 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Engineering for Agents: An Adaptive Cognitive Architecture for Interpretable ML Monitoring
Jun 11, 2025Monitoring Machine Learning (ML) models in production environments is crucial, yet traditional approaches often yield verbose, low-interpretability outputs that hinder effective decision-making. We propose a cognitive architecture for ML monitoring that applies feature engineering principles to agents based on Large Language Models (LLMs), significantly enhancing the interpretability of monitoring outputs. Central to our approach is a Decision Procedure module that simulates feature engineering through three key steps: Refactor, Break Down, and Compile. The Refactor step improves data representation to better capture feature semantics, allowing the LLM to focus on salient aspects of the monitoring data while reducing noise and irrelevant information. Break Down decomposes complex information for detailed analysis, and Compile integrates sub-insights into clear, interpretable outputs. This process leads to a more deterministic planning approach, reducing dependence on LLM-generated planning, which can sometimes be inconsistent and overly general. The combination of feature engineering-driven planning and selective LLM utilization results in a robust decision support system, capable of providing highly interpretable and actionable insights. Experiments using multiple LLMs demonstrate the efficacy of our approach, achieving significantly higher accuracy compared to various baselines across several domains.
TADIL: Task-Agnostic Domain-Incremental Learning through Task-ID Inference using Transformer Nearest-Centroid Embeddings
Jun 21, 2023Machine Learning (ML) models struggle with data that changes over time or across domains due to factors such as noise, occlusion, illumination, or frequency, unlike humans who can learn from such non independent and identically distributed data. Consequently, a Continual Learning (CL) approach is indispensable, particularly, Domain-Incremental Learning. In this paper, we propose a novel pipeline for identifying tasks in domain-incremental learning scenarios without supervision. The pipeline comprises four steps. First, we obtain base embeddings from the raw data using an existing transformer-based model. Second, we group the embedding densities based on their similarity to obtain the nearest points to each cluster centroid. Third, we train an incremental task classifier using only these few points. Finally, we leverage the lightweight computational requirements of the pipeline to devise an algorithm that decides in an online fashion when to learn a new task using the task classifier and a drift detector. We conduct experiments using the SODA10M real-world driving dataset and several CL strategies. We demonstrate that the performance of these CL strategies with our pipeline can match the ground-truth approach, both in classical experiments assuming task boundaries, and also in more realistic task-agnostic scenarios that require detecting new tasks on-the-fly
Human-in-the-loop online multi-agent approach to increase trustworthiness in ML models through trust scores and data augmentation
May 02, 2022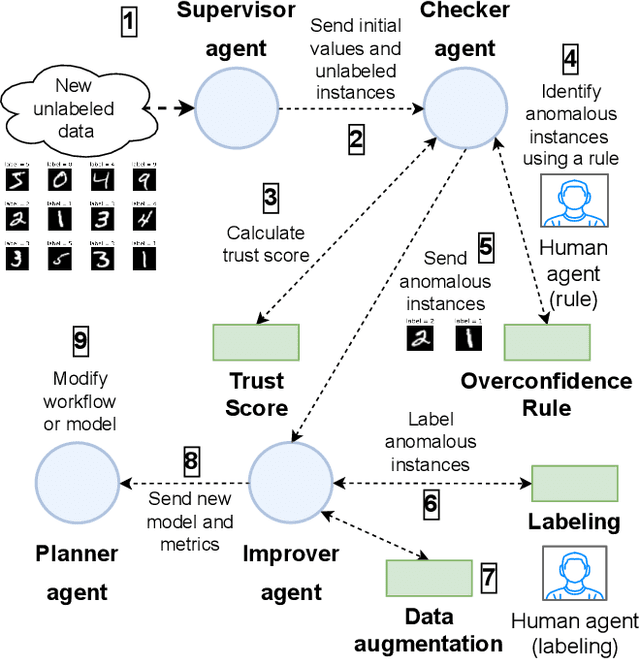
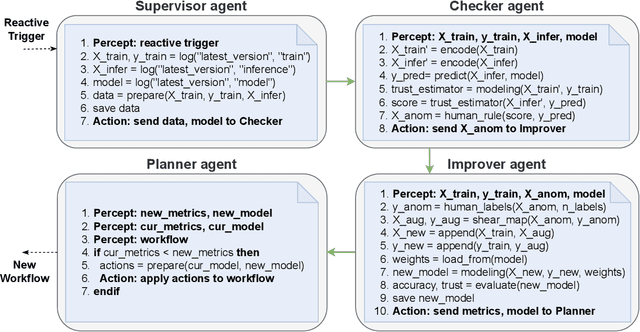
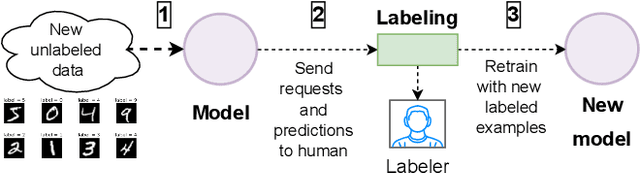
Increasing a ML model accuracy is not enough, we must also increase its trustworthiness. This is an important step for building resilient AI systems for safety-critical applications such as automotive, finance, and healthcare. For that purpose, we propose a multi-agent system that combines both machine and human agents. In this system, a checker agent calculates a trust score of each instance (which penalizes overconfidence and overcautiousness in predictions) using an agreement-based method and ranks it; then an improver agent filters the anomalous instances based on a human rule-based procedure (which is considered safe), gets the human labels, applies geometric data augmentation, and retrains with the augmented data using transfer learning. We evaluate the system on corrupted versions of the MNIST and FashionMNIST datasets. We get an improvement in accuracy and trust score with just few additional labels compared to a baseline approach.
