 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynAE: A Framework for Measuring the Quality of Synthetic Data for Tool-Calling Agent Evaluations
May 21, 2026Today, tool-calling agents are commonly evaluated or tested on static datasets of execution traces, including input commands, agent responses, and associated tool calls. However, internal production datasets are often insufficient or unusable for testing; for example, they may contain sensitive or proprietary data, or they may be too sparse to support comprehensive testing (especially pre-deployment). In these settings, practitioners are increasingly replacing or augmenting real datasets with synthetic ones for evaluation purposes. A key challenge is quantifying the relation between these synthetic datasets and the real data. We introduce SynAE, an evaluation framework for assessing how well synthetic benchmarks for multi-turn, tool-calling agents replicate and augment the characteristics of real data trajectories. SynAE assesses the validity, fidelity, and diversity of synthetic data across four metric categories: (i) task instructions and intermediate responses, (ii) tool calls, (iii) final outputs, and (iv) downstream evaluation. We evaluate SynAE using recent agent benchmarks and test common synthetic data failure modes via realistic and controlled generation schemes. SynAE detects fine-grained variations in data validity, fidelity and diversity, and shows that no single metric is sufficient to fully characterize synthetic data quality, motivating a multi-axis evaluation of synthetic data for agent testing. A demo of SynAE is available at https://synae-2026-synae-demo.static.hf.space/index.html, with code at https://github.com/wsqwsq/SynAE.
Generating Expressive and Customizable Evals for Timeseries Data Analysis Agents with AgentFuel
Mar 12, 2026Across many domains (e.g., IoT, observability, telecommunications, cybersecurity), there is an emerging adoption of conversational data analysis agents that enable users to "talk to your data" to extract insights. Such data analysis agents operate on timeseries data models; e.g., measurements from sensors or events monitoring user clicks and actions in product analytics. We evaluate 6 popular data analysis agents (both open-source and proprietary) on domain-specific data and query types, and find that they fail on stateful and incident-specific queries. We observe two key expressivity gaps in existing evals: domain-customized datasets and domain-specific query types. To enable practitioners in such domains to generate customized and expressive evals for such timeseries data agents, we present AgentFuel. AgentFuel helps domain experts quickly create customized evals to perform end-to-end functional tests. We show that AgentFuel's benchmarks expose key directions for improvement in existing data agent frameworks. We also present anecdotal evidence that using AgentFuel can improve agent performance (e.g., with GEPA). AgentFuel benchmarks are available at https://huggingface.co/datasets/RockfishData/TimeSeriesAgentEvals.
Enhanced Membership Inference Attacks against Machine Learning Models
Nov 18, 2021
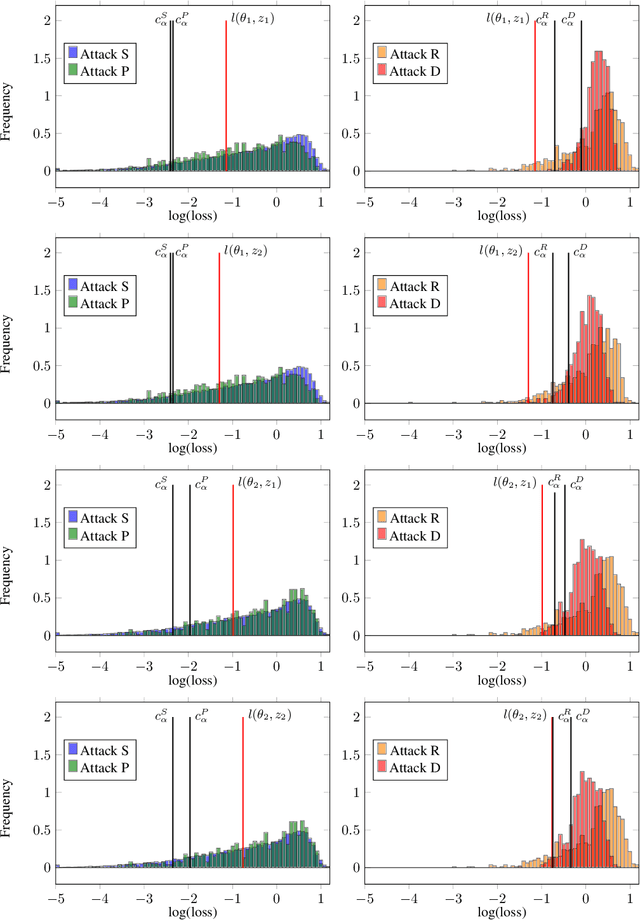
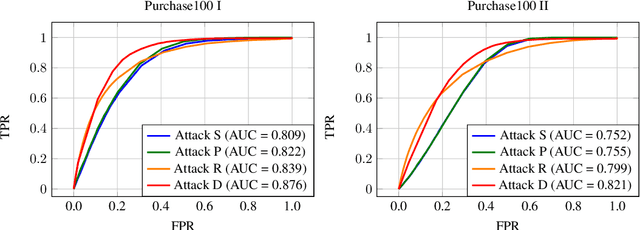

How much does a given trained model leak about each individual data record in its training set? Membership inference attacks are used as an auditing tool to quantify the private information that a model leaks about the individual data points in its training set. Membership inference attacks are influenced by different uncertainties that an attacker has to resolve about training data, the training algorithm, and the underlying data distribution. Thus attack success rates, of many attacks in the literature, do not precisely capture the information leakage of models about their data, as they also reflect other uncertainties that the attack algorithm has. In this paper, we explain the implicit assumptions and also the simplifications made in prior work using the framework of hypothesis testing. We also derive new attack algorithms from the framework that can achieve a high AUC score while also highlighting the different factors that affect their performance. Our algorithms capture a very precise approximation of privacy loss in models, and can be used as a tool to perform an accurate and informed estimation of privacy risk in machine learning models. We provide a thorough empirical evaluation of our attack strategies on various machine learning tasks and benchmark datasets.