 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances on Affordable Hardware Platforms for Human Demonstration Acquisition in Agricultural Applications
Jun 11, 2025This paper presents advances on the Universal Manipulation Interface (UMI), a low-cost hand-held gripper for robot Learning from Demonstration (LfD), for complex in-the-wild scenarios found in agricultural settings. The focus is on improving the acquisition of suitable samples with minimal additional setup. Firstly, idle times and user's cognitive load are reduced through the extraction of individual samples from a continuous demonstration considering task events. Secondly, reliability on the generation of task sample's trajectories is increased through the combination on-board inertial measurements and external visual marker localization usage using Extended Kalman Filtering (EKF). Results are presented for a fruit harvesting task, outperforming the default pipeline.
* 7 pages, 2 figures
RBED: Reward Based Epsilon Decay
Oct 30, 2019
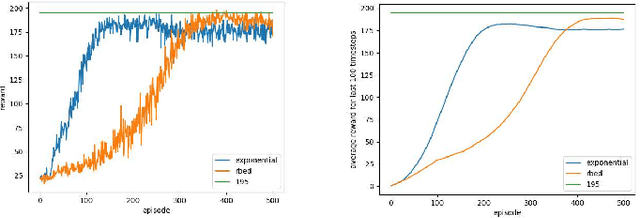
$\varepsilon$-greedy is a policy used to balance exploration and exploitation in many reinforcement learning setting. In cases where the agent uses some on-policy algorithm to learn optimal behaviour, it makes sense for the agent to explore more initially and eventually exploit more as it approaches the target behaviour. This shift from heavy exploration to heavy exploitation can be represented as decay in the $\varepsilon$ value, where $\varepsilon$ depicts the how much an agent is allowed to explore. This paper proposes a new approach to this $\varepsilon$ decay where the decay is based on feedback from the environment. This paper also compares and contrasts one such approach based on rewards and compares it against standard exponential decay. The new approach, in the environments tested, produces more consistent results that on average perform better.