 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Dataset Evaluation of Models for Automated Vulnerability Repair
Jun 05, 2025Software vulnerabilities pose significant security threats, requiring effective mitigation. While Automated Program Repair (APR) has advanced in fixing general bugs, vulnerability patching, a security-critical aspect of APR remains underexplored. This study investigates pre-trained language models, CodeBERT and CodeT5, for automated vulnerability patching across six datasets and four languages. We evaluate their accuracy and generalization to unknown vulnerabilities. Results show that while both models face challenges with fragmented or sparse context, CodeBERT performs comparatively better in such scenarios, whereas CodeT5 excels in capturing complex vulnerability patterns. CodeT5 also demonstrates superior scalability. Furthermore, we test fine-tuned models on both in-distribution (trained) and out-of-distribution (unseen) datasets. While fine-tuning improves in-distribution performance, models struggle to generalize to unseen data, highlighting challenges in robust vulnerability detection. This study benchmarks model performance, identifies limitations in generalization, and provides actionable insights to advance automated vulnerability patching for real-world security applications.
Scalable Object Detection for Stylized Objects
Nov 29, 2017
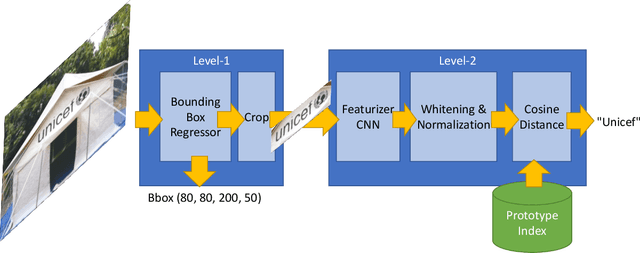
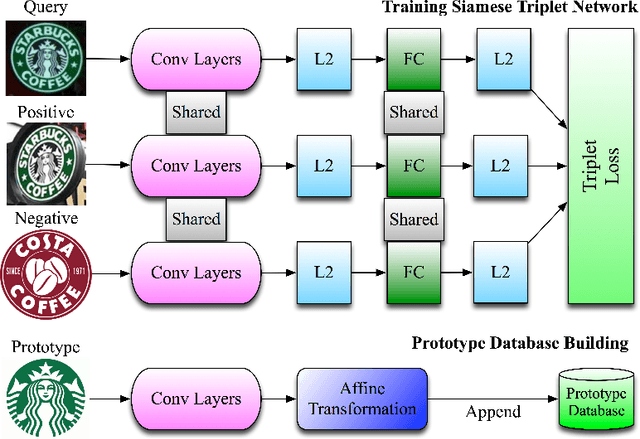

Following recent breakthroughs in convolutional neural networks and monolithic model architectures, state-of-the-art object detection models can reliably and accurately scale into the realm of up to thousands of classes. Things quickly break down, however, when scaling into the tens of thousands, or, eventually, to millions or billions of unique objects. Further, bounding box-trained end-to-end models require extensive training data. Even though - with some tricks using hierarchies - one can sometimes scale up to thousands of classes, the labor requirements for clean image annotations quickly get out of control. In this paper, we present a two-layer object detection method for brand logos and other stylized objects for which prototypical images exist. It can scale to large numbers of unique classes. Our first layer is a CNN from the Single Shot Multibox Detector family of models that learns to propose regions where some stylized object is likely to appear. The contents of a proposed bounding box is then run against an image index that is targeted for the retrieval task at hand. The proposed architecture scales to a large number of object classes, allows to continously add new classes without retraining, and exhibits state-of-the-art quality on a stylized object detection task such as logo recognition.