 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do We Need Weight Decay in Modern Deep Learning?
Oct 06, 2023Weight decay is a broadly used technique for training state-of-the-art deep networks, including large language models. Despite its widespread usage, its role remains poorly understood. In this work, we highlight that the role of weight decay in modern deep learning is different from its regularization effect studied in classical learning theory. For overparameterized deep networks, we show how weight decay modifies the optimization dynamics enhancing the ever-present implicit regularization of SGD via the loss stabilization mechanism. In contrast, for underparameterized large language models trained with nearly online SGD, we describe how weight decay balances the bias-variance tradeoff in stochastic optimization leading to lower training loss. Moreover, we show that weight decay also prevents sudden loss divergences for bfloat16 mixed-precision training which is a crucial tool for LLM training. Overall, we present a unifying perspective from ResNets on vision tasks to LLMs: weight decay is never useful as an explicit regularizer but instead changes the training dynamics in a desirable way. Our code is available at https://github.com/tml-epfl/why-weight-decay.
SGD with large step sizes learns sparse features
Oct 11, 2022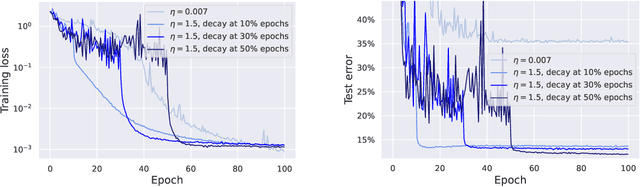

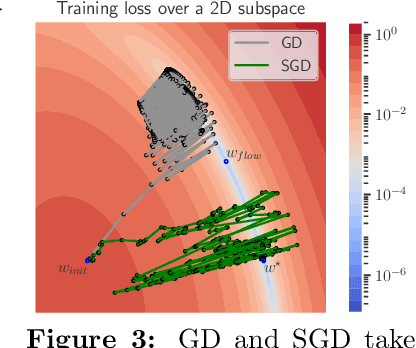

We showcase important features of the dynamics of the Stochastic Gradient Descent (SGD) in the training of neural networks. We present empirical observations that commonly used large step sizes (i) lead the iterates to jump from one side of a valley to the other causing loss stabilization, and (ii) this stabilization induces a hidden stochastic dynamics orthogonal to the bouncing directions that biases it implicitly toward simple predictors. Furthermore, we show empirically that the longer large step sizes keep SGD high in the loss landscape valleys, the better the implicit regularization can operate and find sparse representations. Notably, no explicit regularization is used so that the regularization effect comes solely from the SGD training dynamics influenced by the step size schedule. Therefore, these observations unveil how, through the step size schedules, both gradient and noise drive together the SGD dynamics through the loss landscape of neural networks. We justify these findings theoretically through the study of simple neural network models as well as qualitative arguments inspired from stochastic processes. Finally, this analysis allows to shed a new light on some common practice and observed phenomena when training neural networks. The code of our experiments is available at https://github.com/tml-epfl/sgd-sparse-features.
Accelerated SGD for Non-Strongly-Convex Least Squares
Mar 03, 2022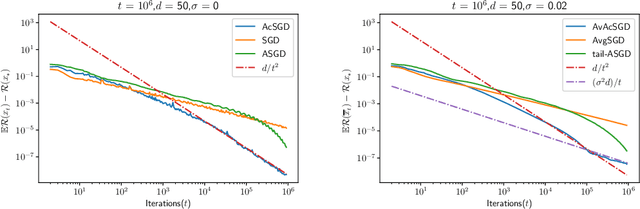
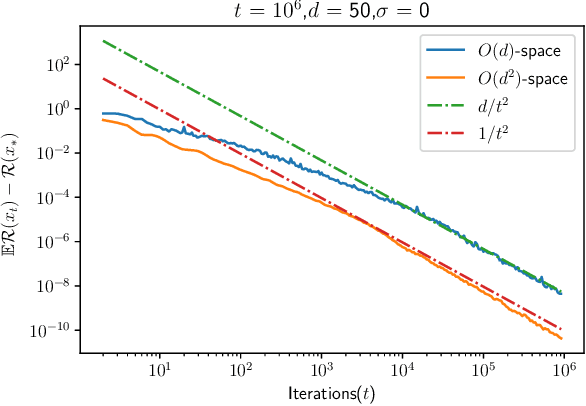
We consider stochastic approximation for the least squares regression problem in the non-strongly convex setting. We present the first practical algorithm that achieves the optimal prediction error rates in terms of dependence on the noise of the problem, as $O(d/t)$ while accelerating the forgetting of the initial conditions to $O(d/t^2)$. Our new algorithm is based on a simple modification of the accelerated gradient descent. We provide convergence results for both the averaged and the last iterate of the algorithm. In order to describe the tightness of these new bounds, we present a matching lower bound in the noiseless setting and thus show the optimality of our algorithm.
Last iterate convergence of SGD for Least-Squares in the Interpolation regime
Feb 05, 2021
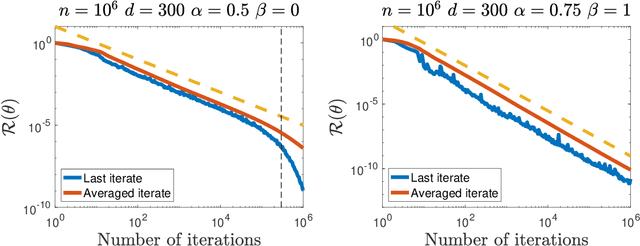


Motivated by the recent successes of neural networks that have the ability to fit the data perfectly and generalize well, we study the noiseless model in the fundamental least-squares setup. We assume that an optimum predictor fits perfectly inputs and outputs $\langle \theta_* , \phi(X) \rangle = Y$, where $\phi(X)$ stands for a possibly infinite dimensional non-linear feature map. To solve this problem, we consider the estimator given by the last iterate of stochastic gradient descent (SGD) with constant step-size. In this context, our contribution is two fold: (i) from a (stochastic) optimization perspective, we exhibit an archetypal problem where we can show explicitly the convergence of SGD final iterate for a non-strongly convex problem with constant step-size whereas usual results use some form of average and (ii) from a statistical perspective, we give explicit non-asymptotic convergence rates in the over-parameterized setting and leverage a fine-grained parameterization of the problem to exhibit polynomial rates that can be faster than $O(1/T)$. The link with reproducing kernel Hilbert spaces is established.