Scanflow: A multi-graph framework for Machine Learning workflow management, supervision, and debugging
Nov 04, 2021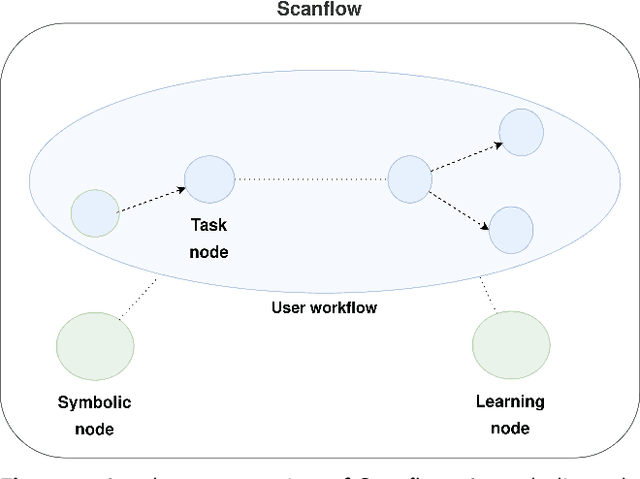
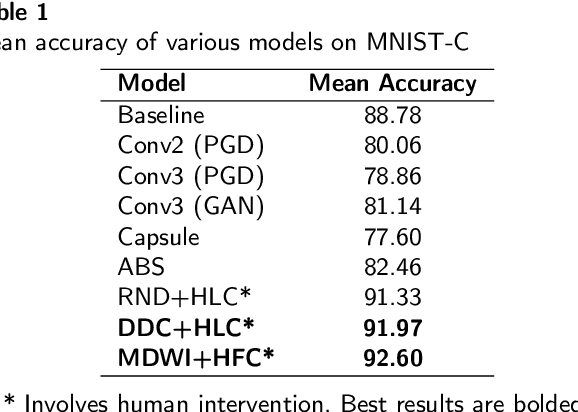
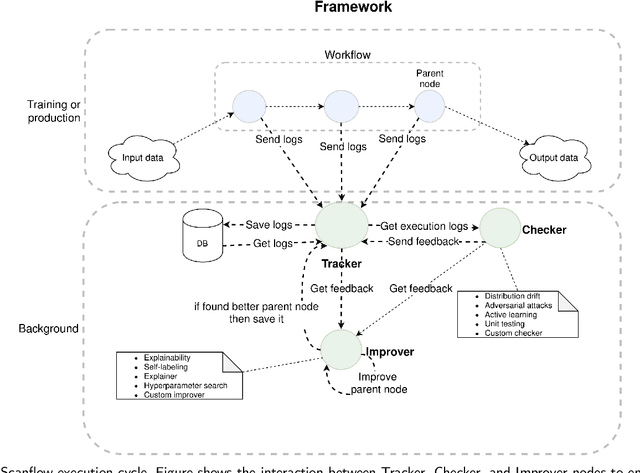
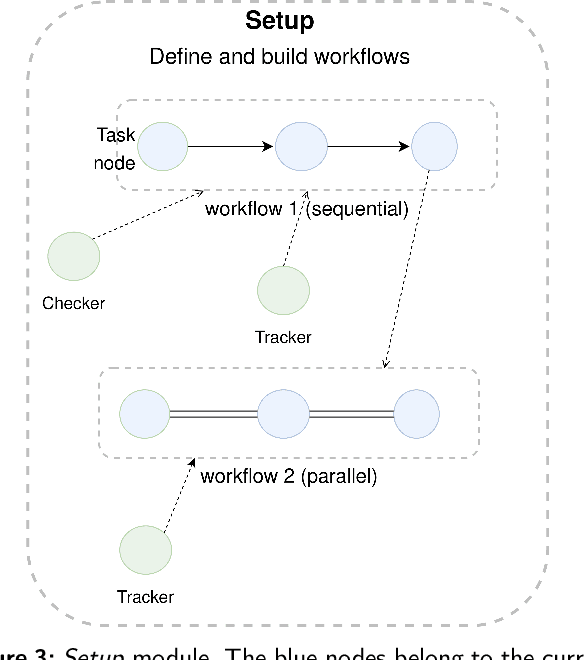
Machine Learning (ML) is more than just training models, the whole workflow must be considered. Once deployed, a ML model needs to be watched and constantly supervised and debugged to guarantee its validity and robustness in unexpected situations. Debugging in ML aims to identify (and address) the model weaknesses in not trivial contexts. Several techniques have been proposed to identify different types of model weaknesses, such as bias in classification, model decay, adversarial attacks, etc., yet there is not a generic framework that allows them to work in a collaborative, modular, portable, iterative way and, more importantly, flexible enough to allow both human- and machine-driven techniques. In this paper, we propose a novel containerized directed graph framework to support and accelerate end-to-end ML workflow management, supervision, and debugging. The framework allows defining and deploying ML workflows in containers, tracking their metadata, checking their behavior in production, and improving the models by using both learned and human-provided knowledge. We demonstrate these capabilities by integrating in the framework two hybrid systems to detect data drift distribution which identify the samples that are far from the latent space of the original distribution, ask for human intervention, and whether retrain the model or wrap it with a filter to remove the noise of corrupted data at inference time. We test these systems on MNIST-C, CIFAR-10-C, and FashionMNIST-C datasets, obtaining promising accuracy results with the help of human involvement.