fairness of facial attribute classification.
PatchBMI-Net: Lightweight Facial Patch-based Ensemble for BMI Prediction
Nov 29, 2023



Due to an alarming trend related to obesity affecting 93.3 million adults in the United States alone, body mass index (BMI) and body weight have drawn significant interest in various health monitoring applications. Consequently, several studies have proposed self-diagnostic facial image-based BMI prediction methods for healthy weight monitoring. These methods have mostly used convolutional neural network (CNN) based regression baselines, such as VGG19, ResNet50, and Efficient-NetB0, for BMI prediction from facial images. However, the high computational requirement of these heavy-weight CNN models limits their deployment to resource-constrained mobile devices, thus deterring weight monitoring using smartphones. This paper aims to develop a lightweight facial patch-based ensemble (PatchBMI-Net) for BMI prediction to facilitate the deployment and weight monitoring using smartphones. Extensive experiments on BMI-annotated facial image datasets suggest that our proposed PatchBMI-Net model can obtain Mean Absolute Error (MAE) in the range [3.58, 6.51] with a size of about 3.3 million parameters. On cross-comparison with heavyweight models, such as ResNet-50 and Xception, trained for BMI prediction from facial images, our proposed PatchBMI-Net obtains equivalent MAE along with the model size reduction of about 5.4x and the average inference time reduction of about 3x when deployed on Apple-14 smartphone. Thus, demonstrating performance efficiency as well as low latency for on-device deployment and weight monitoring using smartphone applications.
MIS-AVoiDD: Modality Invariant and Specific Representation for Audio-Visual Deepfake Detection
Oct 13, 2023



Deepfakes are synthetic media generated using deep generative algorithms and have posed a severe societal and political threat. Apart from facial manipulation and synthetic voice, recently, a novel kind of deepfakes has emerged with either audio or visual modalities manipulated. In this regard, a new generation of multimodal audio-visual deepfake detectors is being investigated to collectively focus on audio and visual data for multimodal manipulation detection. Existing multimodal (audio-visual) deepfake detectors are often based on the fusion of the audio and visual streams from the video. Existing studies suggest that these multimodal detectors often obtain equivalent performances with unimodal audio and visual deepfake detectors. We conjecture that the heterogeneous nature of the audio and visual signals creates distributional modality gaps and poses a significant challenge to effective fusion and efficient performance. In this paper, we tackle the problem at the representation level to aid the fusion of audio and visual streams for multimodal deepfake detection. Specifically, we propose the joint use of modality (audio and visual) invariant and specific representations. This ensures that the common patterns and patterns specific to each modality representing pristine or fake content are preserved and fused for multimodal deepfake manipulation detection. Our experimental results on FakeAVCeleb and KoDF audio-visual deepfake datasets suggest the enhanced accuracy of our proposed method over SOTA unimodal and multimodal audio-visual deepfake detectors by $17.8$% and $18.4$%, respectively. Thus, obtaining state-of-the-art performance.
Facial Forgery-based Deepfake Detection using Fine-Grained Features
Oct 10, 2023



Facial forgery by deepfakes has caused major security risks and raised severe societal concerns. As a countermeasure, a number of deepfake detection methods have been proposed. Most of them model deepfake detection as a binary classification problem using a backbone convolutional neural network (CNN) architecture pretrained for the task. These CNN-based methods have demonstrated very high efficacy in deepfake detection with the Area under the Curve (AUC) as high as $0.99$. However, the performance of these methods degrades significantly when evaluated across datasets and deepfake manipulation techniques. This draws our attention towards learning more subtle, local, and discriminative features for deepfake detection. In this paper, we formulate deepfake detection as a fine-grained classification problem and propose a new fine-grained solution to it. Specifically, our method is based on learning subtle and generalizable features by effectively suppressing background noise and learning discriminative features at various scales for deepfake detection. Through extensive experimental validation, we demonstrate the superiority of our method over the published research in cross-dataset and cross-manipulation generalization of deepfake detectors for the majority of the experimental scenarios.
Is Facial Recognition Biased at Near-Infrared Spectrum As Well?
Oct 31, 2022Published academic research and media articles suggest face recognition is biased across demographics. Specifically, unequal performance is obtained for women, dark-skinned people, and older adults. However, these published studies have examined the bias of facial recognition in the visible spectrum (VIS). Factors such as facial makeup, facial hair, skin color, and illumination variation have been attributed to the bias of this technology at the VIS. The near-infrared (NIR) spectrum offers an advantage over the VIS in terms of robustness to factors such as illumination changes, facial makeup, and skin color. Therefore, it is worthwhile to investigate the bias of facial recognition at the near-infrared spectrum (NIR). This first study investigates the bias of the face recognition systems at the NIR spectrum. To this aim, two popular NIR facial image datasets namely, CASIA-Face-Africa and Notre-Dame-NIVL consisting of African and Caucasian subjects, respectively, are used to investigate the bias of facial recognition technology across gender and race. Interestingly, experimental results suggest equitable face recognition performance across gender and race at the NIR spectrum.
