 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptCaps -- a Distilled Concept Dataset for Interpretability in Music Models
Jan 20, 2026Concept-based interpretability methods like TCAV require clean, well-separated positive and negative examples for each concept. Existing music datasets lack this structure: tags are sparse, noisy, or ill-defined. We introduce ConceptCaps, a dataset of 23k music-caption-audio triplets with explicit labels from a 200-attribute taxonomy. Our pipeline separates semantic modeling from text generation: a VAE learns plausible attribute co-occurrence patterns, a fine-tuned LLM converts attribute lists into professional descriptions, and MusicGen synthesizes corresponding audio. This separation improves coherence and controllability over end-to-end approaches. We validate the dataset through audio-text alignment (CLAP), linguistic quality metrics (BERTScore, MAUVE), and TCAV analysis confirming that concept probes recover musically meaningful patterns. Dataset and code are available online.
Deep Memory Update
Jun 17, 2021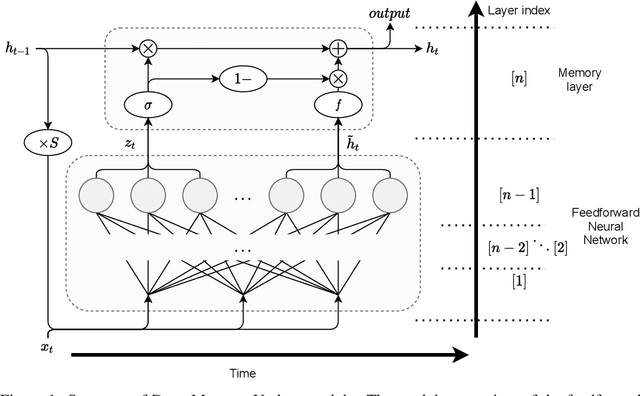
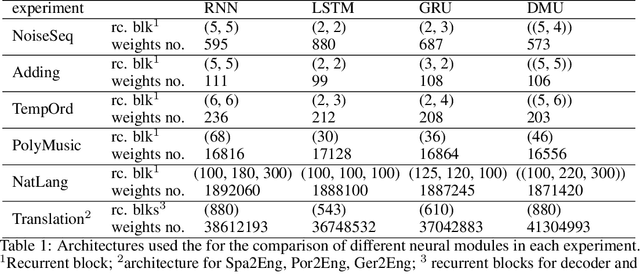
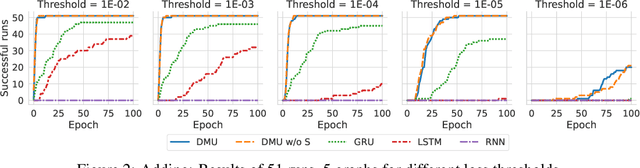
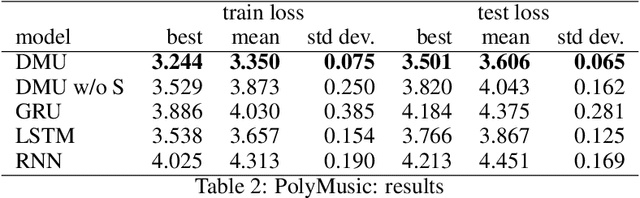
Recurrent neural networks are key tools for sequential data processing. Existing architectures support only a limited class of operations that these networks can apply to their memory state. In this paper, we address this issue and introduce a recurrent neural module called Deep Memory Update (DMU). This module is an alternative to well-established LSTM and GRU. However, it uses a universal function approximator to process its lagged memory state. In addition, the module normalizes the lagged memory to avoid gradient exploding or vanishing in backpropagation through time. The subnetwork that transforms the memory state of DMU can be arbitrary. Experimental results presented here confirm that the previously mentioned properties of the network allow it to compete with and often outperform state-of-the-art architectures such as LSTM and GRU.