 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndex wiki database: design and experiments
Sep 23, 2008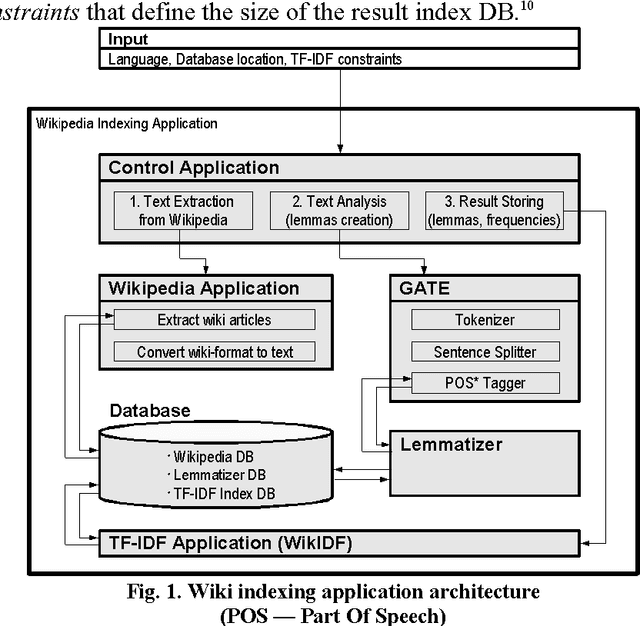
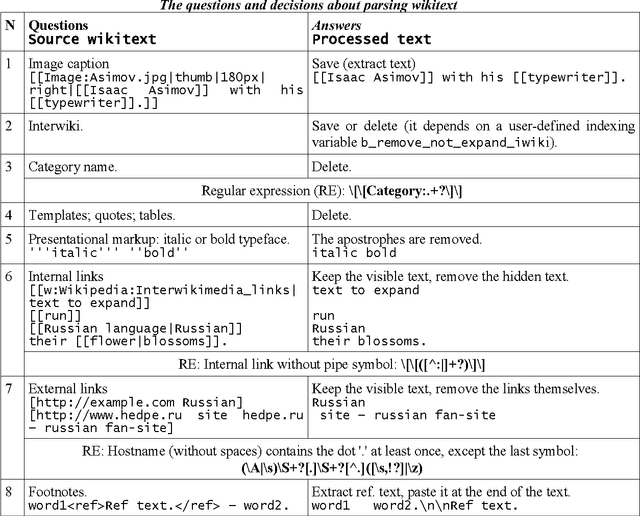
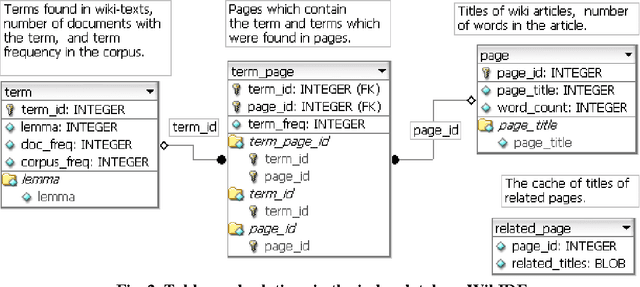

With the fantastic growth of Internet usage, information search in documents of a special type called a "wiki page" that is written using a simple markup language, has become an important problem. This paper describes the software architectural model for indexing wiki texts in three languages (Russian, English, and German) and the interaction between the software components (GATE, Lemmatizer, and Synarcher). The inverted file index database was designed using visual tool DBDesigner. The rules for parsing Wikipedia texts are illustrated by examples. Two index databases of Russian Wikipedia (RW) and Simple English Wikipedia (SEW) are built and compared. The size of RW is by order of magnitude higher than SEW (number of words, lexemes), though the growth rate of number of pages in SEW was found to be 14% higher than in Russian, and the rate of acquisition of new words in SEW lexicon was 7% higher during a period of five months (from September 2007 to February 2008). The Zipf's law was tested with both Russian and Simple Wikipedias. The entire source code of the indexing software and the generated index databases are freely available under GPL (GNU General Public License).
