 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-V2X: Hypernetworks for Estimating Epistemic and Aleatoric Uncertainty in Cooperative Bird's-Eye-View Semantic Segmentation
May 20, 2026Cooperative perception enabled by Vehicle-to-Everything (V2X) communication enhances autonomous driving safety by creating a unified environmental representation through shared sensory data. While recent works have advanced multi-agent fusion for improved perception, uncertainty quantification in such cooperative frameworks remains largely unexplored. This paper introduces Hyper-V2X, a hypernetwork-based framework for estimating both epistemic and aleatoric uncertainties in V2X-based perception. Specifically, we propose a partial weight generation scheme and V2X context embedding module that conditions a Bayesian hypernetwork on fused multi-agent features to generate weight distributions for stochastic Bird's-Eye-View (BEV) segmentation. Unlike existing deterministic BEV models, Hyper-V2X enables efficient uncertainty estimation with little computation overhead. Our approach is architecture-agnostic, and can be seamlessly integrating with modern cooperative backbones such as CoBEVT. Experiments on the OPV2V benchmark demonstrate that Hyper-V2X provides accurate, well-calibrated uncertainty estimates and improves overall perception reliability. Our code and benchmark are publicly available under an open-source license: https://github.com/abhishekjagtap1/Hyper-V2X
Systematic Literature Review on Vehicular Collaborative Perception -- A Computer Vision Perspective
Apr 06, 2025The effectiveness of autonomous vehicles relies on reliable perception capabilities. Despite significant advancements in artificial intelligence and sensor fusion technologies, current single-vehicle perception systems continue to encounter limitations, notably visual occlusions and limited long-range detection capabilities. Collaborative Perception (CP), enabled by Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I) communication, has emerged as a promising solution to mitigate these issues and enhance the reliability of autonomous systems. Beyond advancements in communication, the computer vision community is increasingly focusing on improving vehicular perception through collaborative approaches. However, a systematic literature review that thoroughly examines existing work and reduces subjective bias is still lacking. Such a systematic approach helps identify research gaps, recognize common trends across studies, and inform future research directions. In response, this study follows the PRISMA 2020 guidelines and includes 106 peer-reviewed articles. These publications are analyzed based on modalities, collaboration schemes, and key perception tasks. Through a comparative analysis, this review illustrates how different methods address practical issues such as pose errors, temporal latency, communication constraints, domain shifts, heterogeneity, and adversarial attacks. Furthermore, it critically examines evaluation methodologies, highlighting a misalignment between current metrics and CP's fundamental objectives. By delving into all relevant topics in-depth, this review offers valuable insights into challenges, opportunities, and risks, serving as a reference for advancing research in vehicular collaborative perception.
Automatic Generation of Synthetic Colonoscopy Videos for Domain Randomization
May 20, 2022
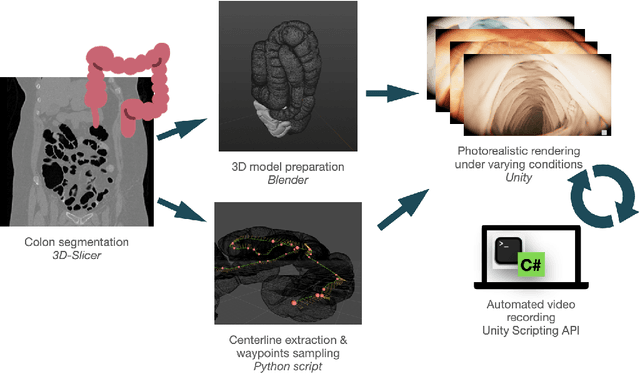
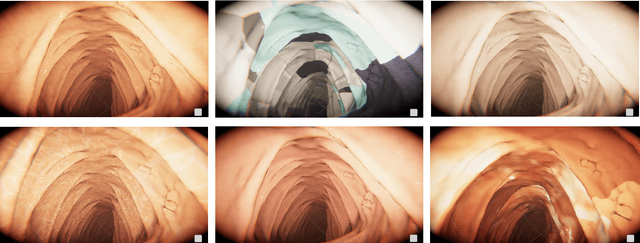
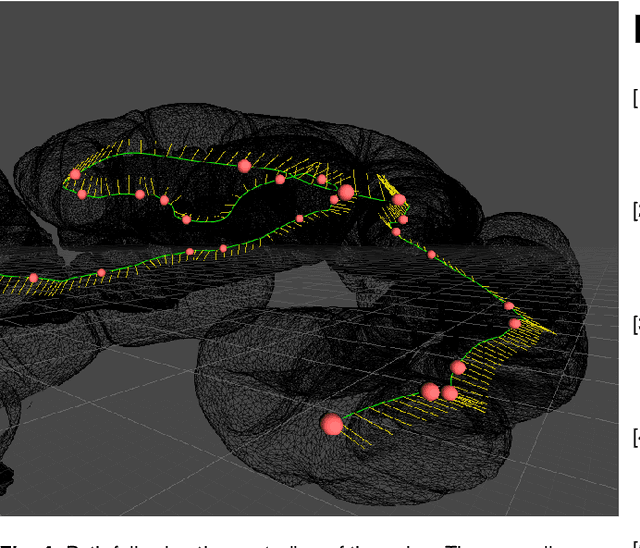
An increasing number of colonoscopic guidance and assistance systems rely on machine learning algorithms which require a large amount of high-quality training data. In order to ensure high performance, the latter has to resemble a substantial portion of possible configurations. This particularly addresses varying anatomy, mucosa appearance and image sensor characteristics which are likely deteriorated by motion blur and inadequate illumination. The limited amount of readily available training data hampers to account for all of these possible configurations which results in reduced generalization capabilities of machine learning models. We propose an exemplary solution for synthesizing colonoscopy videos with substantial appearance and anatomical variations which enables to learn discriminative domain-randomized representations of the interior colon while mimicking real-world settings.