 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxATtack: A Multimodal Attack on Voice Anonymization Systems
Jul 16, 2025Voice anonymization systems aim to protect speaker privacy by obscuring vocal traits while preserving the linguistic content relevant for downstream applications. However, because these linguistic cues remain intact, they can be exploited to identify semantic speech patterns associated with specific speakers. In this work, we present VoxATtack, a novel multimodal de-anonymization model that incorporates both acoustic and textual information to attack anonymization systems. While previous research has focused on refining speaker representations extracted from speech, we show that incorporating textual information with a standard ECAPA-TDNN improves the attacker's performance. Our proposed VoxATtack model employs a dual-branch architecture, with an ECAPA-TDNN processing anonymized speech and a pretrained BERT encoding the transcriptions. Both outputs are projected into embeddings of equal dimensionality and then fused based on confidence weights computed on a per-utterance basis. When evaluating our approach on the VoicePrivacy Attacker Challenge (VPAC) dataset, it outperforms the top-ranking attackers on five out of seven benchmarks, namely B3, B4, B5, T8-5, and T12-5. To further boost performance, we leverage anonymized speech and SpecAugment as augmentation techniques. This enhancement enables VoxATtack to achieve state-of-the-art on all VPAC benchmarks, after scoring 20.6% and 27.2% average equal error rate on T10-2 and T25-1, respectively. Our results demonstrate that incorporating textual information and selective data augmentation reveals critical vulnerabilities in current voice anonymization methods and exposes potential weaknesses in the datasets used to evaluate them.
You Are What You Say: Exploiting Linguistic Content for VoicePrivacy Attacks
Jun 11, 2025Speaker anonymization systems hide the identity of speakers while preserving other information such as linguistic content and emotions. To evaluate their privacy benefits, attacks in the form of automatic speaker verification (ASV) systems are employed. In this study, we assess the impact of intra-speaker linguistic content similarity in the attacker training and evaluation datasets, by adapting BERT, a language model, as an ASV system. On the VoicePrivacy Attacker Challenge datasets, our method achieves a mean equal error rate (EER) of 35%, with certain speakers attaining EERs as low as 2%, based solely on the textual content of their utterances. Our explainability study reveals that the system decisions are linked to semantically similar keywords within utterances, stemming from how LibriSpeech is curated. Our study suggests reworking the VoicePrivacy datasets to ensure a fair and unbiased evaluation and challenge the reliance on global EER for privacy evaluations.
Speaker Verification in Multi-Speaker Environments Using Temporal Feature Fusion
Jun 28, 2022
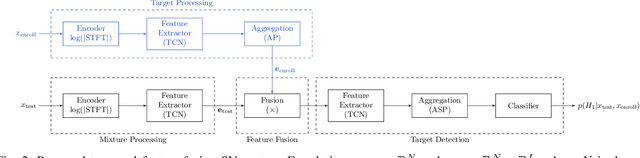
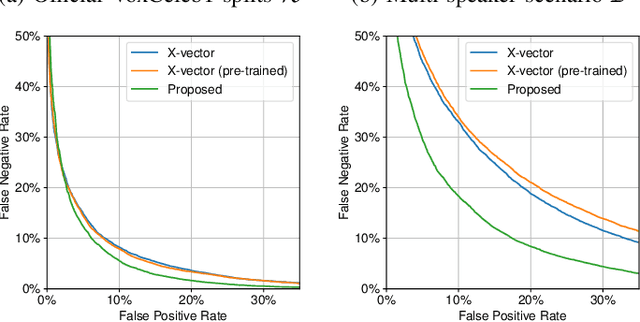
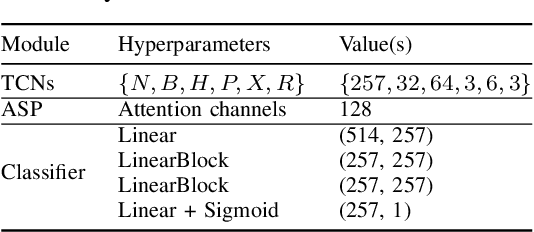
Verifying the identity of a speaker is crucial in modern human-machine interfaces, e.g., to ensure privacy protection or to enable biometric authentication. Classical speaker verification (SV) approaches estimate a fixed-dimensional embedding from a speech utterance that encodes the speaker's voice characteristics. A speaker is verified if his/her voice embedding is sufficiently similar to the embedding of the claimed speaker. However, such approaches assume that only a single speaker exists in the input. The presence of concurrent speakers is likely to have detrimental effects on the performance. To address SV in a multi-speaker environment, we propose an end-to-end deep learning-based SV system that detects whether the target speaker exists within an input or not. First, an embedding is estimated from a reference utterance to represent the target's characteristics. Second, frame-level features are estimated from the input mixture. The reference embedding is then fused frame-wise with the mixture's features to allow distinguishing the target from other speakers on a frame basis. Finally, the fused features are used to predict whether the target speaker is active in the speech segment or not. Experimental evaluation shows that the proposed method outperforms the x-vector in multi-speaker conditions.