 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkolemization for Weighted First-Order Model Counting
Mar 05, 2014First-order model counting emerged recently as a novel reasoning task, at the core of efficient algorithms for probabilistic logics. We present a Skolemization algorithm for model counting problems that eliminates existential quantifiers from a first-order logic theory without changing its weighted model count. For certain subsets of first-order logic, lifted model counters were shown to run in time polynomial in the number of objects in the domain of discourse, where propositional model counters require exponential time. However, these guarantees apply only to Skolem normal form theories (i.e., no existential quantifiers) as the presence of existential quantifiers reduces lifted model counters to propositional ones. Since textbook Skolemization is not sound for model counting, these restrictions precluded efficient model counting for directed models, such as probabilistic logic programs, which rely on existential quantification. Our Skolemization procedure extends the applicability of first-order model counters to these representations. Moreover, it simplifies the design of lifted model counting algorithms.
On the Complexity and Approximation of Binary Evidence in Lifted Inference
Nov 26, 2013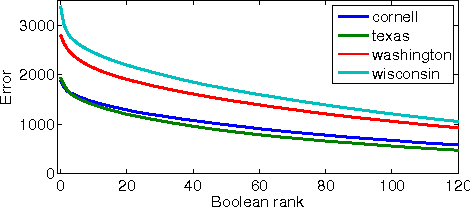
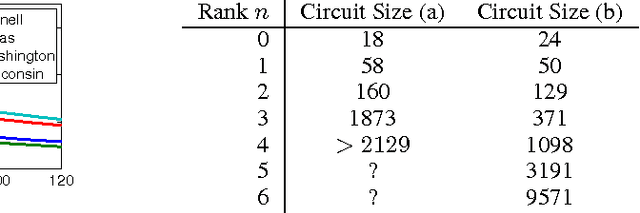
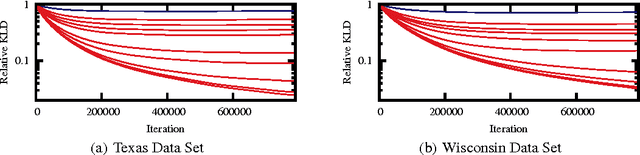
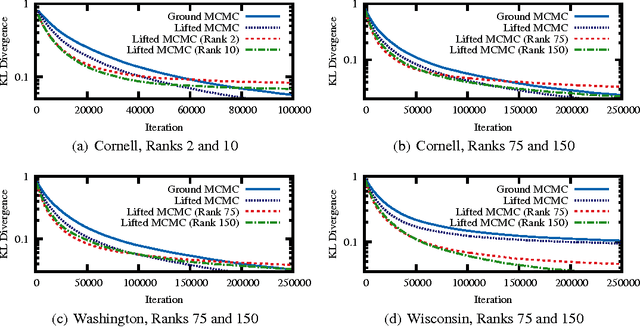
Lifted inference algorithms exploit symmetries in probabilistic models to speed up inference. They show impressive performance when calculating unconditional probabilities in relational models, but often resort to non-lifted inference when computing conditional probabilities. The reason is that conditioning on evidence breaks many of the model's symmetries, which can preempt standard lifting techniques. Recent theoretical results show, for example, that conditioning on evidence which corresponds to binary relations is #P-hard, suggesting that no lifting is to be expected in the worst case. In this paper, we balance this negative result by identifying the Boolean rank of the evidence as a key parameter for characterizing the complexity of conditioning in lifted inference. In particular, we show that conditioning on binary evidence with bounded Boolean rank is efficient. This opens up the possibility of approximating evidence by a low-rank Boolean matrix factorization, which we investigate both theoretically and empirically.
Objection-Based Causal Networks
Mar 13, 2013

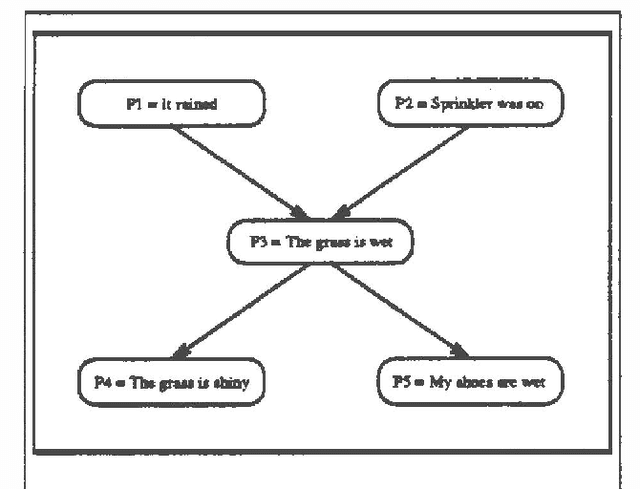
This paper introduces the notion of objection-based causal networks which resemble probabilistic causal networks except that they are quantified using objections. An objection is a logical sentence and denotes a condition under which a, causal dependency does not exist. Objection-based causal networks enjoy almost all the properties that make probabilistic causal networks popular, with the added advantage that objections are, arguably more intuitive than probabilities.
