 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAquaDiff: Diffusion-Based Underwater Image Enhancement for Addressing Color Distortion
Dec 15, 2025Underwater images are severely degraded by wavelength-dependent light absorption and scattering, resulting in color distortion, low contrast, and loss of fine details that hinder vision-based underwater applications. To address these challenges, we propose AquaDiff, a diffusion-based underwater image enhancement framework designed to correct chromatic distortions while preserving structural and perceptual fidelity. AquaDiff integrates a chromatic prior-guided color compensation strategy with a conditional diffusion process, where cross-attention dynamically fuses degraded inputs and noisy latent states at each denoising step. An enhanced denoising backbone with residual dense blocks and multi-resolution attention captures both global color context and local details. Furthermore, a novel cross-domain consistency loss jointly enforces pixel-level accuracy, perceptual similarity, structural integrity, and frequency-domain fidelity. Extensive experiments on multiple challenging underwater benchmarks demonstrate that AquaDiff provides good results as compared to the state-of-the-art traditional, CNN-, GAN-, and diffusion-based methods, achieving superior color correction and competitive overall image quality across diverse underwater conditions.
Underwater Diffusion Attention Network with Contrastive Language-Image Joint Learning for Underwater Image Enhancement
May 26, 2025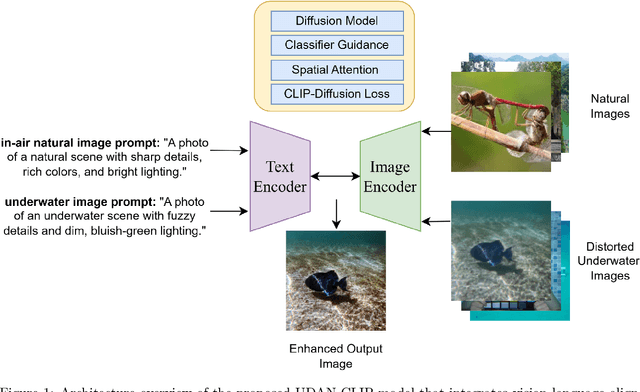
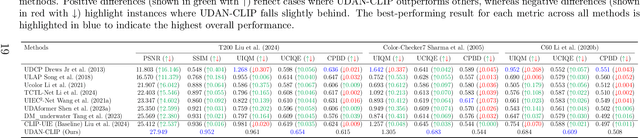
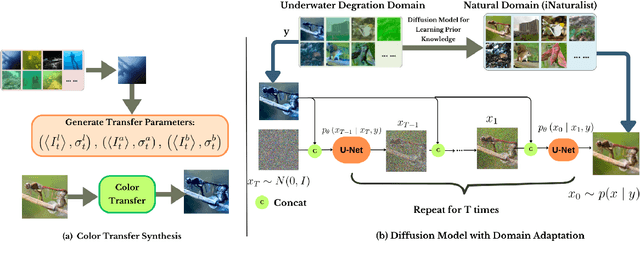

Underwater images are often affected by complex degradations such as light absorption, scattering, color casts, and artifacts, making enhancement critical for effective object detection, recognition, and scene understanding in aquatic environments. Existing methods, especially diffusion-based approaches, typically rely on synthetic paired datasets due to the scarcity of real underwater references, introducing bias and limiting generalization. Furthermore, fine-tuning these models can degrade learned priors, resulting in unrealistic enhancements due to domain shifts. To address these challenges, we propose UDAN-CLIP, an image-to-image diffusion framework pre-trained on synthetic underwater datasets and enhanced with a customized classifier based on vision-language model, a spatial attention module, and a novel CLIP-Diffusion loss. The classifier preserves natural in-air priors and semantically guides the diffusion process, while the spatial attention module focuses on correcting localized degradations such as haze and low contrast. The proposed CLIP-Diffusion loss further strengthens visual-textual alignment and helps maintain semantic consistency during enhancement. The proposed contributions empower our UDAN-CLIP model to perform more effective underwater image enhancement, producing results that are not only visually compelling but also more realistic and detail-preserving. These improvements are consistently validated through both quantitative metrics and qualitative visual comparisons, demonstrating the model's ability to correct distortions and restore natural appearance in challenging underwater conditions.