 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Acoustic Features in Arabic Speaker Identification under Noisy Environmental Conditions
Oct 23, 2021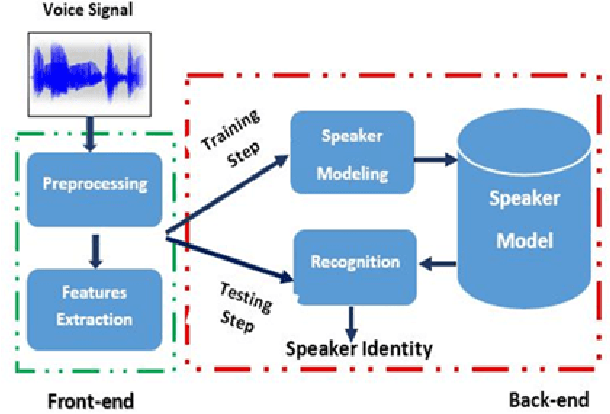
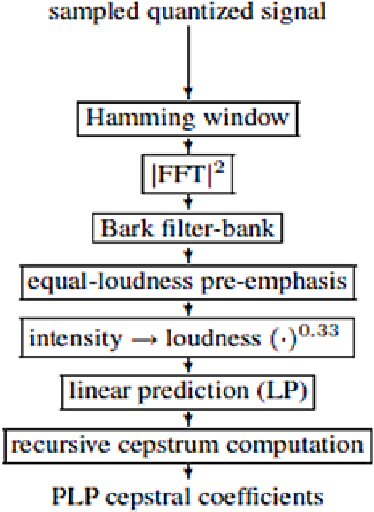

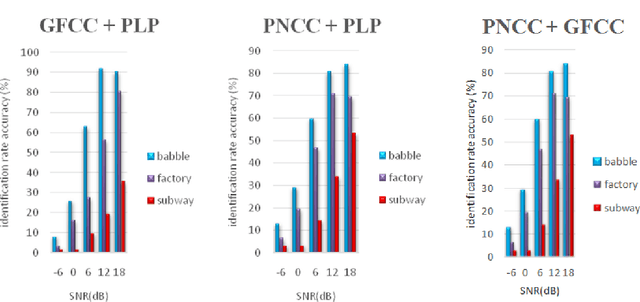
One of the major parts of the voice recognition field is the choice of acoustic features which have to be robust against the variability of the speech signal, mismatched conditions, and noisy environments. Thus, different speech feature extraction techniques have been developed. In this paper, we investigate the robustness of several front-end techniques in Arabic speaker identification. We evaluate five different features in babble, factory and subway conditions at the various signal to noise ratios (SNR). The obtained results showed that two of the auditory feature i.e. gammatone frequency cepstral coefficient (GFCC) and power normalization cepstral coefficients (PNCC), unlike their combination performs substantially better than a conventional speaker features i.e. Mel-frequency cepstral coefficients (MFCC).
Robust Support Vector Machines for Speaker Verification Task
Jun 12, 2013
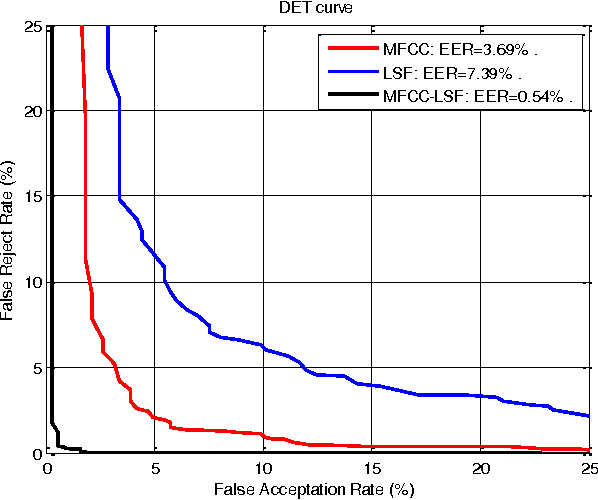

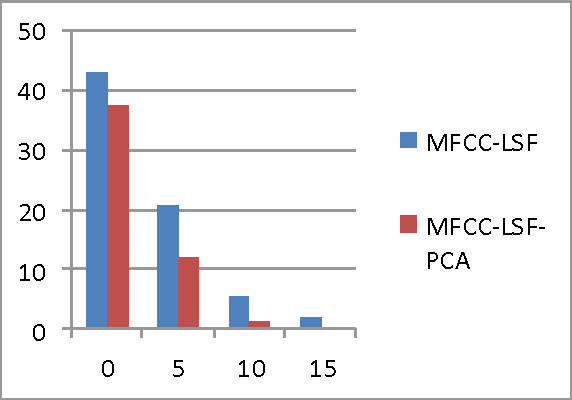
An important step in speaker verification is extracting features that best characterize the speaker voice. This paper investigates a front-end processing that aims at improving the performance of speaker verification based on the SVMs classifier, in text independent mode. This approach combines features based on conventional Mel-cepstral Coefficients (MFCCs) and Line Spectral Frequencies (LSFs) to constitute robust multivariate feature vectors. To reduce the high dimensionality required for training these feature vectors, we use a dimension reduction method called principal component analysis (PCA). In order to evaluate the robustness of these systems, different noisy environments have been used. The obtained results using TIMIT database showed that, using the paradigm that combines these spectral cues leads to a significant improvement in verification accuracy, especially with PCA reduction for low signal-to-noise ratio noisy environment.