Argument Calculus and Networks
Mar 06, 2013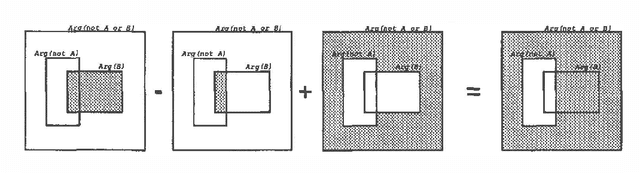
A major reason behind the success of probability calculus is that it possesses a number of valuable tools, which are based on the notion of probabilistic independence. In this paper, I identify a notion of logical independence that makes some of these tools available to a class of propositional databases, called argument databases. Specifically, I suggest a graphical representation of argument databases, called argument networks, which resemble Bayesian networks. I also suggest an algorithm for reasoning with argument networks, which resembles a basic algorithm for reasoning with Bayesian networks. Finally, I show that argument networks have several applications: Nonmonotonic reasoning, truth maintenance, and diagnosis.
On the Relation between Kappa Calculus and Probabilistic Reasoning
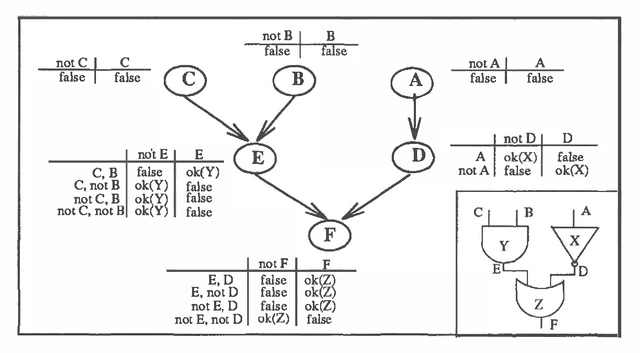
Feb 27, 2013
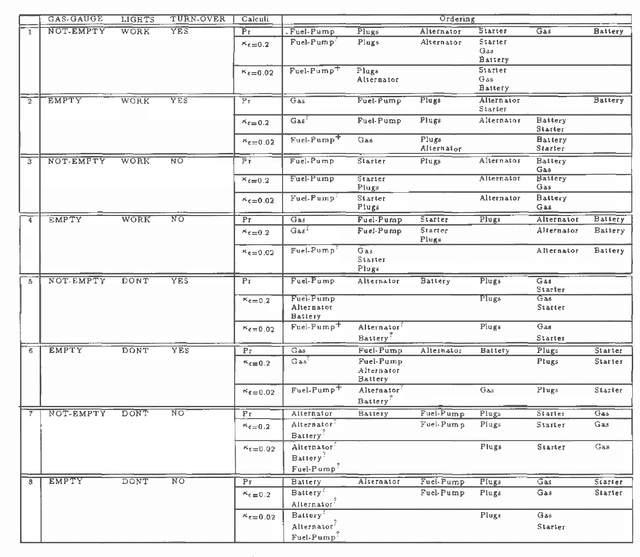
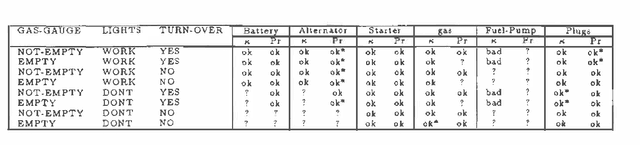
We study the connection between kappa calculus and probabilistic reasoning in diagnosis applications. Specifically, we abstract a probabilistic belief network for diagnosing faults into a kappa network and compare the ordering of faults computed using both methods. We show that, at least for the example examined, the ordering of faults coincide as long as all the causal relations in the original probabilistic network are taken into account. We also provide a formal analysis of some network structures where the two methods will differ. Both kappa rankings and infinitesimal probabilities have been used extensively to study default reasoning and belief revision. But little has been done on utilizing their connection as outlined above. This is partly because the relation between kappa and probability calculi assumes that probabilities are arbitrarily close to one (or zero). The experiments in this paper investigate this relation when this assumption is not satisfied. The reported results have important implications on the use of kappa rankings to enhance the knowledge engineering of uncertainty models.
