 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new method for determining Wasserstein 1 optimal transport maps from Kantorovich potentials, with deep learning applications
Nov 02, 2022Wasserstein 1 optimal transport maps provide a natural correspondence between points from two probability distributions, $\mu$ and $\nu$, which is useful in many applications. Available algorithms for computing these maps do not appear to scale well to high dimensions. In deep learning applications, efficient algorithms have been developed for approximating solutions of the dual problem, known as Kantorovich potentials, using neural networks (e.g. [Gulrajani et al., 2017]). Importantly, such algorithms work well in high dimensions. In this paper we present an approach towards computing Wasserstein 1 optimal transport maps that relies only on Kantorovich potentials. In general, a Wasserstein 1 optimal transport map is not unique and is not computable from a potential alone. Our main result is to prove that if $\mu$ has a density and $\nu$ is supported on a submanifold of codimension at least 2, an optimal transport map is unique and can be written explicitly in terms of a potential. These assumptions are natural in many image processing contexts and other applications. When the Kantorovich potential is only known approximately, our result motivates an iterative procedure wherein data is moved in optimal directions and with the correct average displacement. Since this provides an approach for transforming one distribution to another, it can be used as a multipurpose algorithm for various transport problems; we demonstrate through several proof of concept experiments that this algorithm successfully performs various imaging tasks, such as denoising, generation, translation and deblurring, which normally require specialized techniques.
Trust the Critics: Generatorless and Multipurpose WGANs with Initial Convergence Guarantees
Nov 30, 2021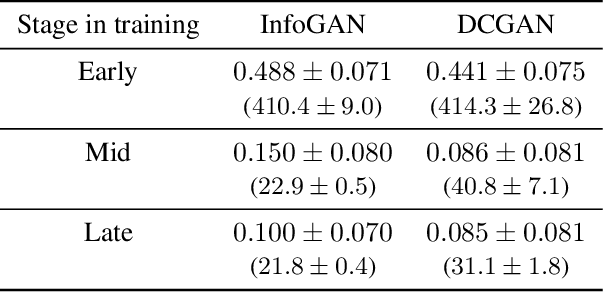

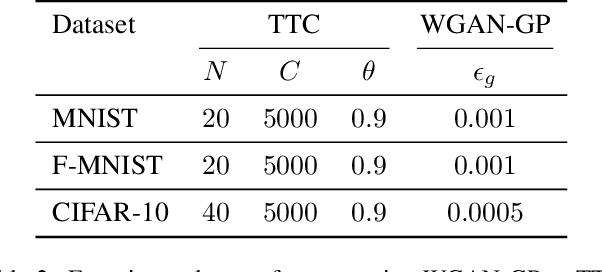

Inspired by ideas from optimal transport theory we present Trust the Critics (TTC), a new algorithm for generative modelling. This algorithm eliminates the trainable generator from a Wasserstein GAN; instead, it iteratively modifies the source data using gradient descent on a sequence of trained critic networks. This is motivated in part by the misalignment which we observed between the optimal transport directions provided by the gradients of the critic and the directions in which data points actually move when parametrized by a trainable generator. Previous work has arrived at similar ideas from different viewpoints, but our basis in optimal transport theory motivates the choice of an adaptive step size which greatly accelerates convergence compared to a constant step size. Using this step size rule, we prove an initial geometric convergence rate in the case of source distributions with densities. These convergence rates cease to apply only when a non-negligible set of generated data is essentially indistinguishable from real data. Resolving the misalignment issue improves performance, which we demonstrate in experiments that show that given a fixed number of training epochs, TTC produces higher quality images than a comparable WGAN, albeit at increased memory requirements. In addition, TTC provides an iterative formula for the transformed density, which traditional WGANs do not. Finally, TTC can be applied to map any source distribution onto any target; we demonstrate through experiments that TTC can obtain competitive performance in image generation, translation, and denoising without dedicated algorithms.