 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Body Reconstruction from a Single Image via Volumetric Regression
Sep 11, 2018
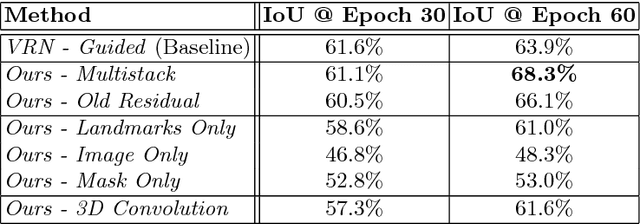

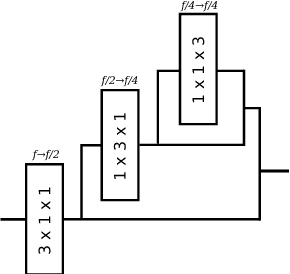
This paper proposes the use of an end-to-end Convolutional Neural Network for direct reconstruction of the 3D geometry of humans via volumetric regression. The proposed method does not require the fitting of a shape model and can be trained to work from a variety of input types, whether it be landmarks, images or segmentation masks. Additionally, non-visible parts, either self-occluded or otherwise, are still reconstructed, which is not the case with depth map regression. We present results that show that our method can handle both pose variation and detailed reconstruction given appropriate datasets for training.
Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression
Sep 08, 2017

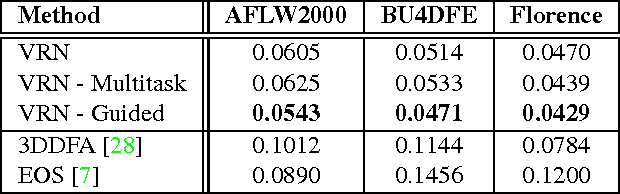
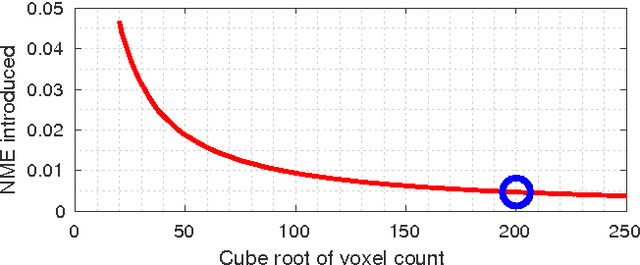
3D face reconstruction is a fundamental Computer Vision problem of extraordinary difficulty. Current systems often assume the availability of multiple facial images (sometimes from the same subject) as input, and must address a number of methodological challenges such as establishing dense correspondences across large facial poses, expressions, and non-uniform illumination. In general these methods require complex and inefficient pipelines for model building and fitting. In this work, we propose to address many of these limitations by training a Convolutional Neural Network (CNN) on an appropriate dataset consisting of 2D images and 3D facial models or scans. Our CNN works with just a single 2D facial image, does not require accurate alignment nor establishes dense correspondence between images, works for arbitrary facial poses and expressions, and can be used to reconstruct the whole 3D facial geometry (including the non-visible parts of the face) bypassing the construction (during training) and fitting (during testing) of a 3D Morphable Model. We achieve this via a simple CNN architecture that performs direct regression of a volumetric representation of the 3D facial geometry from a single 2D image. We also demonstrate how the related task of facial landmark localization can be incorporated into the proposed framework and help improve reconstruction quality, especially for the cases of large poses and facial expressions. Testing code will be made available online, along with pre-trained models http://aaronsplace.co.uk/papers/jackson2017recon