Action Networks: A Framework for Reasoning about Actions and Change under Uncertainty
Feb 27, 2013
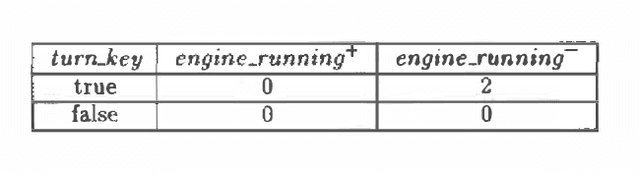
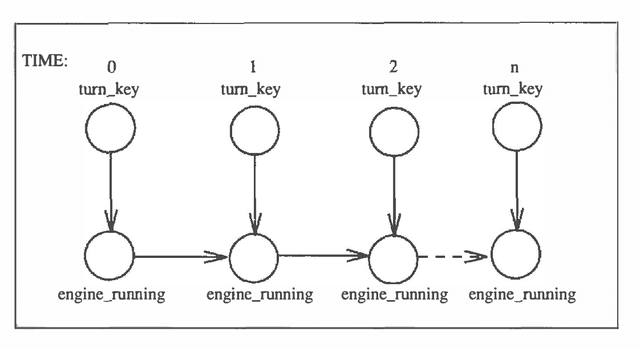
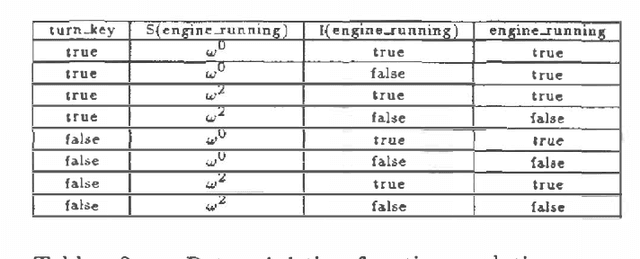
This work proposes action networks as a semantically well-founded framework for reasoning about actions and change under uncertainty. Action networks add two primitives to probabilistic causal networks: controllable variables and persistent variables. Controllable variables allow the representation of actions as directly setting the value of specific events in the domain, subject to preconditions. Persistent variables provide a canonical model of persistence according to which both the state of a variable and the causal mechanism dictating its value persist over time unless intervened upon by an action (or its consequences). Action networks also allow different methods for quantifying the uncertainty in causal relationships, which go beyond traditional probabilistic quantification. This paper describes both recent results and work in progress.
Conditioning Methods for Exact and Approximate Inference in Causal Networks
Feb 20, 2013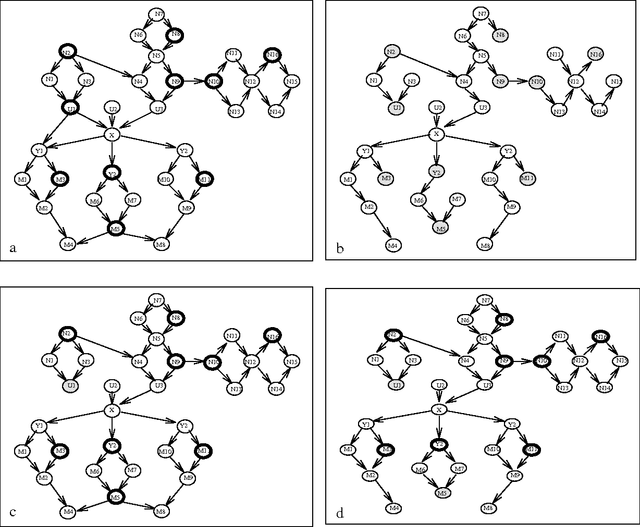
We present two algorithms for exact and approximate inference in causal networks. The first algorithm, dynamic conditioning, is a refinement of cutset conditioning that has linear complexity on some networks for which cutset conditioning is exponential. The second algorithm, B-conditioning, is an algorithm for approximate inference that allows one to trade-off the quality of approximations with the computation time. We also present some experimental results illustrating the properties of the proposed algorithms.
A Standard Approach for Optimizing Belief Network Inference using Query DAGs
Feb 06, 2013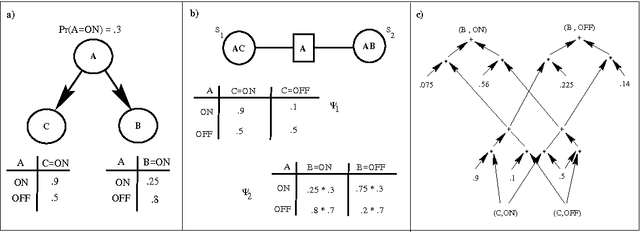
This paper proposes a novel, algorithm-independent approach to optimizing belief network inference. rather than designing optimizations on an algorithm by algorithm basis, we argue that one should use an unoptimized algorithm to generate a Q-DAG, a compiled graphical representation of the belief network, and then optimize the Q-DAG and its evaluator instead. We present a set of Q-DAG optimizations that supplant optimizations designed for traditional inference algorithms, including zero compression, network pruning and caching. We show that our Q-DAG optimizations require time linear in the Q-DAG size, and significantly simplify the process of designing algorithms for optimizing belief network inference.