Deep Generative Views to Mitigate Gender Classification Bias Across Gender-Race Groups
Aug 17, 2022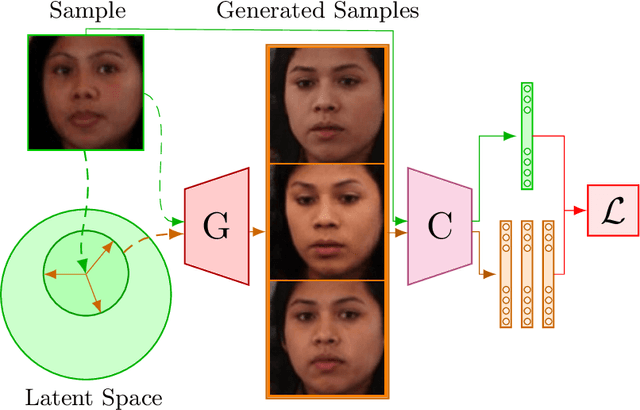

Published studies have suggested the bias of automated face-based gender classification algorithms across gender-race groups. Specifically, unequal accuracy rates were obtained for women and dark-skinned people. To mitigate the bias of gender classifiers, the vision community has developed several strategies. However, the efficacy of these mitigation strategies is demonstrated for a limited number of races mostly, Caucasian and African-American. Further, these strategies often offer a trade-off between bias and classification accuracy. To further advance the state-of-the-art, we leverage the power of generative views, structured learning, and evidential learning towards mitigating gender classification bias. We demonstrate the superiority of our bias mitigation strategy in improving classification accuracy and reducing bias across gender-racial groups through extensive experimental validation, resulting in state-of-the-art performance in intra- and cross dataset evaluations.
GBDF: Gender Balanced DeepFake Dataset Towards Fair DeepFake Detection
Jul 21, 2022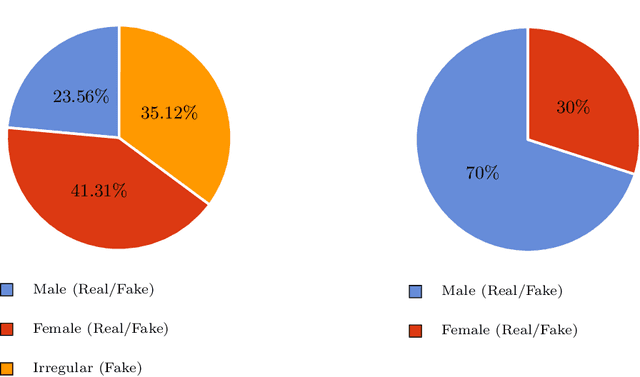
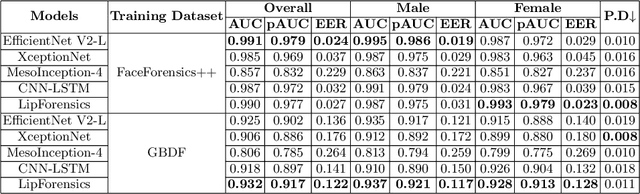
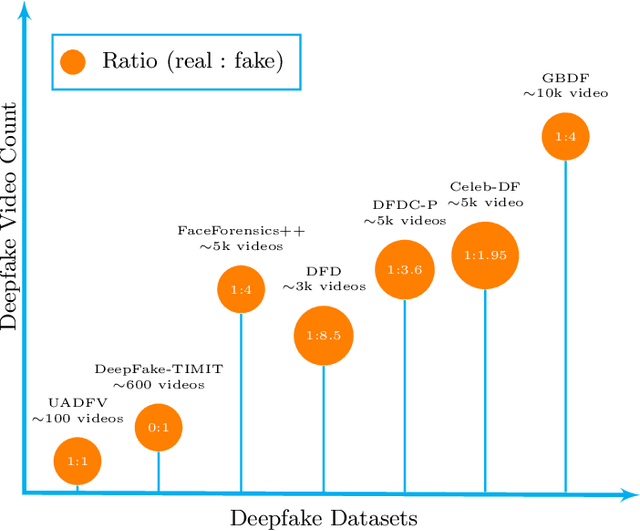
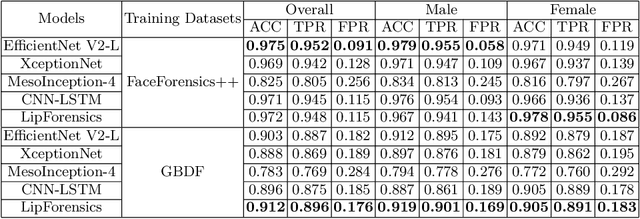
Facial forgery by deepfakes has raised severe societal concerns. Several solutions have been proposed by the vision community to effectively combat the misinformation on the internet via automated deepfake detection systems. Recent studies have demonstrated that facial analysis-based deep learning models can discriminate based on protected attributes. For the commercial adoption and massive roll-out of the deepfake detection technology, it is vital to evaluate and understand the fairness (the absence of any prejudice or favoritism) of deepfake detectors across demographic variations such as gender and race. As the performance differential of deepfake detectors between demographic subgroups would impact millions of people of the deprived sub-group. This paper aims to evaluate the fairness of the deepfake detectors across males and females. However, existing deepfake datasets are not annotated