 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUzBERT: pretraining a BERT model for Uzbek
Aug 22, 2021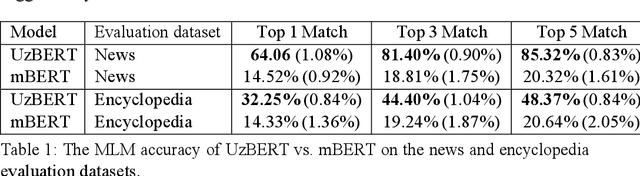
Pretrained language models based on the Transformer architecture have achieved state-of-the-art results in various natural language processing tasks such as part-of-speech tagging, named entity recognition, and question answering. However, no such monolingual model for the Uzbek language is publicly available. In this paper, we introduce UzBERT, a pretrained Uzbek language model based on the BERT architecture. Our model greatly outperforms multilingual BERT on masked language model accuracy. We make the model publicly available under the MIT open-source license.
Uzbek Cyrillic-Latin-Cyrillic Machine Transliteration
Jan 13, 2021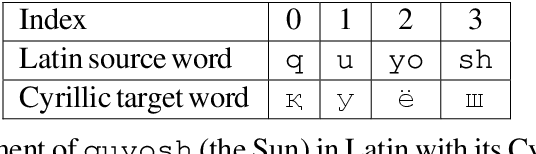


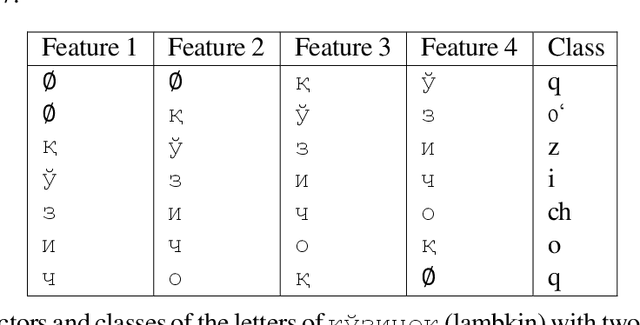
In this paper, we introduce a data-driven approach to transliterating Uzbek dictionary words from the Cyrillic script into the Latin script, and vice versa. We heuristically align characters of words in the source script with sub-strings of the corresponding words in the target script and train a decision tree classifier that learns these alignments. On the test set, our Cyrillic to Latin model achieves a character level micro-averaged F1 score of 0.9992, and our Latin to Cyrillic model achieves the score of 0.9959. Our contribution is a novel method of producing machine transliterated texts for the low-resource Uzbek language.
Development of Word Embeddings for Uzbek Language
Sep 30, 2020In this paper, we share the process of developing word embeddings for the Cyrillic variant of the Uzbek language. The result of our work is the first publicly available set of word vectors trained on the word2vec, GloVe, and fastText algorithms using a high-quality web crawl corpus developed in-house. The developed word embeddings can be used in many natural language processing downstream tasks.