Dynamic Jointrees
Jan 30, 2013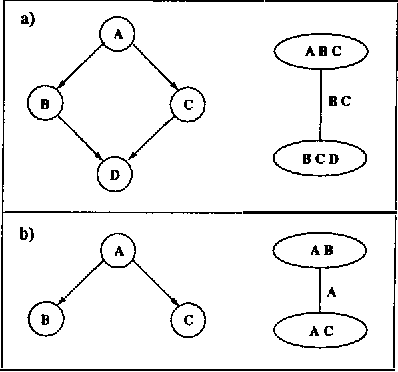
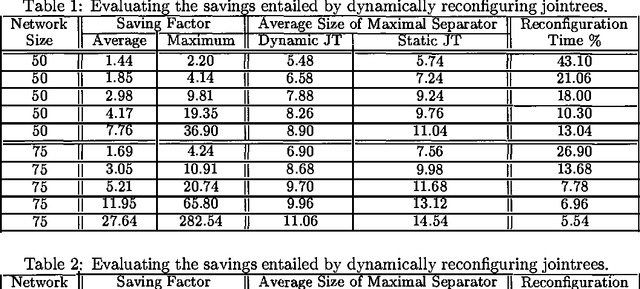
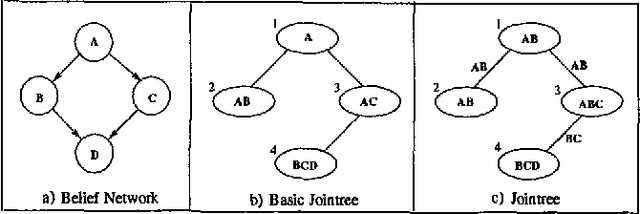
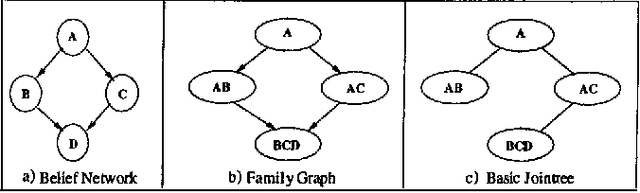
It is well known that one can ignore parts of a belief network when computing answers to certain probabilistic queries. It is also well known that the ignorable parts (if any) depend on the specific query of interest and, therefore, may change as the query changes. Algorithms based on jointrees, however, do not seem to take computational advantage of these facts given that they typically construct jointrees for worst-case queries; that is, queries for which every part of the belief network is considered relevant. To address this limitation, we propose in this paper a method for reconfiguring jointrees dynamically as the query changes. The reconfiguration process aims at maintaining a jointree which corresponds to the underlying belief network after it has been pruned given the current query. Our reconfiguration method is marked by three characteristics: (a) it is based on a non-classical definition of jointrees; (b) it is relatively efficient; and (c) it can reuse some of the computations performed before a jointree is reconfigured. We present preliminary experimental results which demonstrate significant savings over using static jointrees when query changes are considerable.
Any-Space Probabilistic Inference
Jan 16, 2013
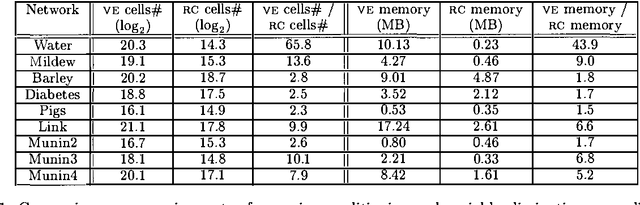
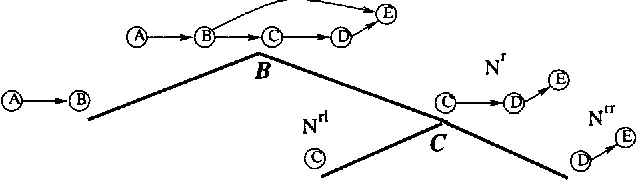

We have recently introduced an any-space algorithm for exact inference in Bayesian networks, called Recursive Conditioning, RC, which allows one to trade space with time at increments of X-bytes, where X is the number of bytes needed to cache a floating point number. In this paper, we present three key extensions of RC. First, we modify the algorithm so it applies to more general factorization of probability distributions, including (but not limited to) Bayesian network factorizations. Second, we present a forgetting mechanism which reduces the space requirements of RC considerably and then compare such requirmenets with those of variable elimination on a number of realistic networks, showing orders of magnitude improvements in certain cases. Third, we present a version of RC for computing maximum a posteriori hypotheses (MAP), which turns out to be the first MAP algorithm allowing a smooth time-space tradeoff. A key advantage of presented MAP algorithm is that it does not have to start from scratch each time a new query is presented, but can reuse some of its computations across multiple queries, leading to significant savings in ceratain cases.