 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Task Synthesis for Visual Programming
Jun 01, 2023



Generative neural models hold great promise in enhancing programming education by synthesizing new content for students. We seek to design neural models that can automatically generate programming tasks for a given specification in the context of visual programming domains. Despite the recent successes of large generative models like GPT-4, our initial results show that these models are ineffective in synthesizing visual programming tasks and struggle with logical and spatial reasoning. We propose a novel neuro-symbolic technique, NeurTaskSyn, that can synthesize programming tasks for a specification given in the form of desired programming concepts exercised by its solution code and constraints on the visual task. NeurTaskSyn has two components: the first component is trained via imitation learning procedure to generate possible solution codes, and the second component is trained via reinforcement learning procedure to guide an underlying symbolic execution engine that generates visual tasks for these codes. We demonstrate the effectiveness of NeurTaskSyn through an extensive empirical evaluation and a qualitative study on reference tasks taken from the Hour of Code: Classic Maze challenge by Code-dot-org and the Intro to Programming with Karel course by CodeHS-dot-com.
Synthesizing a Progression of Subtasks for Block-Based Visual Programming Tasks
May 27, 2023



Block-based visual programming environments play an increasingly important role in introducing computing concepts to K-12 students. In recent years, they have also gained popularity in neuro-symbolic AI, serving as a benchmark to evaluate general problem-solving and logical reasoning skills. The open-ended and conceptual nature of these visual programming tasks make them challenging, both for state-of-the-art AI agents as well as for novice programmers. A natural approach to providing assistance for problem-solving is breaking down a complex task into a progression of simpler subtasks; however, this is not trivial given that the solution codes are typically nested and have non-linear execution behavior. In this paper, we formalize the problem of synthesizing such a progression for a given reference block-based visual programming task. We propose a novel synthesis algorithm that generates a progression of subtasks that are high-quality, well-spaced in terms of their complexity, and solving this progression leads to solving the reference task. We show the utility of our synthesis algorithm in improving the efficacy of AI agents (in this case, neural program synthesizers) for solving tasks in the Karel programming environment. Then, we conduct a user study to demonstrate that our synthesized progression of subtasks can assist a novice programmer in solving tasks in the Hour of Code: Maze Challenge by Code-dot-org.
Proximal Curriculum for Reinforcement Learning Agents
Apr 25, 2023



We consider the problem of curriculum design for reinforcement learning (RL) agents in contextual multi-task settings. Existing techniques on automatic curriculum design typically require domain-specific hyperparameter tuning or have limited theoretical underpinnings. To tackle these limitations, we design our curriculum strategy, ProCuRL, inspired by the pedagogical concept of Zone of Proximal Development (ZPD). ProCuRL captures the intuition that learning progress is maximized when picking tasks that are neither too hard nor too easy for the learner. We mathematically derive ProCuRL by analyzing two simple learning settings. We also present a practical variant of ProCuRL that can be directly integrated with deep RL frameworks with minimal hyperparameter tuning. Experimental results on a variety of domains demonstrate the effectiveness of our curriculum strategy over state-of-the-art baselines in accelerating the training process of deep RL agents.
Adaptive Scaffolding in Block-Based Programming via Synthesizing New Tasks as Pop Quizzes
Mar 28, 2023Block-based programming environments are increasingly used to introduce computing concepts to beginners. However, novice students often struggle in these environments, given the conceptual and open-ended nature of programming tasks. To effectively support a student struggling to solve a given task, it is important to provide adaptive scaffolding that guides the student towards a solution. We introduce a scaffolding framework based on pop quizzes presented as multi-choice programming tasks. To automatically generate these pop quizzes, we propose a novel algorithm, PQuizSyn. More formally, given a reference task with a solution code and the student's current attempt, PQuizSyn synthesizes new tasks for pop quizzes with the following features: (a) Adaptive (i.e., individualized to the student's current attempt), (b) Comprehensible (i.e., easy to comprehend and solve), and (c) Concealing (i.e., do not reveal the solution code). Our algorithm synthesizes these tasks using techniques based on symbolic reasoning and graph-based code representations. We show that our algorithm can generate hundreds of pop quizzes for different student attempts on reference tasks from Hour of Code: Maze Challenge and Karel. We assess the quality of these pop quizzes through expert ratings using an evaluation rubric. Further, we have built an online platform for practicing block-based programming tasks empowered via pop quiz based feedback, and report results from an initial user study.
Implicit Poisoning Attacks in Two-Agent Reinforcement Learning: Adversarial Policies for Training-Time Attacks
Feb 27, 2023