Information filtering based on wiki index database
May 08, 2008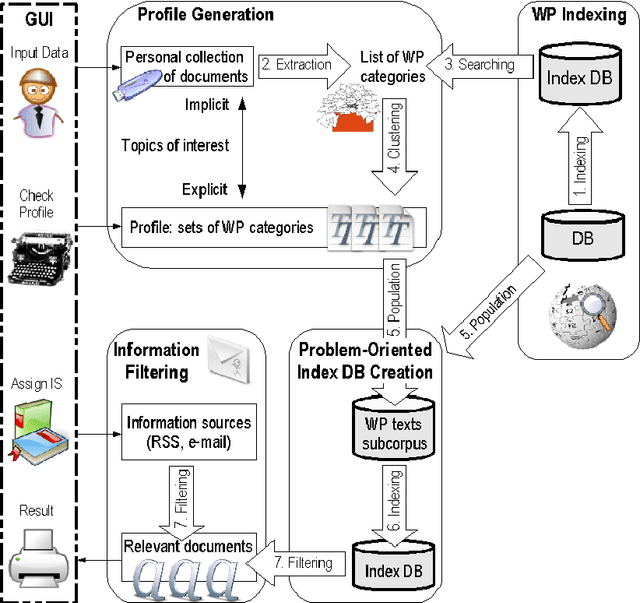

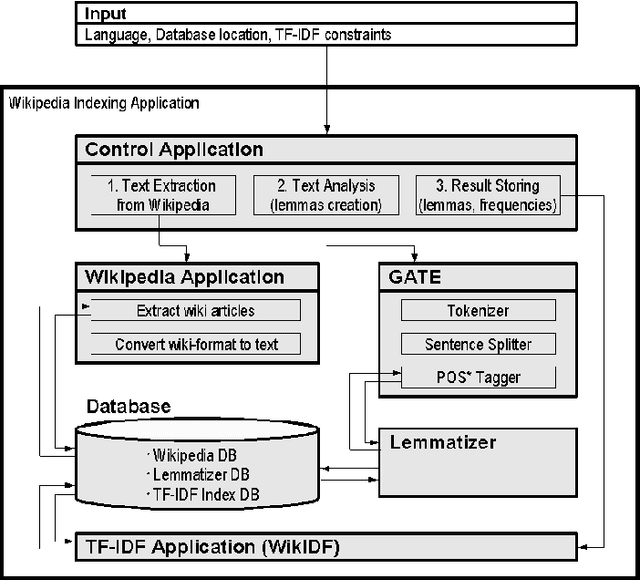
In this paper we present a profile-based approach to information filtering by an analysis of the content of text documents. The Wikipedia index database is created and used to automatically generate the user profile from the user document collection. The problem-oriented Wikipedia subcorpora are created (using knowledge extracted from the user profile) for each topic of user interests. The index databases of these subcorpora are applied to filtering information flow (e.g., mails, news). Thus, the analyzed texts are classified into several topics explicitly presented in the user profile. The paper concentrates on the indexing part of the approach. The architecture of an application implementing the Wikipedia indexing is described. The indexing method is evaluated using the Russian and Simple English Wikipedia.
Evaluation experiments on related terms search in Wikipedia: Information Content and Adapted HITS (In Russian)
Jan 16, 2008The classification of metrics and algorithms search for related terms via WordNet, Roget's Thesaurus, and Wikipedia was extended to include adapted HITS algorithm. Evaluation experiments on Information Content and adapted HITS algorithm are described. The test collection of Russian word pairs with human-assigned similarity judgments is proposed. ----- Klassifikacija metrik i algoritmov poiska semanticheski blizkih slov v tezaurusah WordNet, Rozhe i jenciklopedii Vikipedija rasshirena adaptirovannym HITS algoritmom. S pomow'ju jeksperimentov v Vikipedii oceneny metrika Information Content i adaptirovannyj algoritm HITS. Predlozhen resurs dlja ocenki semanticheskoj blizosti russkih slov.