 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCTTA: A Collaborative Approach to Continual Test-Time Adaptation in Federated Learning
May 19, 2025Federated Learning (FL) enables collaborative model training across distributed clients without sharing raw data, making it ideal for privacy-sensitive applications. However, FL models often suffer performance degradation due to distribution shifts between training and deployment. Test-Time Adaptation (TTA) offers a promising solution by allowing models to adapt using only test samples. However, existing TTA methods in FL face challenges such as computational overhead, privacy risks from feature sharing, and scalability concerns due to memory constraints. To address these limitations, we propose Federated Continual Test-Time Adaptation (FedCTTA), a privacy-preserving and computationally efficient framework for federated adaptation. Unlike prior methods that rely on sharing local feature statistics, FedCTTA avoids direct feature exchange by leveraging similarity-aware aggregation based on model output distributions over randomly generated noise samples. This approach ensures adaptive knowledge sharing while preserving data privacy. Furthermore, FedCTTA minimizes the entropy at each client for continual adaptation, enhancing the model's confidence in evolving target distributions. Our method eliminates the need for server-side training during adaptation and maintains a constant memory footprint, making it scalable even as the number of clients or training rounds increases. Extensive experiments show that FedCTTA surpasses existing methods across diverse temporal and spatial heterogeneity scenarios.
Morphological Classification of Radio Galaxies using Semi-Supervised Group Equivariant CNNs
May 31, 2023Out of the estimated few trillion galaxies, only around a million have been detected through radio frequencies, and only a tiny fraction, approximately a thousand, have been manually classified. We have addressed this disparity between labeled and unlabeled images of radio galaxies by employing a semi-supervised learning approach to classify them into the known Fanaroff-Riley Type I (FRI) and Type II (FRII) categories. A Group Equivariant Convolutional Neural Network (G-CNN) was used as an encoder of the state-of-the-art self-supervised methods SimCLR (A Simple Framework for Contrastive Learning of Visual Representations) and BYOL (Bootstrap Your Own Latent). The G-CNN preserves the equivariance for the Euclidean Group E(2), enabling it to effectively learn the representation of globally oriented feature maps. After representation learning, we trained a fully-connected classifier and fine-tuned the trained encoder with labeled data. Our findings demonstrate that our semi-supervised approach outperforms existing state-of-the-art methods across several metrics, including cluster quality, convergence rate, accuracy, precision, recall, and the F1-score. Moreover, statistical significance testing via a t-test revealed that our method surpasses the performance of a fully supervised G-CNN. This study emphasizes the importance of semi-supervised learning in radio galaxy classification, where labeled data are still scarce, but the prospects for discovery are immense.
LULC classification by semantic segmentation of satellite images using FastFCN
Dec 03, 2020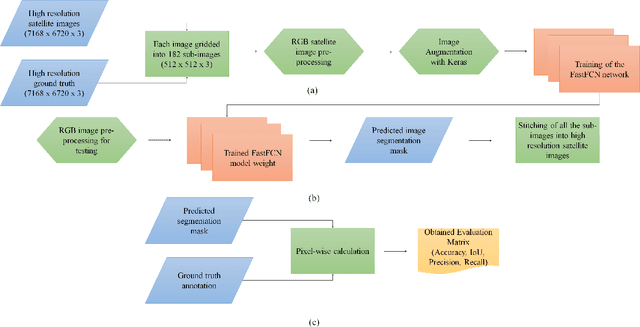
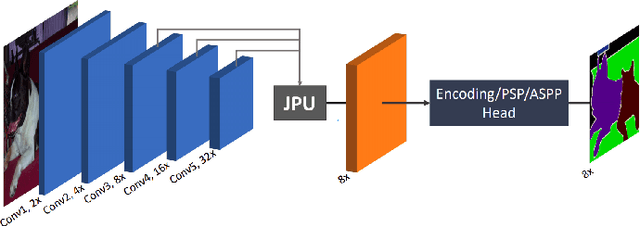

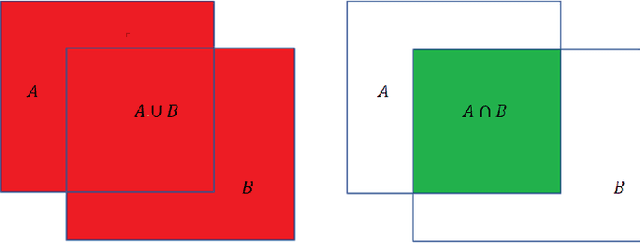
This paper analyses how well a Fast Fully Convolutional Network (FastFCN) semantically segments satellite images and thus classifies Land Use/Land Cover(LULC) classes. Fast-FCN was used on Gaofen-2 Image Dataset (GID-2) to segment them in five different classes: BuiltUp, Meadow, Farmland, Water and Forest. The results showed better accuracy (0.93), precision (0.99), recall (0.98) and mean Intersection over Union (mIoU)(0.97) than other approaches like using FCN-8 or eCognition, a readily available software. We presented a comparison between the results. We propose FastFCN to be both faster and more accurate automated method than other existing methods for LULC classification.