In targeted poisoning attacks, an attacker manipulates an agent-environment interaction to force the agent into adopting a policy of interest, called target policy. Prior work has primarily focused on attacks that modify standard MDP primitives, such as rewards or transitions. In this paper, we study targeted poisoning attacks in a two-agent setting where an attacker implicitly poisons the effective environment of one of the agents by modifying the policy of its peer. We develop an optimization framework for designing optimal attacks, where the cost of the attack measures how much the solution deviates from the assumed default policy of the peer agent. We further study the computational properties of this optimization framework. Focusing on a tabular setting, we show that in contrast to poisoning attacks based on MDP primitives (transitions and (unbounded) rewards), which are always feasible, it is NP-hard to determine the feasibility of implicit poisoning attacks. We provide characterization results that establish sufficient conditions for the feasibility of the attack problem, as well as an upper and a lower bound on the optimal cost of the attack. We propose two algorithmic approaches for finding an optimal adversarial policy: a model-based approach with tabular policies and a model-free approach with parametric/neural policies. We showcase the efficacy of the proposed algorithms through experiments.
Online Reinforcement Learning with Uncertain Episode Lengths
Feb 07, 2023
Existing episodic reinforcement algorithms assume that the length of an episode is fixed across time and known a priori. In this paper, we consider a general framework of episodic reinforcement learning when the length of each episode is drawn from a distribution. We first establish that this problem is equivalent to online reinforcement learning with general discounting where the learner is trying to optimize the expected discounted sum of rewards over an infinite horizon, but where the discounting function is not necessarily geometric. We show that minimizing regret with this new general discounting is equivalent to minimizing regret with uncertain episode lengths. We then design a reinforcement learning algorithm that minimizes regret with general discounting but acts for the setting with uncertain episode lengths. We instantiate our general bound for different types of discounting, including geometric and polynomial discounting. We also show that we can obtain similar regret bounds even when the uncertainty over the episode lengths is unknown, by estimating the unknown distribution over time. Finally, we compare our learning algorithms with existing value-iteration based episodic RL algorithms in a grid-world environment.
Provable Defense against Backdoor Policies in Reinforcement Learning
Nov 18, 2022



We propose a provable defense mechanism against backdoor policies in reinforcement learning under subspace trigger assumption. A backdoor policy is a security threat where an adversary publishes a seemingly well-behaved policy which in fact allows hidden triggers. During deployment, the adversary can modify observed states in a particular way to trigger unexpected actions and harm the agent. We assume the agent does not have the resources to re-train a good policy. Instead, our defense mechanism sanitizes the backdoor policy by projecting observed states to a 'safe subspace', estimated from a small number of interactions with a clean (non-triggered) environment. Our sanitized policy achieves $\epsilon$ approximate optimality in the presence of triggers, provided the number of clean interactions is $O\left(\frac{D}{(1-\gamma)^4 \epsilon^2}\right)$ where $\gamma$ is the discounting factor and $D$ is the dimension of state space. Empirically, we show that our sanitization defense performs well on two Atari game environments.
Specifying and Testing $k$-Safety Properties for Machine-Learning Models
Jun 13, 2022
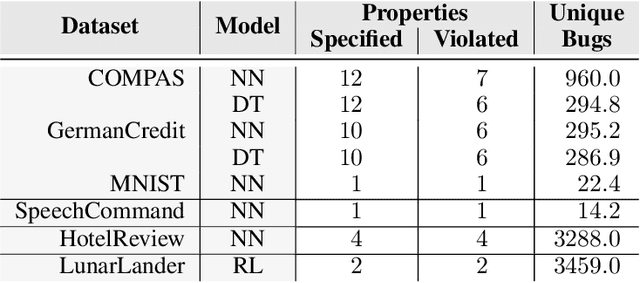