with demographic labels to facilitate fairness analysis. To this aim, we manually annotated existing popular deepfake datasets with gender labels and evaluated the performance differential of current deepfake detectors across gender. Our analysis on the gender-labeled version of the datasets suggests (a) current deepfake datasets have skewed distribution across gender, and (b) commonly adopted deepfake detectors obtain unequal performance across gender with mostly males outperforming females. Finally, we contributed a gender-balanced and annotated deepfake dataset, GBDF, to mitigate the performance differential and to promote research and development towards fairness-aware deep fake detectors. The GBDF dataset is publicly available at: https://github.com/aakash4305/GBDF
An Examination of Bias of Facial Analysis based BMI Prediction Models
Apr 21, 2022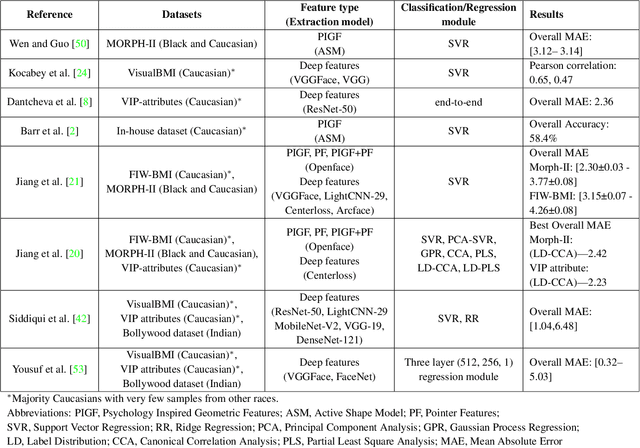


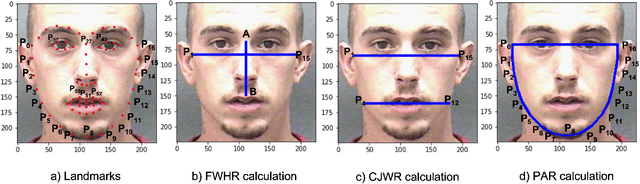
Obesity is one of the most important public health problems that the world is facing today. A recent trend is in the development of intervention tools that predict BMI using facial images for weight monitoring and management to combat obesity. Most of these studies used BMI annotated facial image datasets that mainly consisted of Caucasian subjects. Research on bias evaluation of face-based gender-, age-classification, and face recognition systems suggest that these technologies perform poorly for women, dark-skinned people, and older adults. The bias of facial analysis-based BMI prediction tools has not been studied until now. This paper evaluates the bias of facial-analysis-based BMI prediction models across Caucasian and African-American Males and Females. Experimental investigations on the gender, race, and BMI balanced version of the modified MORPH-II dataset suggested that the error rate in BMI prediction was least for Black Males and highest for White Females. Further, the psychology-related facial features correlated with weight suggested that as the BMI increases, the changes in the facial region are more prominent for Black Males and the least for White Females. This is the reason for the least error rate of the facial analysis-based BMI prediction tool for Black Males and highest for White Females.
