 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving 3D Attention via Triplet Squeeze and Excitation Block
May 09, 2025The emergence of ConvNeXt and its variants has reaffirmed the conceptual and structural suitability of CNN-based models for vision tasks, re-establishing them as key players in image classification in general, and in facial expression recognition (FER) in particular. In this paper, we propose a new set of models that build on these advancements by incorporating a new set of attention mechanisms that combines Triplet attention with Squeeze-and-Excitation (TripSE) in four different variants. We demonstrate the effectiveness of these variants by applying them to the ResNet18, DenseNet and ConvNext architectures to validate their versatility and impact. Our study shows that incorporating a TripSE block in these CNN models boosts their performances, particularly for the ConvNeXt architecture, indicating its utility. We evaluate the proposed mechanisms and associated models across four datasets, namely CIFAR100, ImageNet, FER2013 and AffectNet datasets, where ConvNext with TripSE achieves state-of-the-art results with an accuracy of \textbf{78.27\%} on the popular FER2013 dataset, a new feat for this dataset.
True Online TD-Replan(lambda) Achieving Planning through Replaying
Jan 31, 2025



In this paper, we develop a new planning method that extends the capabilities of the true online TD to allow an agent to efficiently replay all or part of its past experience, online in the sequence that they appear with, either in each step or sparsely according to the usual {\lambda} parameter. In this new method that we call True Online TD-Replan({\lambda}), the {\lambda} parameter plays a new role in specifying the density of the replay process in addition to the usual role of specifying the depth of the target's updates. We demonstrate that, for problems that benefit from experience replay, our new method outperforms true online TD({\lambda}), albeit quadratic in complexity due to its replay capabilities. In addition, we demonstrate that our method outperforms other methods with similar quadratic complexity such as Dyna Planning and TD({\lambda})-Replan algorithms. We test our method on two benchmarking environments, a random walk problem that uses simple binary features and a myoelectric control domain that uses both simple sEMG features and deeply extracted features to showcase its capabilities.
TreeCoders: Trees of Transformers
Nov 11, 2024
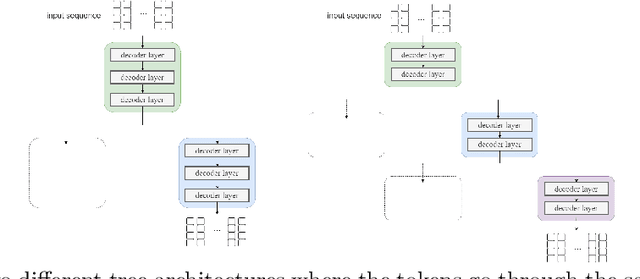

In this paper, we introduce TreeCoders, a novel family of transformer trees. We moved away from traditional linear transformers to complete k-ary trees. Transformer blocks serve as nodes, and generic classifiers learn to select the best child and route the sequence of tokens to a specific leaf. The selectors, moved outside the transformer blocks, allow for the use of a variety of architecture without further modifications. Furthermore, our proposed architecture supports sparse node activation due to the logarithmic complexity of a tree search. We validate our idea by testing a series of decoder-only tree transformers, achieving competitive results across a diverse range of language datasets. Our study demonstrates that the proposed tree transformer model outperforms a size-equivalent linear transformer model 76\% of the time over a wide range of tree architectures. Furthermore, our proposed model naturally lends itself to distributed implementation.
Emotion Recognition with Facial Attention and Objective Activation Functions
Oct 23, 2024



In this paper, we study the effect of introducing channel and spatial attention mechanisms, namely SEN-Net, ECA-Net, and CBAM, to existing CNN vision-based models such as VGGNet, ResNet, and ResNetV2 to perform the Facial Emotion Recognition task. We show that not only attention can significantly improve the performance of these models but also that combining them with a different activation function can further help increase the performance of these models.
Escaping the Forest: Sparse Interpretable Neural Networks for Tabular Data
Oct 23, 2024



Tabular datasets are widely used in scientific disciplines such as biology. While these disciplines have already adopted AI methods to enhance their findings and analysis, they mainly use tree-based methods due to their interpretability. At the same time, artificial neural networks have been shown to offer superior flexibility and depth for rich and complex non-tabular problems, but they are falling behind tree-based models for tabular data in terms of performance and interpretability. Although sparsity has been shown to improve the interpretability and performance of ANN models for complex non-tabular datasets, enforcing sparsity structurally and formatively for tabular data before training the model, remains an open question. To address this question, we establish a method that infuses sparsity in neural networks by utilising attention mechanisms to capture the features' importance in tabular datasets. We show that our models, Sparse TABular NET or sTAB-Net with attention mechanisms, are more effective than tree-based models, reaching the state-of-the-art on biological datasets. They further permit the extraction of insights from these datasets and achieve better performance than post-hoc methods like SHAP.
A Comparison of Baseline Models and a Transformer Network for SOC Prediction in Lithium-Ion Batteries
Oct 22, 2024



Accurately predicting the state of charge of Lithium-ion batteries is essential to the performance of battery management systems of electric vehicles. One of the main reasons for the slow global adoption of electric cars is driving range anxiety. The ability of a battery management system to accurately estimate the state of charge can help alleviate this problem. In this paper, a comparison between data-driven state-of-charge estimation methods is conducted. The paper compares different neural network-based models and common regression models for SOC estimation. These models include several ablated transformer networks, a neural network, a lasso regression model, a linear regression model and a decision tree. Results of various experiments conducted on data obtained from natural driving cycles of the BMW i3 battery show that the decision tree outperformed all other models including the more complex transformer network with self-attention and positional encoding.
Mitigating Vanishing Activations in Deep CapsNets Using Channel Pruning
Oct 22, 2024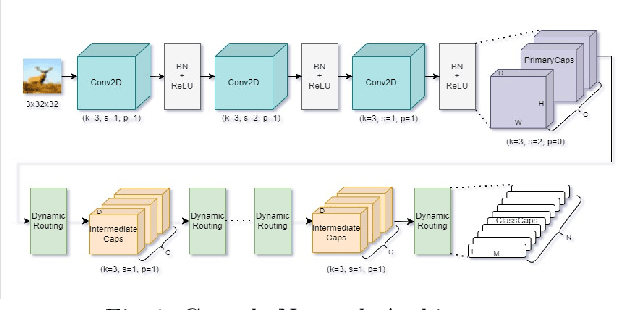
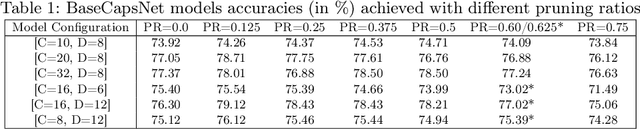


Capsule Networks outperform Convolutional Neural Networks in learning the part-whole relationships with viewpoint invariance, and the credit goes to their multidimensional capsules. It was assumed that increasing the number of capsule layers in the capsule networks would enhance the model performance. However, recent studies found that Capsule Networks lack scalability due to vanishing activations in the capsules of deeper layers. This paper thoroughly investigates the vanishing activation problem in deep Capsule Networks. To analyze this issue and understand how increasing capsule dimensions can facilitate deeper networks, various Capsule Network models are constructed and evaluated with different numbers of capsules, capsule dimensions, and intermediate layers for this paper. Unlike traditional model pruning, which reduces the number of model parameters and expedites model training, this study uses pruning to mitigate the vanishing activations in the deeper capsule layers. In addition, the backbone network and capsule layers are pruned with different pruning ratios to reduce the number of inactive capsules and achieve better model accuracy than the unpruned models.