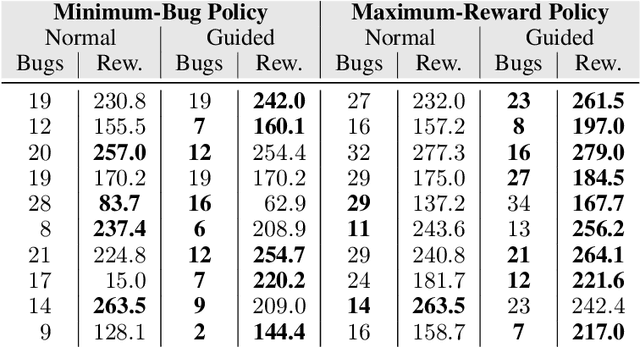
Machine-learning models are becoming increasingly prevalent in our lives, for instance assisting in image-classification or decision-making tasks. Consequently, the reliability of these models is of critical importance and has resulted in the development of numerous approaches for validating and verifying their robustness and fairness. However, beyond such specific properties, it is challenging to specify, let alone check, general functional-correctness expectations from models. In this paper, we take inspiration from specifications used in formal methods, expressing functional-correctness properties by reasoning about $k$ different executions, so-called $k$-safety properties. Considering a credit-screening model of a bank, the expected property that "if a person is denied a loan and their income decreases, they should still be denied the loan" is a 2-safety property. Here, we show the wide applicability of $k$-safety properties for machine-learning models and present the first specification language for expressing them. We also operationalize the language in a framework for automatically validating such properties using metamorphic testing. Our experiments show that our framework is effective in identifying property violations, and that detected bugs could be used to train better models.
Equity and Fairness of Bayesian Knowledge Tracing
May 04, 2022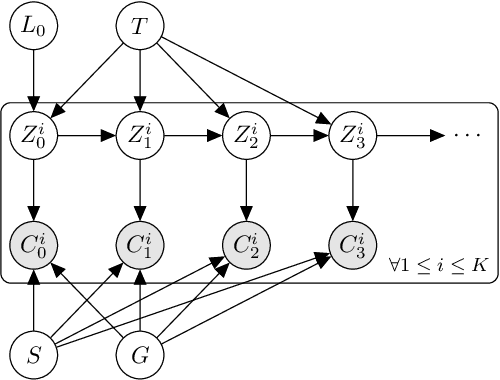
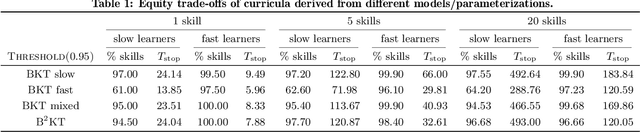
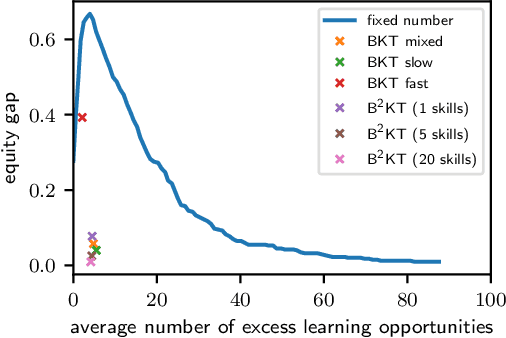

We consider the equity and fairness of curricula derived from Knowledge Tracing models. We begin by defining a unifying notion of an equitable tutoring system as a system that achieves maximum possible knowledge in minimal time for each student interacting with it. Realizing perfect equity requires tutoring systems that can provide individualized curricula per student. In particular, we investigate the design of equitable tutoring systems that derive their curricula from Knowledge Tracing models. We first show that many existing models, including classical Bayesian Knowledge Tracing (BKT) and Deep Knowledge Tracing (DKT), and their derived curricula can fall short of achieving equitable tutoring. To overcome this issue, we then propose a novel model, Bayesian-Bayesian Knowledge Tracing (BBKT), that naturally enables online individualization and, thereby, more equitable tutoring. We demonstrate that curricula derived from our model are more effective and equitable than those derived from classical BKT models. Furthermore, we highlight that improving models with a focus on the fairness of next-step predictions might be insufficient to develop equitable tutoring systems.
From {Solution Synthesis} to {Student Attempt Synthesis} for Block-Based Visual Programming Tasks
May 03, 2022
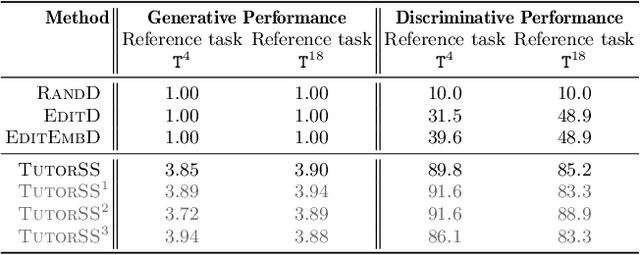


Block-based visual programming environments are increasingly used to introduce computing concepts to beginners. Given that programming tasks are open-ended and conceptual, novice students often struggle when learning in these environments. AI-driven programming tutors hold great promise in automatically assisting struggling students, and need several components to realize this potential. We investigate the crucial component of student modeling, in particular, the ability to automatically infer students' misconceptions for predicting (synthesizing) their behavior. We introduce a novel benchmark, StudentSyn, centered around the following challenge: For a given student, synthesize the student's attempt on a new target task after observing the student's attempt on a fixed reference task. This challenge is akin to that of program synthesis; however, instead of synthesizing a {solution} (i.e., program an expert would write), the goal here is to synthesize a {student attempt} (i.e., program that a given student would write). We first show that human experts (TutorSS) can achieve high performance on the benchmark, whereas simple baselines perform poorly. Then, we develop two neuro/symbolic techniques (NeurSS and SymSS) in a quest to close this gap with TutorSS. We will publicly release the benchmark to facilitate future research in this area.