 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Technique for Increasing Capacity and Improving Bandwidth in 5G NB-IoT
Aug 29, 2022
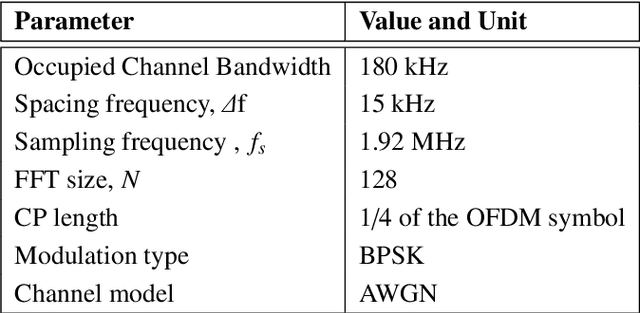
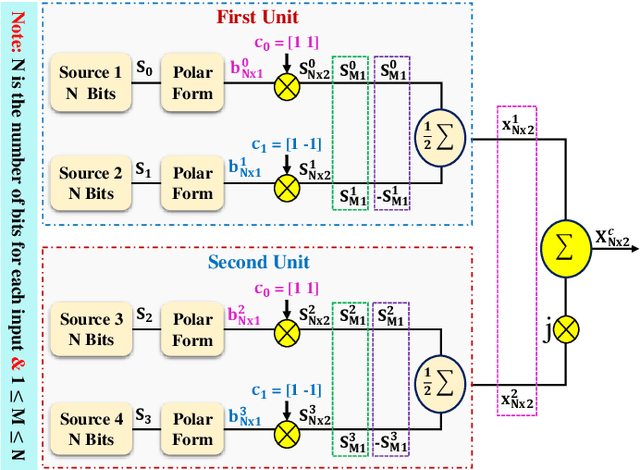

With hundreds of billions of the IoT connected devices, it is important for researchers to create effective resource management approach to satisfy the quality of service (QoS) requirements of 5th generation (5G) and beyond. Furthermore, wireless spectrum is increasingly scarce as demand for wireless services develops, demanding imaginative approaches to increase capacity within a limited spectral resource in order to meet service demands. In this article, the modified symbol time compression (M-STC) technique is suggested to paves the way for 5G networks and beyond to enhance the capacity and throughput. The M-STC method is a compressed signal waveform technique that increases the capacity by compressing the occupied bandwidth without increasing the complexity, losing data throughput or bit error rate (BER) performance. A comparative analysis is provided between the traditional orthogonal frequency division multiplexing (OFDM) system, OFDM using conventional symbol time compression (C-STC-OFDM) and OFDM using the proposed technique (M-STC-OFDM). The simulation results using Matlab-2021a show that the suggested method, M-STC-OFDM, drastically lowers the time needed for each OFDM signal by 75%. As a consequence, the M-STC-OFDM system decreases bandwidth (BW) by 75% when compared to a standard OFDM system (BW_OFDM = 180 kHz and BW_M-STC-OFDM = 45 kHz), while the C-STC-OFDM system reduces BW by 50% (BW_C-STC-OFDM = 90 kHz). Furthermore, using the M-STC-OFDM system reduces peak to average-power-ratio (PAPR) by 2.09 dB when compared to the standard OFDM system and 1.18 dB when compared to C-STC-OFDM with no BER deterioration. Moreover, as compared to the 16QAM-OFDM system, the proposed M-STC-OFDM system reduces the signal-to-noise-ratio (SNR) by 3.8 dB to transmit the same amount of data.
PS-DeVCEM: Pathology-sensitive deep learning model for video capsule endoscopy based on weakly labeled data
Nov 22, 2020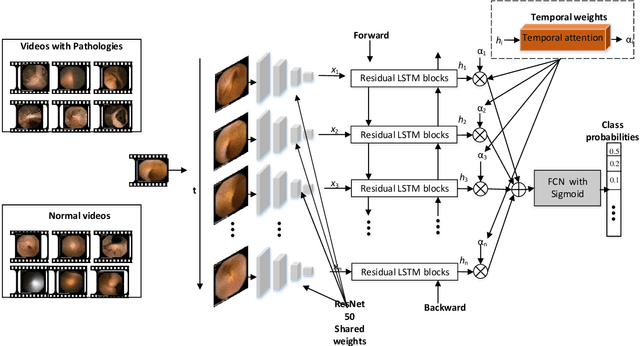

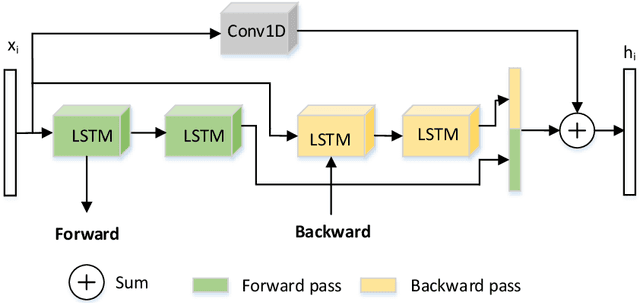
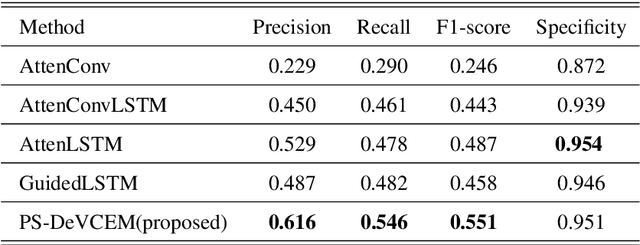
We propose a novel pathology-sensitive deep learning model (PS-DeVCEM) for frame-level anomaly detection and multi-label classification of different colon diseases in video capsule endoscopy (VCE) data. Our proposed model is capable of coping with the key challenge of colon apparent heterogeneity caused by several types of diseases. Our model is driven by attention-based deep multiple instance learning and is trained end-to-end on weakly labeled data using video labels instead of detailed frame-by-frame annotation. The spatial and temporal features are obtained through ResNet50 and residual Long short-term memory (residual LSTM) blocks, respectively. Additionally, the learned temporal attention module provides the importance of each frame to the final label prediction. Moreover, we developed a self-supervision method to maximize the distance between classes of pathologies. We demonstrate through qualitative and quantitative experiments that our proposed weakly supervised learning model gives superior precision and F1-score reaching, 61.6% and 55.1%, as compared to three state-of-the-art video analysis methods respectively. We also show our model's ability to temporally localize frames with pathologies, without frame annotation information during training. Furthermore, we collected and annotated the first and largest VCE dataset with only video labels. The dataset contains 455 short video segments with 28,304 frames and 14 classes of colorectal diseases and artifacts. Dataset and code supporting this publication will be made available on our home page.