 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting KNNClassifier Performance with Opposition-Based Data Transformation
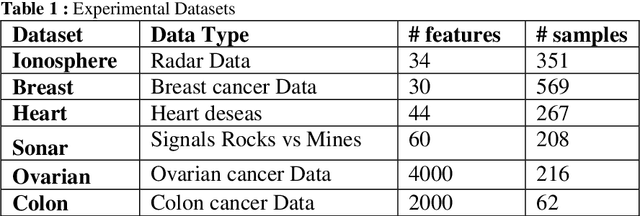
Apr 25, 2025In this paper, we introduce a novel data transformation framework based on Opposition-Based Learning (OBL) to boost the performance of traditional classification algorithms. Originally developed to accelerate convergence in optimization tasks, OBL is leveraged here to generate synthetic opposite samples that enrich the training data and improve decision boundary formation. We explore three OBL variants Global OBL, Class-Wise OBL, and Localized Class-Wise OBL and integrate them with K-Nearest Neighbors (KNN). Extensive experiments conducted on 26 heterogeneous and high-dimensional datasets demonstrate that OBL-enhanced classifiers consistently outperform the basic KNN. These findings underscore the potential of OBL as a lightweight yet powerful data transformation strategy for enhancing classification performance, especially in complex or sparse learning environments.
Boosting Classifier Performance with Opposition-Based Data Transformation
Apr 22, 2025In this paper, we introduce a novel data transformation framework based on Opposition-Based Learning (OBL) to boost the performance of traditional classification algorithms. Originally developed to accelerate convergence in optimization tasks, OBL is leveraged here to generate synthetic opposite samples that replace the acutely training data and improve decision boundary formation. We explore three OBL variants; Global OBL, Class-Wise OBL, and Localized Class-Wise OBL; and integrate them with several widely used classifiers, including K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Logistic Regression (LR), and Decision Tree (DT). Extensive experiments conducted on 26 heterogeneous and high-dimensional datasets demonstrate that OBL-enhanced classifiers consistently outperform their standard counterparts in terms of accuracy and F1-score, frequently achieving near-perfect or perfect classification. Furthermore, OBL contributes to improved computational efficiency, particularly in SVM and LR. These findings underscore the potential of OBL as a lightweight yet powerful data transformation strategy for enhancing classification performance, especially in complex or sparse learning environments.
Trochoid Search Optimization
Dec 21, 2023This paper introduces the Trochoid Search Optimization Algorithm (TSO), a novel metaheuristic leveraging the mathematical properties of trochoid curves. The TSO algorithm employs a unique combination of simultaneous translational and rotational motions inherent in trochoids, fostering a refined equilibrium between explorative and exploitative search capabilities. Notably, TSO consists of two pivotal phases global and local search that collectively contribute to its efficiency and efficacy. Experimental validation demonstrates the TSO algorithm's remarkable performance across various benchmark functions, showcasing its competitive edge in balancing exploration and exploitation within the search space. A distinguishing feature of TSO lies in its simplicity, marked by a minimal requirement for user-defined parameters, making it an accessible yet powerful optimization tool.
CKmeans and FCKmeans : Two deterministic initialization procedures for Kmeans algorithm using a modified crowding distance
May 01, 2023



This paper presents two novel deterministic initialization procedures for K-means clustering based on a modified crowding distance. The procedures, named CKmeans and FCKmeans, use more crowded points as initial centroids. Experimental studies on multiple datasets demonstrate that the proposed approach outperforms Kmeans and Kmeans++ in terms of clustering accuracy. The effectiveness of CKmeans and FCKmeans is attributed to their ability to select better initial centroids based on the modified crowding distance. Overall, the proposed approach provides a promising alternative for improving K-means clustering.
New hard benchmark functions for global optimization
Feb 27, 2022


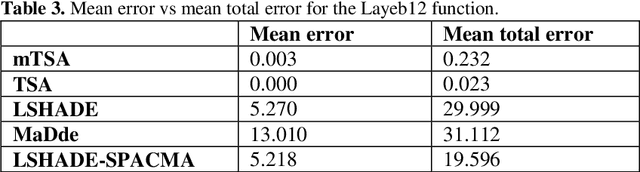
In this paper, we present some new unimodal, multimodal, and noise test functions to assess the performance of global optimization algorithms. All the test functions are multidimensional problems. The 2-dimension landscape of the proposed functions has been graphically presented in 3D space to show their geometry, however these functions are more complicated in dimensions greater than 3. To show the hardness of these functions, we have made an experimental study with some powerful algorithms such as CEC competition winners: LSHADE, MadDe, and LSHADE-SPACMA algorithms. Besides the novel algorithm, Tangent search algorithm (TSA) and its modified Tangent search algorithm (mTSA) were also used in the experimental study. The results found demonstrate the hardness of the proposed functions. The code sources of the proposed test functions are available on Matlab Exchange website. https://www.mathworks.com/matlabcentral/fileexchange/106450-new-hard-benchmark-functions-for-global-optimization?s_tid=srchtitle
Two novel feature selection algorithms based on crowding distance
May 14, 2021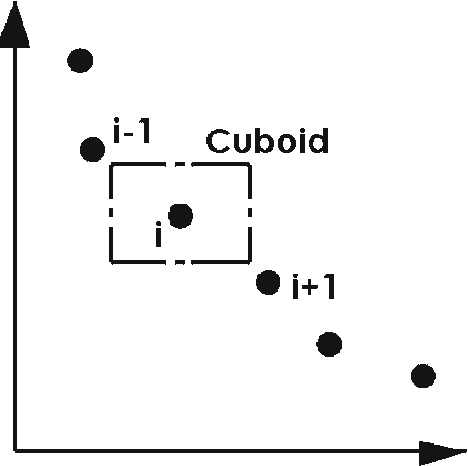

In this paper, two novel algorithms for features selection are proposed. The first one is a filter method while the second is wrapper method. Both the proposed algorithms use the crowding distance used in the multiobjective optimization as a metric in order to sort the features. The less crowded features have great effects on the target attribute (class). The experimental results have shown the effectiveness and the robustness of the proposed algorithms.
The Tangent Search Algorithm for Solving Optimization Problems
Apr 06, 2021



This article proposes a new population-based optimization algorithm called the Tangent Search Algorithm (TSA) to solve optimization problems. The TSA uses a mathematical model based on the tangent function to move a given solution toward a better solution. The tangent flight function has the advantage to balance between the exploitation and the exploration search. Moreover, a novel escape procedure is used to avoid to be trapped in local minima. Besides, an adaptive variable step size is also integrated in this algorithm to enhance the convergence capacity. The performance of TSA is assessed in three classes of tests: classical tests, CEC benchmarks, and engineering optimization problems. Moreover, several studies and metrics have been used to observe the behavior of the proposed TSA. The experimental results show that TSA algorithm is capable to provide very promising and competitive results on most benchmark functions thanks to better balance between exploration and exploitation of the search space. The main characteristics of this new optimization algorithm is its simplicity and efficiency and it requires only a small number of user-defined parameters.