 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Daily News Sentiment on Stock Price Forecasting
Aug 02, 2023Predicting future prices of a stock is an arduous task to perform. However, incorporating additional elements can significantly improve our predictions, rather than relying solely on a stock's historical price data to forecast its future price. Studies have demonstrated that investor sentiment, which is impacted by daily news about the company, can have a significant impact on stock price swings. There are numerous sources from which we can get this information, but they are cluttered with a lot of noise, making it difficult to accurately extract the sentiments from them. Hence the focus of our research is to design an efficient system to capture the sentiments from the news about the NITY50 stocks and investigate how much the financial news sentiment of these stocks are affecting their prices over a period of time. This paper presents a robust data collection and preprocessing framework to create a news database for a timeline of around 3.7 years, consisting of almost half a million news articles. We also capture the stock price information for this timeline and create multiple time series data, that include the sentiment scores from various sections of the article, calculated using different sentiment libraries. Based on this, we fit several LSTM models to forecast the stock prices, with and without using the sentiment scores as features and compare their performances.
Conferences with Internet Web-Casting as Binding Events in a Global Brain: Example Data From Complexity Digest
Mar 22, 2003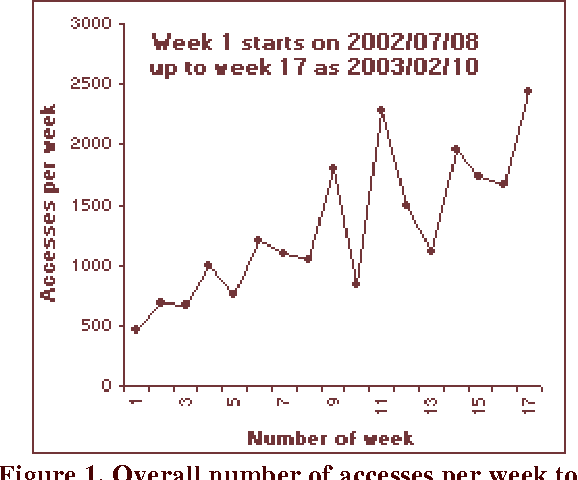
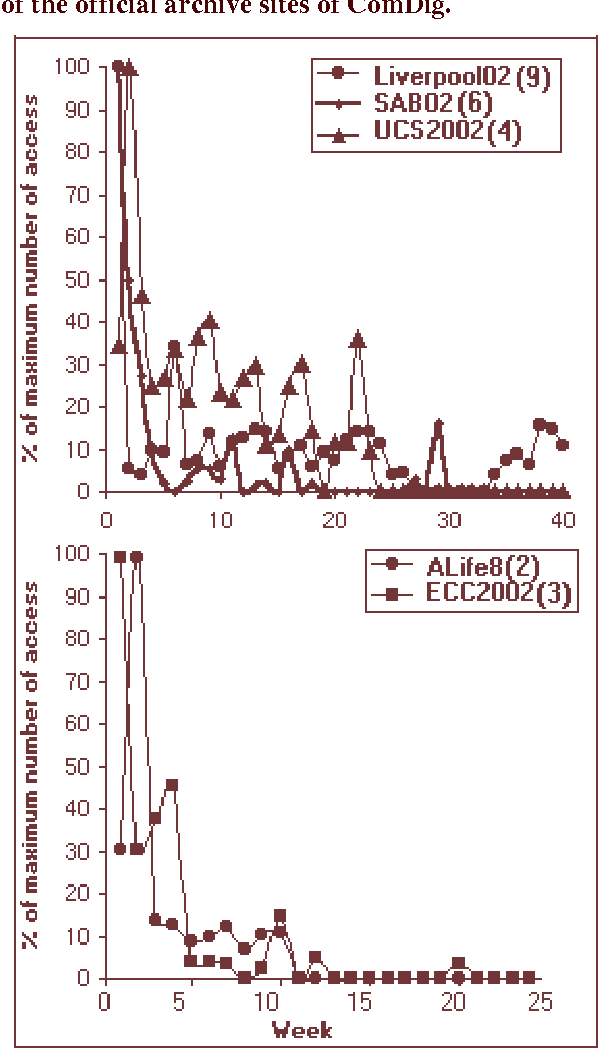
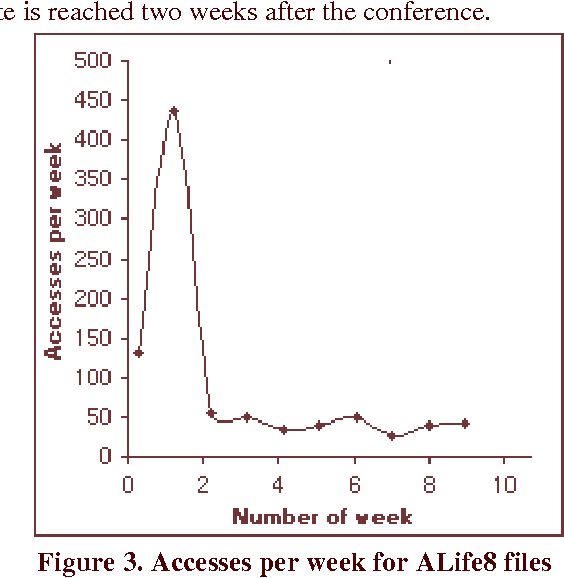
There is likeness of the Internet to human brains which has led to the metaphor of the world-wide computer network as a `Global Brain'. We consider conferences as 'binding events' in the Global Brain that can lead to metacognitive structures on a global scale. One of the critical factors for that phenomenon to happen (similar to the biological brain) are the time-scales characteristic for the information exchange. In an electronic newsletter- the Complexity Digest (ComDig) we include webcasting of audio (mp3) and video (asf) files from international conferences in the weekly ComDig issues. Here we present the time variation of the weekly rate of accesses to the conference files. From those empirical data it appears that the characteristic time-scales related to access of web-casting files is of the order of a few weeks. This is at least an order of magnitude shorter than the characteristic time-scales of peer reviewed publications and conference proceedings. We predict that this observation will have profound implications on the nature of future conference proceedings, presumably in electronic form.
Neural Net Model for Featured Word Extraction
Jun 01, 2002Search engines perform the task of retrieving information related to the user-supplied query words. This task has two parts; one is finding "featured words" which describe an article best and the other is finding a match among these words to user-defined search terms. There are two main independent approaches to achieve this task. The first one, using the concepts of semantics, has been implemented partially. For more details see another paper of Marko et al., 2002. The second approach is reported in this paper. It is a theoretical model based on using Neural Network (NN). Instead of using keywords or reading from the first few lines from papers/articles, the present model gives emphasis on extracting "featured words" from an article. Obviously we propose to exclude prepositions, articles and so on, that is, English words like "of, the, are, so, therefore, " etc. from such a list. A neural model is taken with its nodes pre-assigned energies. Whenever a match is found with featured words and userdefined search words, the node is fired and jumps to a higher energy. This firing continues until the model attains a steady energy level and total energy is now calculated. Clearly, higher match will generate higher energy; so on the basis of total energy, a ranking is done to the article indicating degree of relevance to the user's interest. Another important feature of the proposed model is incorporating a semantic module to refine the search words; like finding association among search words, etc. In this manner, information retrieval can be improved markedly.