 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombined mechanistic and machine learning method for construction of oil reservoir permeability map consistent with well test measurements
Dec 20, 2022We propose a new method for construction of the absolute permeability map consistent with the interpreted results of well logging and well test measurements in oil reservoirs. Nadaraya-Watson kernel regression is used to approximate two-dimensional spatial distribution of the rock permeability. Parameters of the kernel regression are tuned by solving the optimization problem in which, for each well placed in an oil reservoir, we minimize the difference between the actual and predicted values of (i) absolute permeability at the well location (from well logging); (ii) absolute integral permeability of the domain around the well and (iii) skin factor (from well tests). Inverse problem is solved via multiple solutions to forward problems, in which we estimate the integral permeability of reservoir surrounding a well and the skin factor by the surrogate model. The last one is developed using an artificial neural network trained on the physics-based synthetic dataset generated using the procedure comprising the numerical simulation of bottomhole pressure decline curve in reservoir simulator followed by its interpretation using a semi-analytical reservoir model. The developed method for reservoir permeability map construction is applied to the available reservoir model (Egg Model) with highly heterogeneous permeability distribution due to the presence of highly-permeable channels. We showed that the constructed permeability map is hydrodynamically similar to the original one. Numerical simulations of production in the reservoir with constructed and original permeability maps are quantitatively similar in terms of the pore pressure and fluid saturations distribution at the end of the simulation period. Moreover, we obtained an good match between the obtained results of numerical simulations in terms of the flow rates and total volumes of produced oil, water and injected water.
Machine learning on field data for hydraulic fracturing design optimization
Oct 28, 2019
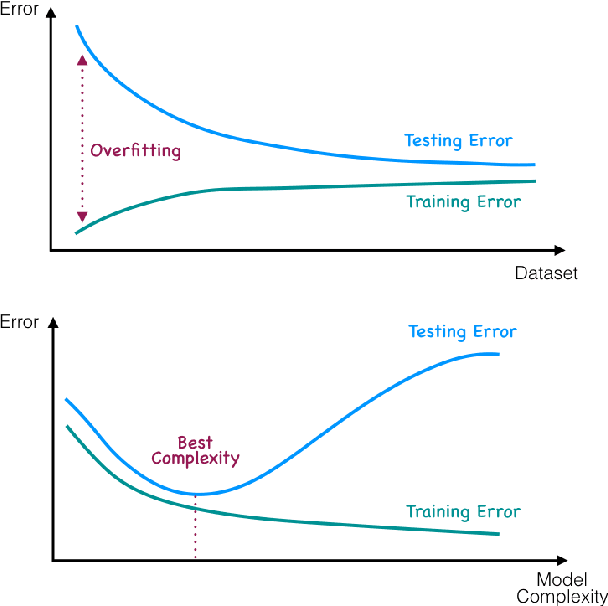
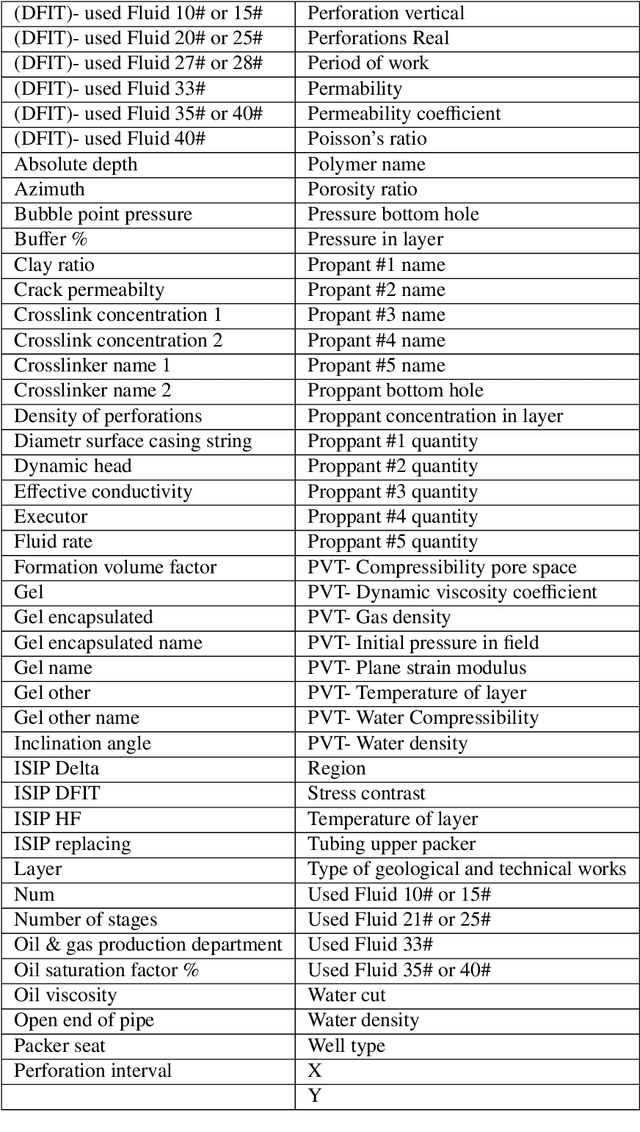
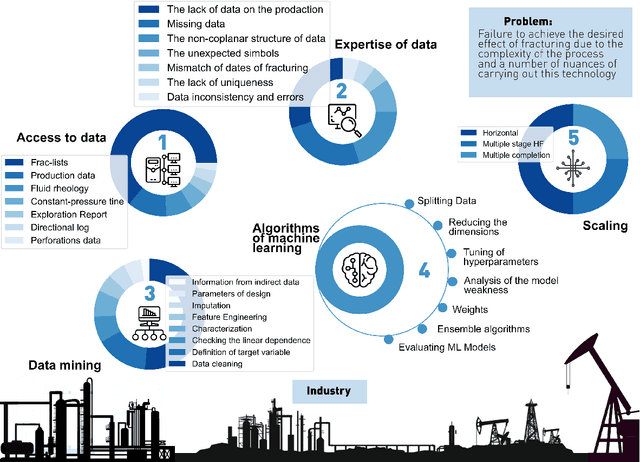
This paper summarizes the efforts of the creation of a digital database of field data from several thousands of multistage hydraulic fracturing jobs on near-horizontal wells from several different oilfields in Western Siberia, Russia. In terms of the number of points (fracturing jobs), the present database is a rare case of an outstandingly representative dataset of thousands of cases, compared to typical databases available in the literature, comprising tens or hundreds of pints at best. The focus is made on data gathering from various sources, data preprocessing and development of the architecture of a database as well as solving fracture design optimization via machine learning. We work with the database composed from reservoir properties, fracturing designs and production data. Both a forward problem (prediction of production rate from fracturing design parameters) and an inverse problem (selecting an optimum set of frac design parameters to maximize production) are considered. A recommendation system is designed for advising a DESC engineer on an optimized fracturing design.