On Improving Cross-dataset Generalization of Deepfake Detectors
Apr 08, 2022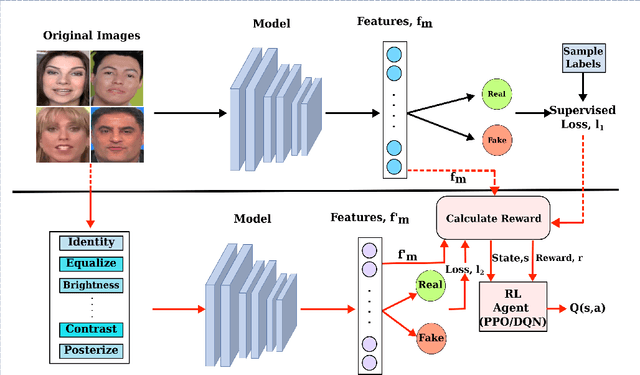
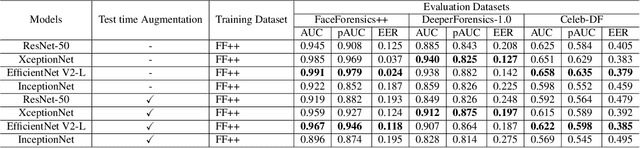
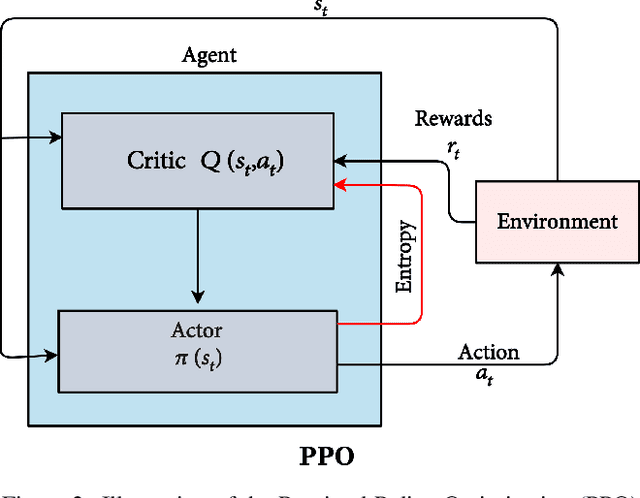
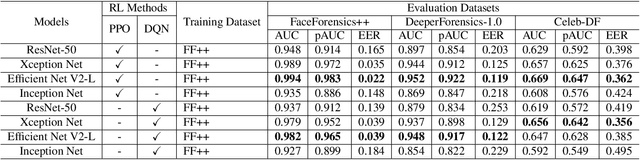
Facial manipulation by deep fake has caused major security risks and raised severe societal concerns. As a countermeasure, a number of deep fake detection methods have been proposed recently. Most of them model deep fake detection as a binary classification problem using a backbone convolutional neural network (CNN) architecture pretrained for the task. These CNN-based methods have demonstrated very high efficacy in deep fake detection with the Area under the Curve (AUC) as high as 0.99. However, the performance of these methods degrades significantly when evaluated across datasets. In this paper, we formulate deep fake detection as a hybrid combination of supervised and reinforcement learning (RL) to improve its cross-dataset generalization performance. The proposed method chooses the top-k augmentations for each test sample by an RL agent in an image-specific manner. The classification scores, obtained using CNN, of all the augmentations of each test image are averaged together for final real or fake classification. Through extensive experimental validation, we demonstrate the superiority of our method over existing published research in cross-dataset generalization of deep fake detectors, thus obtaining state-of-the-art performance.
Compact CNN Models for On-device Ocular-based User Recognition in Mobile Devices
Oct 11, 2021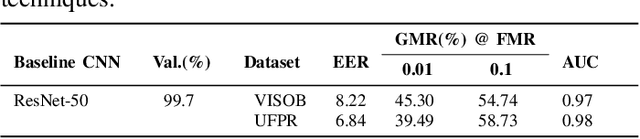
A number of studies have demonstrated the efficacy of deep learning convolutional neural network (CNN) models for ocular-based user recognition in mobile devices. However, these high-performing networks have enormous space and computational complexity due to the millions of parameters and computations involved. These requirements make the deployment of deep learning models to resource-constrained mobile devices challenging. To this end, only a handful of studies based on knowledge distillation and patch-based models have been proposed to obtain compact size CNN models for ocular recognition in the mobile environment. In order to further advance the state-of-the-art, this study for the first time evaluates five neural network pruning methods and compares them with the knowledge distillation method for on-device CNN inference and mobile user verification using ocular images. Subject-independent analysis on VISOB and UPFR-Periocular datasets suggest the efficacy of layerwise magnitude-based pruning at a compression rate of 8 for mobile ocular-based authentication using ResNet50 as the base model. Further, comparison with the knowledge distillation suggests the efficacy of knowledge distillation over pruning methods in terms of verification accuracy and the real-time inference measured as deep feature extraction time on five mobile devices, namely, iPhone 6, iPhone X, iPhone XR, iPad Air 2 and iPad 7th Generation.
* 8 pages. arXiv admin note: text overlap with arXiv:2003.03033 by other authors