 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyn-TurnTurk: A Synthetic Dataset for Turn-Taking Prediction in Turkish Dialogues
Apr 15, 2026Managing natural dialogue timing is a significant challenge for voice-based chatbots. Most current systems usually rely on simple silence detection, which often fails because human speech patterns involve irregular pauses. This causes bots to interrupt users, breaking the conversational flow. This problem is even more severe for languages like Turkish, which lack high-quality datasets for turn-taking prediction. This paper introduces Syn-TurnTurk, a synthetic Turkish dialogue dataset generated using various Qwen Large Language Models (LLMs) to mirror real-life verbal exchanges, including overlaps and strategic silences. We evaluated the dataset using several traditional and deep learning architectures. The results show that advanced models, particularly BI-LSTM and Ensemble (LR+RF) methods, achieve high accuracy (0.839) and AUC scores (0.910). These findings demonstrate that our synthetic dataset can have a positive affect for models understand linguistic cues, allowing for more natural human-machine interaction in Turkish.
Using Person Embedding to Enrich Features and Data Augmentation for Classification
Jun 30, 2022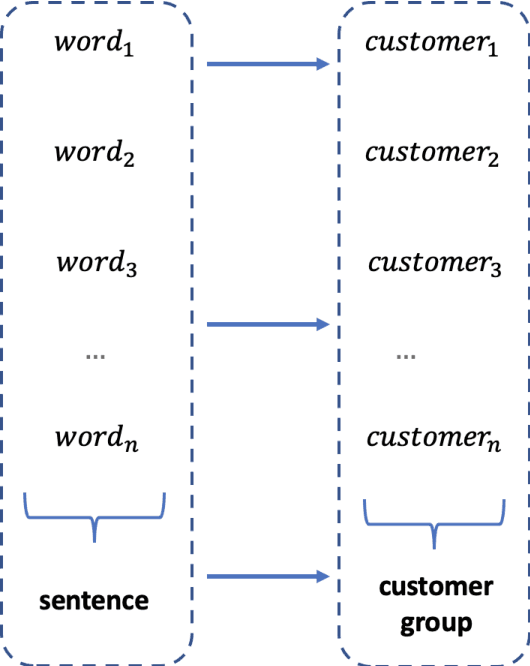
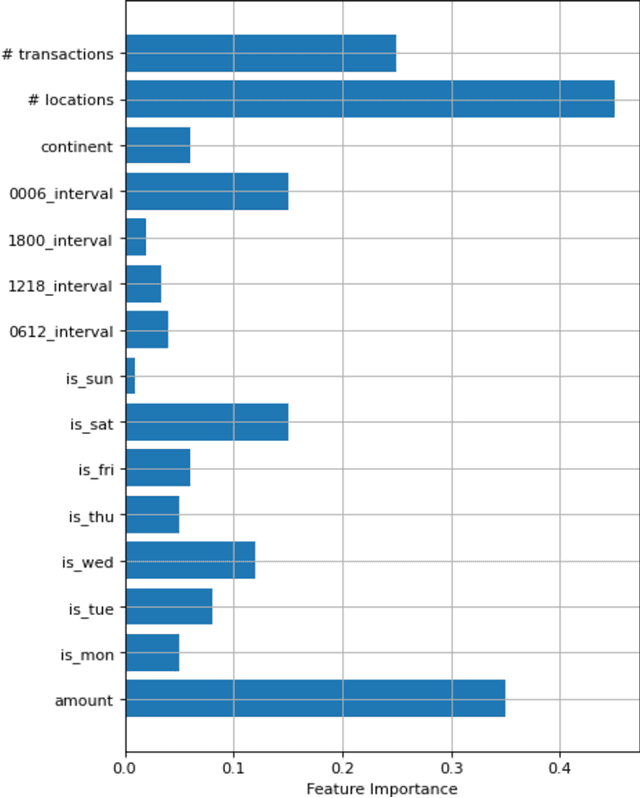
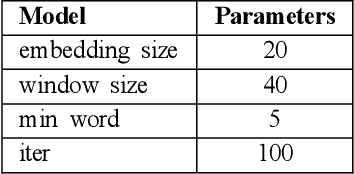
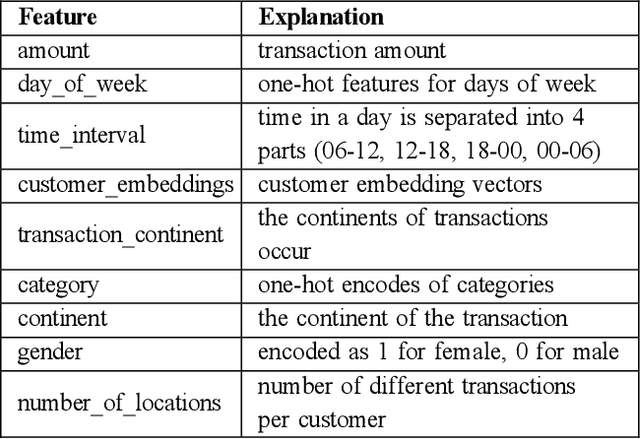
Today, machine learning is applied in almost any field. In machine learning, where there are numerous methods, classification is one of the most basic and crucial ones. Various problems can be solved by classification. The feature selection for model setup is extremely important, and producing new features via feature engineering also has a vital place in the success of the model. In our study, fraud detection classification models are built on a labeled and imbalanced dataset as a case-study. Although it is a natural language processing method, a customer space has been created with word embedding, which has been used in different areas, especially for recommender systems. The customer vectors in the created space are fed to the classification model as a feature. Moreover, to increase the number of positive labels, rows with similar characteristics are re-labeled as positive by using customer similarity determined by embedding. The model in which embedding methods are included in the classification, which provides a better representation of customers, has been compared with other models. Considering the results, it is observed that the customer embedding method had a positive effect on the success of the classification models.