 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of text coherence based on the cohesion estimation
Nov 11, 2020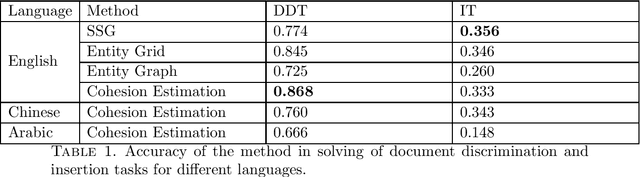
In this paper, a graph-based coherence estimation method based on the cohesion estimation is suggested. Our method uses a graph-based approach to provide a user with an understanding of the evaluation process. Moreover, it can be applied to different languages, therefore, the effectiveness of this method is examined on the set of English, Chinese, and Arabic texts.
Method of the coherence evaluation of Ukrainian text
Oct 31, 2020Due to the growing role of the SEO technologies, it is necessary to perform an automated analysis of the article's quality. Such approach helps both to return the most intelligible pages for the user's query and to raise the web sites positions to the top of query results. An automated assessment of a coherence is a part of the complex analysis of the text. In this article, main methods for text coherence measurements for Ukrainian language are analyzed. Expediency of using the semantic similarity graph method in comparison with other methods are explained. It is suggested the improvement of that method by the pre-training of the neural network for vector representations of sentences. Experimental examination of the original method and its modifications is made. Training and examination procedures are made on the corpus of Ukrainian texts, which were previously retrieved from abstracts and full texts of Ukrainian scientific articles. The testing procedure is implemented by performing of two typical tasks for the text coherence assessment: document discrimination task and insertion task. Accordingly to the analysis it is defined the most effective combination of method's modification and its parameter for the measurement of the text coherence.
* 16 pages, in Ukrainian, 5 figures
Method of noun phrase detection in Ukrainian texts
Oct 22, 2020Introduction. The area of natural language processing considers AI-complete tasks that cannot be solved using traditional algorithmic actions. Such tasks are commonly implemented with the usage of machine learning methodology and means of computer linguistics. One of the preprocessing tasks of a text is the search of noun phrases. The accuracy of this task has implications for the effectiveness of many other tasks in the area of natural language processing. In spite of the active development of research in the area of natural language processing, the investigation of the search for noun phrases within Ukrainian texts are still at an early stage. Results. The different methods of noun phrases detection have been analyzed. The expediency of the representation of sentences as a tree structure has been justified. The key disadvantage of many methods of noun phrase detection is the severe dependence of the effectiveness of their detection from the features of a certain language. Taking into account the unified format of sentence processing and the availability of the trained model for the building of sentence trees for Ukrainian texts, the Universal Dependency model has been chosen. The complex method of noun phrases detection in Ukrainian texts utilizing Universal Dependencies means and named-entity recognition model has been suggested. Experimental verification of the effectiveness of the suggested method on the corpus of Ukrainian news has been performed. Different metrics of method accuracy have been calculated. Conclusions. The results obtained can indicate that the suggested method can be used to find noun phrases in Ukrainian texts. An accuracy increase of the method can be made with the usage of appropriate named-entity recognition models according to a subject area.
* 25 pages, in Ukrainian, 5 figures, 2 tables